Det här inlägget har "strängar kopplade:av en god anledning. Vi kommer att utforska djupt in i SQL VARCHAR, datatypen som hanterar strängar.
Detta är också "endast för dina ögon" eftersom utan strängar kommer det inte att finnas några blogginlägg, webbsidor, spelinstruktioner, bokmärkta recept och mycket mer för våra ögon att läsa och njuta av. Vi hanterar en gazillion strängar varje dag. Så som utvecklare är du och jag ansvariga för att göra denna typ av data effektiv att lagra och komma åt.
Med detta i åtanke kommer vi att täcka vad som är viktigast för lagring och prestanda. Ange vad som ska göras och inte göras för denna datatyp.
Men innan dess är VARCHAR bara en av strängtyperna i SQL. Vad gör det annorlunda?
Vad är VARCHAR i SQL? (Med exempel)
VARCHAR är en sträng- eller teckendatatyp av varierande storlek. Du kan lagra bokstäver, siffror och symboler med den. Från och med SQL Server 2019 kan du använda hela utbudet av Unicode-tecken när du använder en sortering med UTF-8-stöd.
Du kan deklarera VARCHAR-kolumner eller variabler med VARCHAR[(n)], där n står för strängstorleken i byte. Värdeintervallet för n är 1 till 8000. Det är mycket teckendata. Men ännu mer, du kan deklarera det med VARCHAR(MAX) om du behöver en gigantisk sträng på upp till 2GB. Det är tillräckligt stort för din lista över hemligheter och privata saker i din dagbok! Observera dock att du också kan deklarera det utan storleken och det är standard på 1 om du gör det.
Låt oss ta ett exempel.
DECLARE @actor VARCHAR(20) = 'Robert Downey Jr.';
DECLARE @movieCharacter VARCHAR(10) = 'Iron Man';
DECLARE @movie VARCHAR = 'Avengers';
SELECT @actor, @movieCharacter, @movie
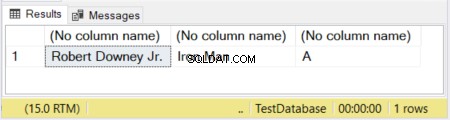
I figur 1 har de två första kolumnerna sina storlekar definierade. Den tredje kolumnen lämnas utan storlek. Så ordet "Avengers" är trunkerat eftersom en VARCHAR utan en deklarerad storlek har 1 tecken som standard.
Nu ska vi prova något stort. Men observera att den här frågan kommer att ta ett tag att köra – 23 sekunder på min bärbara dator.
-- This will take a while
DECLARE @giganticString VARCHAR(MAX);
SET @giganticString = REPLICATE(CAST('kage bunshin no jutsu' AS VARCHAR(MAX)),100000000)
SELECT DATALENGTH(@giganticString)
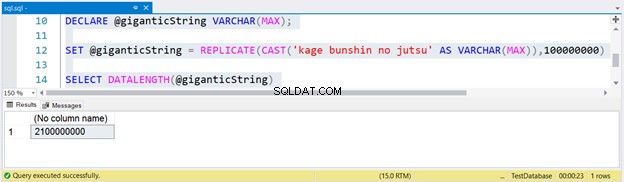
För att skapa en enorm sträng, replikerade vi kage bunshin no jutsu 100 miljoner gånger. Notera CAST i REPLICATE. Om du inte CASTAR stränguttrycket till VARCHAR(MAX), kommer resultatet att trunkeras till endast upp till 8000 tecken.
Men hur jämför SQL VARCHAR med andra strängdatatyper?
Skillnaden mellan CHAR och VARCHAR i SQL
Jämfört med VARCHAR är CHAR en teckendatatyp med fast längd. Oavsett hur litet eller stort värde du sätter på en CHAR-variabel, är den slutliga storleken storleken på variabeln. Kontrollera jämförelserna nedan.
