I mitt tidigare inlägg om inkrementell statistik, en ny funktion i SQL Server 2014, visade jag hur de kan hjälpa till att minska underhållsuppdragens varaktighet. Detta beror på att statistik kan uppdateras på partitionsnivå och ändringarna slås samman i tabellens huvudhistogram. Jag noterade också att frågeoptimeraren inte använder den statistiken på partitionsnivå när man genererar frågeplaner, vilket kan vara något som folk förväntade sig. Det finns ingen dokumentation som anger att inkrementell statistik kommer, eller inte, att användas av Query Optimizer. Så hur vet du det? Du måste testa det. :-)
Inställningen
Inställningen för detta test kommer att likna den i förra inlägget, men med mindre data. Observera att standardstorlekarna är mindre för datafilerna, och skriptet läses bara in i några miljoner rader med data:
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', --everything in 2011 '20120101', --everything in 2012 '20130101', --everything in 2013 '20140101', --everything in 2014 '20150101' --everything in 2015 ); GO CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
När vi skapar det klustrade indexet för dbo.Orders skapar vi det utan STATISTICS_INCREMENTAL alternativet aktiverat, så vi börjar med en traditionell partitionerad tabell utan inkrementell statistik:
ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ([OrderDate], [PurchaseOrderID]) ON [OrderDateRangePScheme] ([OrderDate]);
Därefter laddar vi in cirka 4 miljoner rader, vilket tar knappt en minut på min maskin:
SET NOCOUNT ON; DECLARE @Loops SMALLINT = 0; DECLARE @Increment INT = 3000; WHILE @Loops < 1000 BEGIN INSERT [dbo].[Orders] ([PurchaseOrderID] ,[EmployeeID] ,[VendorID] ,[TaxAmt] ,[Freight] ,[SubTotal] ,[Status] ,[RevisionNumber] ,[ModifiedDate] ,[ShipMethodID] ,[ShipDate] ,[OrderDate] ,[TotalDue] ) SELECT [PurchaseOrderID] + @Increment , [EmployeeID] , [VendorID] , [TaxAmt] , [Freight] , [SubTotal] , [Status] , [RevisionNumber] , [ModifiedDate] , [ShipMethodID] , DATEADD(DAY, 365, [ShipDate]) , DATEADD(DAY, 365, [OrderDate]) , [TotalDue] + 365 FROM [Purchasing].[PurchaseOrderHeader]; CHECKPOINT; SET @Loops = @Loops + 1; SET @Increment = @Increment + 5000; END
Efter dataladdningen kommer vi att uppdatera statistiken med en FULLSCAN (så att vi kan skapa ett konsekvent-som-möjligt histogram för tester) och sedan verifiera vilken data vi har i varje partition:
UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN; SELECT $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number] , MIN([o].[OrderDate]) AS [Min_Order_Date] , MAX([o].[OrderDate]) AS [Max_Order_Date] , COUNT(*) AS [Rows_In_Partition] FROM [dbo].[Orders] AS [o] GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) ORDER BY [Partition Number];
 Data i varje partition efter dataladdning
Data i varje partition efter dataladdning
Det mesta av data finns i 2015-partitionen, men det finns även data för 2012, 2013 och 2014. Och om vi kontrollerar utdata från den odokumenterade DMV sys.dm_db_stats_properties_internal , kan vi se att det inte finns någon partitionsnivåstatistik:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 sys.dm_db_stats_properties_internal output som endast visar en statistik för dbo.Orders
sys.dm_db_stats_properties_internal output som endast visar en statistik för dbo.Orders
Testet
Testning kräver en enkel fråga som vi kan använda för att verifiera att partitionseliminering sker, och även kontrollera uppskattningar baserade på statistik. Frågan returnerar ingen data, men det spelar ingen roll, vi är intresserade av vad optimeraren tänkte det skulle återkomma, baserat på statistik:
SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
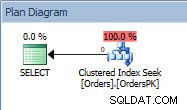 Frågeplan för SELECT-satsen
Frågeplan för SELECT-satsen
Planen har en Clustered Index Seek, och om vi kontrollerar egenskaperna ser vi att den uppskattade 4000 rader och åtkomst till partition 5, som innehåller 2014-data.
