Låt oss säga att du vill hitta alla patienter som aldrig har fått en influensaspruta. Eller i AdventureWorks2012 , kan en liknande fråga vara, "visa mig alla kunder som aldrig har gjort en beställning." Uttryckt med NOT IN , ett mönster jag ser alltför ofta, som skulle se ut ungefär så här (jag använder den förstorade rubriken och detaljtabellerna från det här skriptet av Jonathan Kehayias (@SQLPoolBoy)):
SELECT CustomerID FROM Sales.Customer WHERE CustomerID NOT IN ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged );
När jag ser det här mönstret ryser jag till. Men inte av prestationsskäl – trots allt skapar det en tillräckligt bra plan i det här fallet:
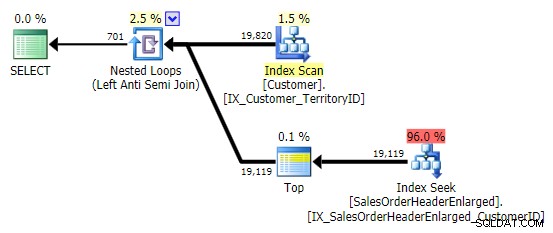
Huvudproblemet är att resultaten kan vara förvånande om målkolumnen är NULL-bar (SQL Server bearbetar detta som en vänster anti-semi-join, men kan inte tillförlitligt tala om för dig om en NULL på höger sida är lika med – eller inte lika med – referensen på vänster sida). Dessutom kan optimering bete sig annorlunda om kolumnen är NULL-bar, även om den faktiskt inte innehåller några NULL-värden (Gail Shaw pratade om detta redan 2010).
I det här fallet är målkolumnen inte nullbar, men jag ville nämna de potentiella problemen med NOT IN – Jag kan komma att undersöka de här frågorna mer ingående i ett framtida inlägg.
TL;DR-version
Istället för NOT IN , använd en korrelerad NOT EXISTS för detta frågemönster. Alltid. Andra metoder kan konkurrera med det när det gäller prestanda, när alla andra variabler är desamma, men alla andra metoder introducerar antingen prestandaproblem eller andra utmaningar.
Alternativ
Så på vilka andra sätt kan vi skriva den här frågan?
YTTRE ANVÄNDNING
Ett sätt vi kan uttrycka detta resultat är att använda en korrelerad OUTER APPLY .
SELECT c.CustomerID FROM Sales.Customer AS c OUTER APPLY ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged WHERE CustomerID = c.CustomerID ) AS h WHERE h.CustomerID IS NULL;
Logiskt sett är detta också en vänster anti-semi-join, men den resulterande planen saknar den vänstra anti-semi-join-operatören och verkar vara ganska mycket dyrare än NOT IN likvärdig. Detta beror på att det inte längre är en vänster anti semi-join; den bearbetas faktiskt på ett annat sätt:en yttre sammanfogning tar in alla matchande och icke-matchande rader, och *sedan* används ett filter för att eliminera matchningarna:
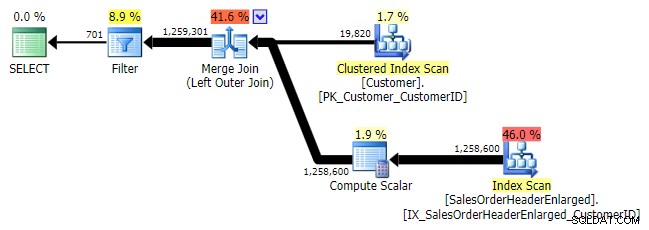
VÄNSTER YTTRE JOIN
Ett mer typiskt alternativ är LEFT OUTER JOIN där den högra sidan är NULL . I det här fallet skulle frågan vara:
SELECT c.CustomerID FROM Sales.Customer AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS h ON c.CustomerID = h.CustomerID WHERE h.CustomerID IS NULL;
Detta ger samma resultat; Men, precis som OUTER APPLY, använder den samma teknik för att slå samman alla rader och först då eliminera matchningarna:
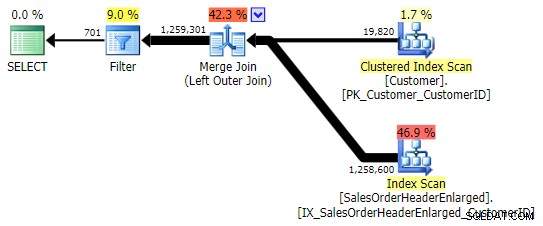