DECLARE @tvSeriesTitle1 VARCHAR(20) = 'The Mandalorian';
DECLARE @tvSeriesTitle2 CHAR(20) = 'The Mandalorian';
SELECT DATALENGTH(@tvSeriesTitle1) AS VarcharValue,
DATALENGTH(@tvSeriesTitle2) AS CharValue
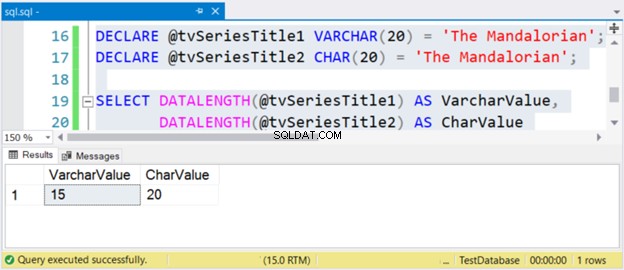
Storleken på strängen "The Mandalorian" är 15 tecken. Så, VarcharValue kolumnen återspeglar det korrekt. Men CharValue behåller storleken 20 – den är vadderad med 5 mellanslag till höger.
SQL VARCHAR vs NVARCHAR
Två grundläggande saker kommer att tänka på när man jämför dessa datatyper.
För det första är det storleken i byte. Varje karaktär i NVARCHAR har dubbelt så stor som VARCHAR. NVARCHAR(n) är endast från 1 till 4000.
Sedan, karaktärerna den kan lagra. NVARCHAR kan lagra flerspråkiga tecken som koreanska, japanska, arabiska, etc. Om du planerar att lagra koreanska K-Pop-texter i din databas är denna datatyp ett av dina alternativ.
Låt oss ta ett exempel. Vi kommer att använda K-pop-gruppen 세븐틴 eller Seventeen på engelska.
DECLARE @kpopGroupKorean NVARCHAR(5) = N'세븐틴';
SELECT @kpopGroupKorean AS KPopGroup,
DATALENGTH(@kpopGroupKorean) AS SizeInBytes,
LEN(@kpopGroupKorean) AS [NoOfChars]
Ovanstående kod matar ut strängvärdet, dess storlek i byte och antalet tecken. Om dessa är icke-Unicode-tecken är antalet tecken lika med storleken i byte. Men så är inte fallet. Kolla in figur 4 nedan.
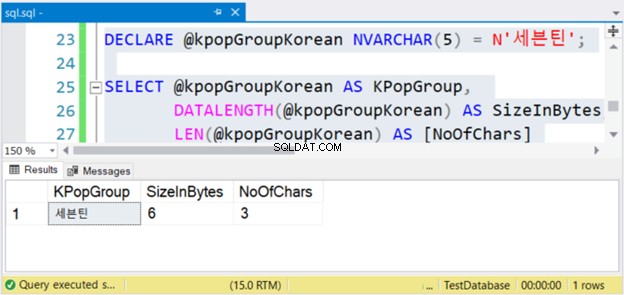
Ser? Om NVARCHAR har 3 tecken är storleken i byte två gånger. Men inte med VARCHAR. Detsamma gäller även om du använder engelska tecken.
Men vad sägs om NCHAR? NCHAR är motsvarigheten till CHAR för Unicode-tecken.
SQL-server VARCHAR med UTF-8-stöd
VARCHAR med UTF-8-stöd är möjligt på servernivå, databasnivå eller tabellkolumnnivå genom att ändra sorteringsinformationen. Den sortering som ska användas bör stödja UTF-8.
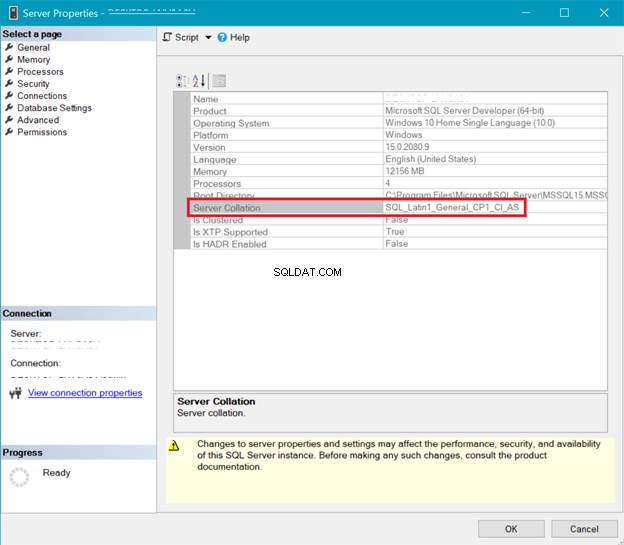
SQL-SERVERSAMLING
Figur 5 visar fönstret i SQL Server Management Studio som visar serverkollation.