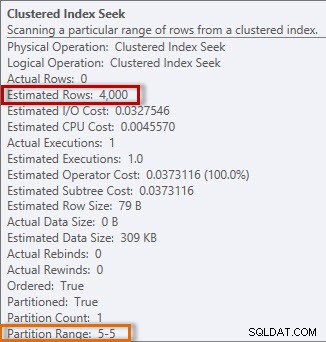 Uppskattad och faktisk information från Clustered Index Seek
Uppskattad och faktisk information från Clustered Index Seek
Om vi tittar på histogrammet för tabellen dbo.Orders, specifikt i området för april 2014-data, ser vi att det inte finns något steg för 2014-04-01, så optimeraren uppskattar antalet rader för det datumet med hjälp av steget för 2014-04-24, där AVG_RANGE_ROWS är 4000 (för vilket värde som helst mellan 2014-02-14 och 2014-04-23 inklusive, uppskattar optimeraren att 4000 rader kommer att returneras).
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
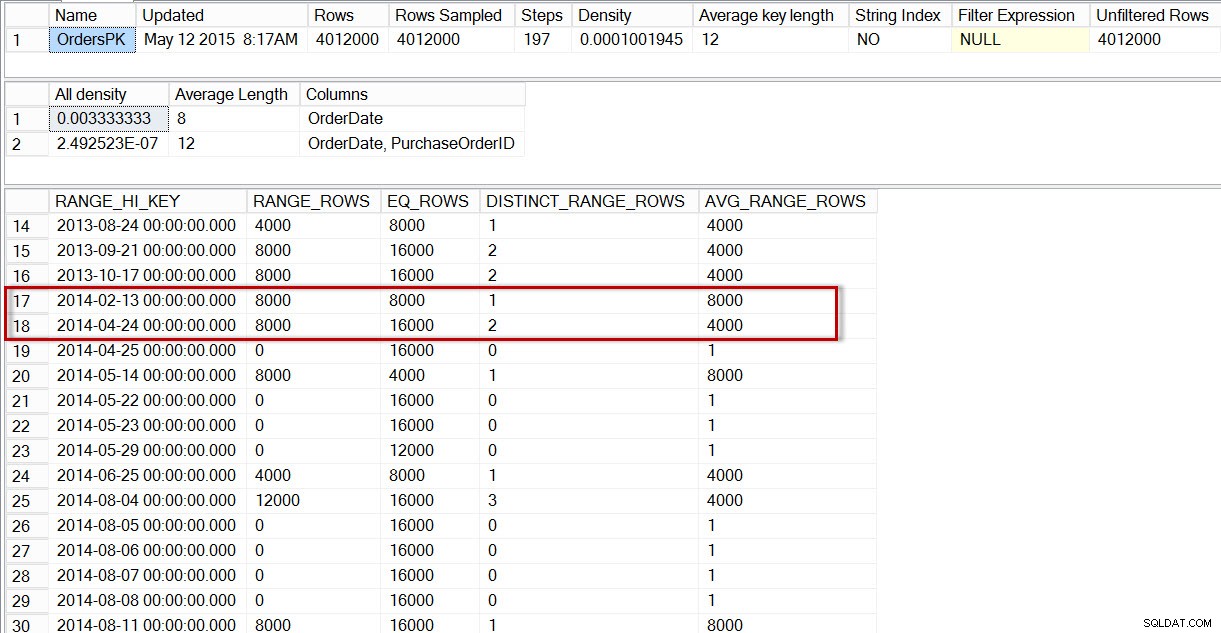 Distribution i dbo.Orders-histogrammet
Distribution i dbo.Orders-histogrammet
Uppskattningen och planen är helt förväntade. Låt oss aktivera inkrementell statistik och se vad vi får.
ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON); GO UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN;
Om vi kör vår fråga igen mot sys.dm_db_stats_properties_internal , kan vi se den inkrementella statistiken:
 sys.dm_db_stats_properties_internal visar inkrementell statistikinformation
sys.dm_db_stats_properties_internal visar inkrementell statistikinformation
Låt oss nu köra vår fråga igen dbo.Orders, och vi kör DBCC FREEPROCCACHE först för att helt säkerställa att planen inte återanvänds:
DBCC FREEPROCCACHE; GO SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
Vi får samma plan och samma uppskattning:
Frågeplan för SELECT-satsen
Uppskattad och faktisk information från Clustered Index Seek
Om vi kontrollerar huvudhistogrammet för dbo.Orders ser vi nästan samma histogram som tidigare:
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
 Histogram för dbo.Orders, efter aktivering av inkrementell statistik
Histogram för dbo.Orders, efter aktivering av inkrementell statistik
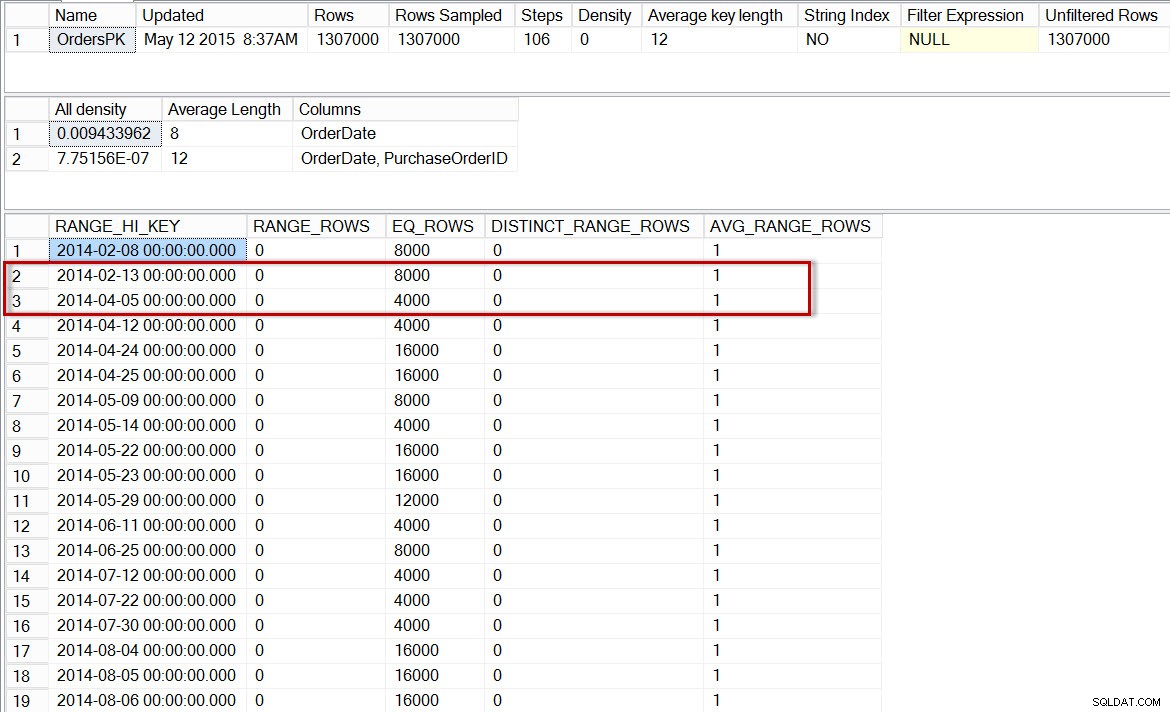
Nu, låt oss kontrollera histogrammet för partitionen med 2014-data (vi kan göra detta med odokumenterad spårningsflagga 2309, som tillåter att ett partitionsnummer anges som ett ytterligare argument till DBCC SHOW_STATISTICS ):
DBCC TRACEON(2309);
GO
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK', 6);
Histogram för 2014 års partition av dbo.Orders, efter aktivering av inkrementell statistik
Här ser vi att det återigen inte finns något steg för 2014-04-01, men det finns 0 RANGE_ROWS mellan 2014-02-13 och 2014-04-05, med en AVG_RANGE_ROWS av 1. Om optimeraren använde histogrammet för partitionsnivåstatistiken skulle uppskattningen för antalet rader för 2014-04-01 vara 1.
Obs:Partitionen som identifieras som använd i frågeplanen är 5, men du kommer att märka att DBCC SHOW_STATISTICS uttalande referenser partition 6. Antagandet är en inkonsekvens i statistikens metadata (ett vanligt off-by-one-fel, troligtvis på grund av 0-baserad kontra 1-baserad räkning), som kanske eller inte kan fixas i framtiden. Förstå att spårningsflaggan inte är dokumenterad för närvarande och att den inte rekommenderas att använda i en produktionsmiljö.
Sammanfattning
Tillägget av inkrementell statistik i SQL Server 2014-versionen är ett steg i rätt riktning för förbättrade kardinalitetsuppskattningar för partitionerade tabeller. Men som vi har visat är det aktuella värdet av inkrementell statistik begränsat till minskade underhållstider, eftersom denna inkrementella statistik ännu inte används av Query Optimizer.