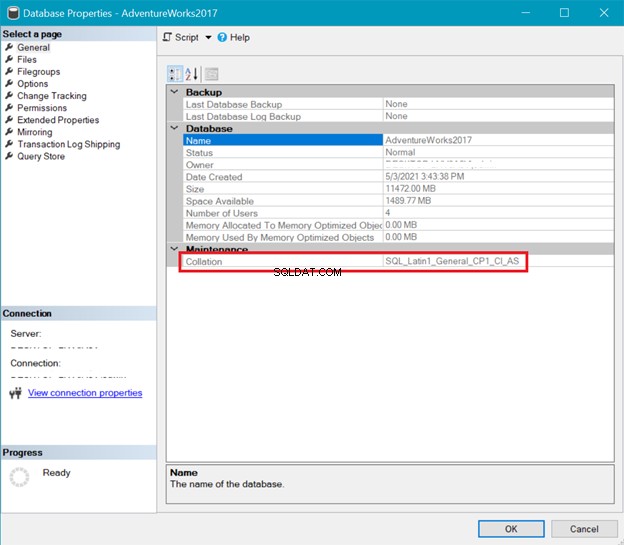
DATABASSAMLING
Samtidigt visar figur 6 sammanställningen av AdventureWorks databas.
SAMLING AV TABELLKOLUMN
Både server- och databassorteringen ovan visar att UTF-8 inte stöds. Sorteringssträngen bör ha en _UTF8 i sig för UTF-8-stöd. Men du kan fortfarande använda UTF-8-stöd på kolumnnivå i en tabell. Se exemplet.
CREATE TABLE SeventeenMemberList
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
KoreanName VARCHAR(20) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL,
EnglishName VARCHAR(20) NOT NULL
)
Ovanstående kod har Latin1_General_100_BIN2_UTF8 sammanställning för KoreanName kolumn. Även om VARCHAR och inte NVARCHAR, accepterar den här kolumnen koreanska tecken. Låt oss infoga några poster och sedan visa dem.
INSERT INTO SeventeenMemberList
(KoreanName, EnglishName)
VALUES
(N'에스쿱스','S.Coups')
,(N'원우','Wonwoo')
,(N'민규','Mingyu')
,(N'버논','Vernon')
,(N'우지','Woozi')
,(N'정한','Jeonghan')
,(N'조슈아','Joshua')
,(N'도겸','DK')
,(N'승관','Seungkwan')
,(N'호시','Hoshi')
,(N'준','Jun')
,(N'디에잇','The8')
,(N'디노','Dino')
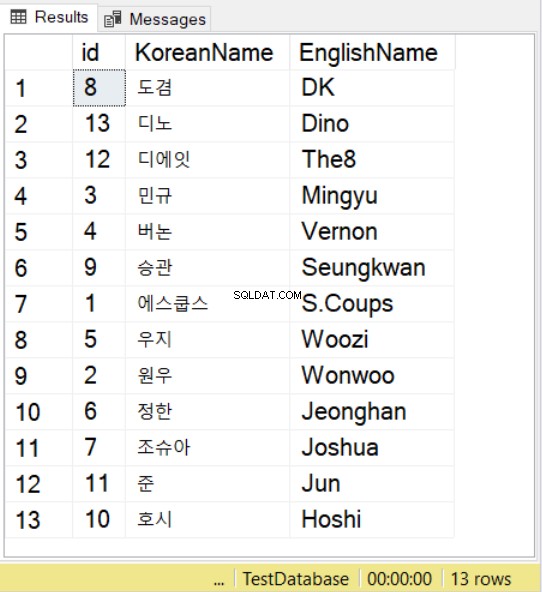
SELECT * FROM SeventeenMemberList
ORDER BY KoreanName
COLLATE Latin1_General_100_BIN2_UTF8
Vi använder namn från gruppen Seventeen K-pop med koreanska och engelska motsvarigheter. För koreanska tecken, lägg märke till att du fortfarande måste prefixa värdet med N , precis som vad du gör med NVARCHAR-värden.
Sedan, när du använder SELECT med ORDER BY, kan du också använda sortering. Du kan observera detta i exemplet ovan. Detta kommer att följa sorteringsregler för den angivna sorteringen.
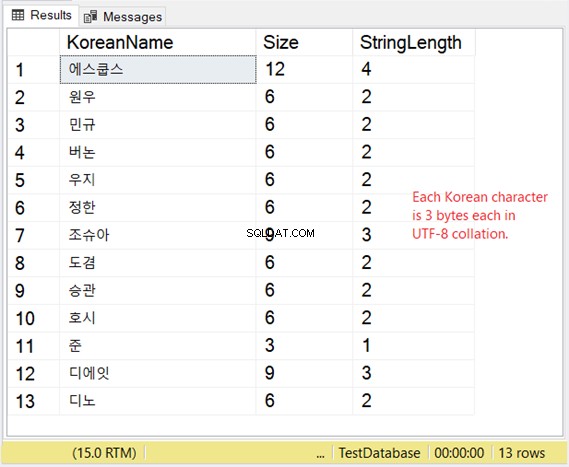
LAGRING AV VARCHAR MED UTF-8-SUPPORT
Men hur är lagringen av dessa karaktärer? Om du förväntar dig 2 byte per tecken får du en överraskning. Kolla in figur 8.
Så om lagring betyder mycket för dig, överväg tabellen nedan när du använder VARCHAR med UTF-8-stöd.
| Tecken | Storlek i byte |
| Ascii 0 – 127 | 1 |
| Den latinbaserade skriften och grekiska, kyrilliska, koptiska, armeniska, hebreiska, arabiska, syriska, Tāna och N’Ko | 2 |
| Östasiatiska manus som kinesiska, koreanska och japanska | 3 |
| Tecken i intervallet 010000–10FFFF | 4 |
Vårt koreanska exempel är ett östasiatiskt skript, så det är 3 byte per tecken.
Nu när vi är klara med att beskriva och jämföra VARCHAR med andra strängtyper, låt oss nu täcka vad du bör och inte får göra
Göra för att använda VARCHAR i SQL Server
1. Ange storleken
Vad kan gå fel utan att ange storleken?
TRUNKERING AV STRING
Om du blir lat med att specificera storleken kommer strängstympningen att inträffa. Du har redan sett ett exempel på detta tidigare.
LAGRING OCH PRESTANDA PÅVERKAN
En annan faktor är lagring och prestanda. Du behöver bara ställa in rätt storlek för dina data, inte mer. Men hur kunde du veta det? För att undvika trunkering i framtiden kanske du bara ställer in den på den största storleken. Det är VARCHAR(8000) eller till och med VARCHAR(MAX). Och 2 byte kommer att lagras som de är. Samma sak med 2GB. Spelar det någon roll?
Ett svar som tar oss till konceptet om hur SQL Server lagrar data. Jag har en annan artikel som förklarar detta i detalj med exempel och illustrationer.
Kort sagt, data lagras på 8KB-sidor. När en rad med data överskrider denna storlek, flyttar SQL Server den till en annan sidtilldelningsenhet som heter ROW_OVERFLOW_DATA.
Anta att du har 2-byte VARCHAR-data som kan passa den ursprungliga sidtilldelningsenheten. När du lagrar en sträng som är större än 8 000 byte, kommer data att flyttas till radöverflödessidan. Krymp sedan den igen till en lägre storlek, så flyttas den tillbaka till originalsidan. Rörelsen fram och tillbaka orsakar mycket I/O och en prestationsflaskhals. Att hämta detta från 2 sidor istället för 1 kräver extra I/O också.
En annan anledning är indexering. VARCHAR(MAX) är ett stort NEJ som indexnyckel. Under tiden kommer VARCHAR(8000) att överskrida den maximala indexnyckelstorleken. Det är 1700 byte för icke-klustrade index och 900 byte för klustrade index.
PÅVERKAN FÖR DATAOMVÄNDRING
Men det finns ett annat övervägande:datakonvertering. Prova med en CAST utan storleken som koden nedan.
SELECT
SYSDATETIMEOFFSET() AS DateTimeInput
,CAST(SYSDATETIMEOFFSET() AS VARCHAR) AS ConvertedDateTime
,DATALENGTH(CAST(SYSDATETIMEOFFSET() AS VARCHAR)) AS ConvertedLength
Denna kod kommer att göra en omvandling av ett datum/tid med tidszoninformation till VARCHAR.
Så om vi blir lata när vi anger storleken under CAST eller KONVERT, är resultatet begränsat till endast 30 tecken.
Vad sägs om att konvertera NVARCHAR till VARCHAR med UTF-8-stöd? Det finns en detaljerad förklaring av detta senare, så fortsätt läsa.
2. Använd VARCHAR om strängstorleken varierar avsevärt
Namn från AdventureWorks databasen varierar i storlek. Ett av de kortaste namnen är Min Su, medan det längsta namnet är Osarumwense Uwaifiokun Agbonile. Det är mellan 6 och 31 tecken inklusive mellanslag. Låt oss importera dessa namn till två tabeller och jämföra mellan VARCHAR och CHAR.
-- Table using VARCHAR
CREATE TABLE VarcharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
varcharName VARCHAR(50) NOT NULL
)
GO
CREATE INDEX IX_VarcharAsIndexKey_varcharName ON VarcharAsIndexKey(varcharName)
GO
-- Table using CHAR
CREATE TABLE CharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
charName CHAR(50) NOT NULL
)
GO
CREATE INDEX IX_CharAsIndexKey_charName ON CharAsIndexKey(charName)
GO
INSERT INTO VarcharAsIndexKey (varcharName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
INSERT INTO CharAsIndexKey (charName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
GO
Vilka av de 2 är bättre? Låt oss kontrollera de logiska läsningarna genom att använda koden nedan och inspektera utdata från STATISTICS IO.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT id, varcharName
FROM VarcharAsIndexKey
SELECT id, charName
FROM CharAsIndexKey
SET STATISTICS IO OFF
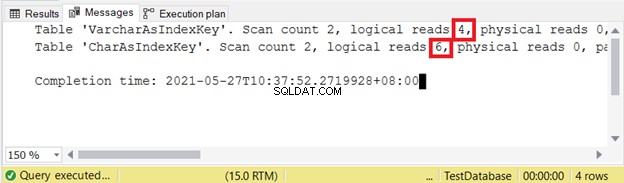
Logisk lyder:
Ju mindre logisk läsning desto bättre. Här använde CHAR-kolumnen mer än dubbelt så mycket som VARCHAR-motsvarigheten. Således vinner VARCHAR i detta exempel.
3. Använd VARCHAR som indexnyckel istället för CHAR när värden varierar i storlek
Vad hände när de användes som indexnycklar? Kommer CHAR klara sig bättre än VARCHAR? Låt oss använda samma data från föregående avsnitt och svara på den här frågan.
Vi kommer att fråga efter några data och kontrollera de logiska läsningarna. I det här exemplet använder filtret indexnyckeln.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT varcharName FROM VarcharAsIndexKey
WHERE varcharName = 'Sai, Adriana A'
OR varcharName = 'Rogers, Caitlin D'
SELECT charName FROM CharAsIndexKey
WHERE charName = 'Sai, Adriana A'
OR charName = 'Rogers, Caitlin D'
SET STATISTICS IO OFF
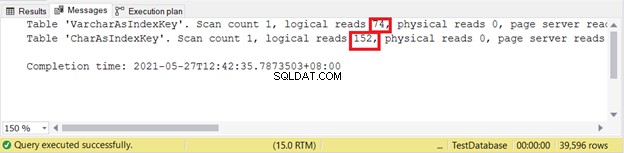
Logisk lyder:
Därför är VARCHAR-indexnycklar bättre än CHAR-indexnycklar när nyckeln har olika storlekar. Men vad sägs om INSERT och UPDATE som kommer att ändra indexposterna?
NÄR DU ANVÄNDER INFOGA OCH UPPDATERA
Låt oss testa 2 fall och sedan kontrollera de logiska läsningarna som vi brukar.
SET STATISTICS IO ON
INSERT INTO VarcharAsIndexKey (varcharName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
INSERT INTO CharAsIndexKey (charName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
SET STATISTICS IO OFF
Logisk lyder:
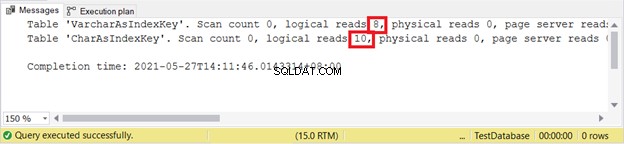
VARCHAR är fortfarande bättre när du infogar poster. Vad sägs om UPPDATERING?
SET STATISTICS IO ON
UPDATE VarcharAsIndexKey
SET varcharName = 'Hulk'
WHERE varcharName = 'Ruffalo, Mark'
UPDATE CharAsIndexKey
SET charName = 'Hulk'
WHERE charName = 'Ruffalo, Mark'
SET STATISTICS IO OFF
Logisk lyder:
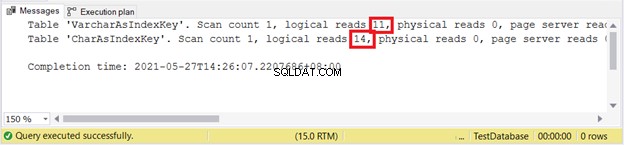
Det ser ut som att VARCHAR vinner igen.
Så småningom vinner den vårt test, även om det kan vara litet. Har du ett större testfall som bevisar motsatsen?
4. Överväg VARCHAR med UTF-8-stöd för flerspråkig data (SQL Server 2019+)
Om det finns en blandning av Unicode- och icke-Unicode-tecken i din tabell kan du överväga VARCHAR med UTF-8-stöd över NVARCHAR. Om de flesta tecknen ligger inom intervallet ASCII 0 till 127, kan det erbjuda utrymmesbesparingar jämfört med NVARCHAR.
För att se vad jag menar, låt oss göra en jämförelse.
NVARCHAR TILL VARCHAR MED UTF-8-SUPPORT
Har du redan migrerat dina databaser till SQL Server 2019? Planerar du att migrera dina strängdata till UTF-8-kollation? Vi har ett exempel på ett blandat värde av japanska och icke-japanska tecken för att ge dig en idé.
CREATE TABLE NVarcharToVarcharUTF8
(
NVarcharValue NVARCHAR(20) NOT NULL,
VarcharUTF8 VARCHAR(45) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL
)
GO
INSERT INTO NVarcharToVarcharUTF8
(NVarcharValue, VarcharUTF8)
VALUES
(N'NARUTO-ナルト- 疾風伝',N'NARUTO-ナルト- 疾風伝'); -- NARUTO Shippûden
SELECT
NVarcharValue
,LEN(NVarcharValue) AS nvarcharNoOfChars
,DATALENGTH(NVarcharValue) AS nvarcharSizeInBytes
,VarcharUTF8
,LEN(VarcharUTF8) AS varcharNoOfChars
,DATALENGTH(VarcharUTF8) AS varcharSizeInBytes
FROM NVarcharToVarcharUTF8
Nu när data är inställda kommer vi att inspektera storleken i byte av de två värdena:

Överraskning! Med NVARCHAR är storleken 30 byte. Det är 15 gånger fler än 2 tecken. Men när den konverteras till VARCHAR med UTF-8-stöd är storleken bara 27 byte. Varför 27? Kontrollera hur detta beräknas.

Således är 9 av tecknen 1 byte vardera. Det är intressant eftersom engelska bokstäver med NVARCHAR också är 2 byte. Resten av de japanska tecknen är 3 byte vardera.
Om detta har varit alla japanska tecken, skulle strängen på 15 tecken vara 45 byte och även förbruka den maximala storleken på VarcharUTF8 kolumn. Lägg märke till att storleken på NVarcharValue kolumnen är mindre än VarcharUTF8 .
Storlekarna kan inte vara lika vid konvertering från NVARCHAR, eller så kanske data inte passar. Du kan hänvisa till föregående tabell 1.
Tänk på storleken när du konverterar NVARCHAR till VARCHAR med UTF-8-stöd.
Gör inte vid användning av VARCHAR i SQL Server
1. När strängstorleken är fast och inte kan nollställas, använd CHAR istället.
Den allmänna tumregeln när en sträng med fast storlek krävs är att använda CHAR. Jag följer detta när jag har ett datakrav som behöver högerstoppade mellanslag. Annars kommer jag att använda VARCHAR. Jag hade några användningsfall när jag behövde dumpa strängar med fast längd utan avgränsare i en textfil för en klient.
Vidare använder jag endast CHAR-kolumner om kolumnerna inte är nullbara. Varför? Eftersom storleken i byte av CHAR-kolumner när NULL är lika med den definierade storleken på kolumnen. Ändå VARCHAR när NULL har en storlek på 1 oavsett hur stor den definierade storleken är. Kör koden nedan och se den själv.
DECLARE @charValue CHAR(50) = NULL;
DECLARE @varcharValue VARCHAR(1000) = NULL;
SELECT
DATALENGTH(ISNULL(@charvalue,0)) AS CharSize
,DATALENGTH(ISNULL(@varcharvalue,0)) AS VarcharSize
2. Använd inte VARCHAR(n) om n Kommer att överstiga 8000 byte. Använd VARCHAR(MAX) istället.
Har du en sträng som överstiger 8000 byte? Det är dags att använda VARCHAR(MAX). Men för de vanligaste formerna av data som namn och adresser är VARCHAR(MAX) överdriven och kommer att påverka prestandan. Enligt min personliga erfarenhet kommer jag inte ihåg ett krav på att jag använde VARCHAR(MAX).
3. När du använder flerspråkiga tecken med SQL Server 2017 och senare. Använd NVARCHAR istället.
Detta är ett självklart val om du fortfarande använder SQL Server 2017 och senare.
The Bottomline
VARCHAR-datatypen har tjänat oss väl för så många aspekter. Det gjorde det för mig sedan SQL Server 7. Men ibland gör vi fortfarande dåliga val. I det här inlägget definieras SQL VARCHAR och jämförs med andra strängdatatyper med exempel. Och återigen, här är vad du bör och inte får göra för en snabbare databas:
Göra:
- Ange storleken n i VARCHAR[(n)] även om det är valfritt.
- Använd den när strängstorleken varierar avsevärt.
- Se VARCHAR-kolumner som indexnycklar istället för CHAR.
- Och om du nu använder SQL Server 2019, överväg VARCHAR för flerspråkiga strängar med UTF-8-stöd.
Gör inte:
- Använd inte VARCHAR när strängstorleken är fast och inte kan nullställas.
- Använd inte VARCHAR(n) när strängstorleken överstiger 8000 byte.
- Använd inte VARCHAR för flerspråkig data när du använder SQL Server 2017 och tidigare.
Har du något mer att tillägga? Låt oss veta i kommentarsektionen. Om du tror att detta kommer att hjälpa dina utvecklarvänner, vänligen dela detta på dina favoritplattformar för sociala medier.