Du måste dock vara försiktig med vilken kolumn du kontrollerar för NULL . I det här fallet CustomerID är det logiska valet eftersom det är sammanfogningskolumnen; det råkar också vara indexerat. Jag kunde ha valt SalesOrderID , som är klustringsnyckeln, så den finns också i indexet på CustomerID . Men jag kunde ha valt en annan kolumn som inte finns i (eller som senare tas bort från) indexet som används för sammanfogningen, vilket leder till en annan plan. Eller till och med en NULLbar kolumn, vilket leder till felaktiga (eller åtminstone oväntade) resultat, eftersom det inte finns något sätt att skilja mellan en rad som inte finns och en rad som existerar men där den kolumnen är NULL . Och det kanske inte är uppenbart för läsaren/utvecklaren/felsökaren att så är fallet. Så jag kommer också att testa dessa tre WHERE klausuler:
WHERE h.SalesOrderID IS NULL; -- clustered, so part of index WHERE h.SubTotal IS NULL; -- not nullable, not part of the index WHERE h.Comment IS NULL; -- nullable, not part of the index
Den första varianten ger samma plan som ovan. De andra två väljer en hash-join istället för en merge-join och ett smalare index i Customer tabell, även om frågan i slutändan slutar läsa exakt samma antal sidor och mängd data. Men medan h.SubTotal variation ger rätt resultat:
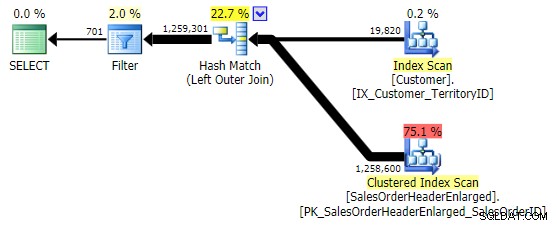
h.Comment variationen inte, eftersom den inkluderar alla rader där h.Comment IS NULL , samt alla rader som inte fanns för någon kund. Jag har lyft fram den subtila skillnaden i antalet rader i utgången efter att filtret har tillämpats:
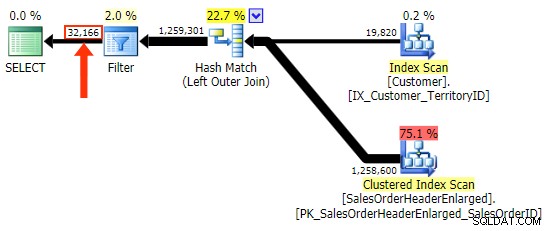
Förutom att jag måste vara försiktig med kolumnval i filtret, det andra problemet jag har med LEFT OUTER JOIN formen är att den inte är självdokumenterande, på samma sätt som en inre sammanfogning i den "gamla" formen av FROM dbo.table_a, dbo.table_b WHERE ... är inte självdokumenterande. Med det menar jag att det är lätt att glömma sammanfogningskriterierna när det skjuts till WHERE klausul, eller för att den ska blandas in med andra filterkriterier. Jag inser att detta är ganska subjektivt, men där är det.
UTOM
Om allt vi är intresserade av är sammanfogningskolumnen (som per definition finns i båda tabellerna), kan vi använda EXCEPT – ett alternativ som inte verkar dyka upp så mycket i dessa konversationer (förmodligen för att – vanligtvis – du behöver utöka frågan för att inkludera kolumner du inte jämför):
SELECT CustomerID FROM Sales.Customer AS c EXCEPT SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged;
Detta kommer med exakt samma plan som NOT IN variant ovan:
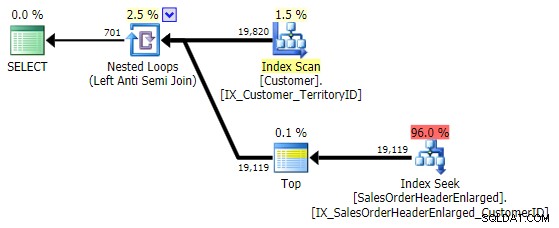
En sak att tänka på är att EXCEPT innehåller en implicit DISTINCT – så om du har fall där du vill ha flera rader med samma värde i den "vänstra" tabellen, kommer detta formulär att eliminera dessa dubbletter. Inte ett problem i det här specifika fallet, bara något att tänka på – precis som UNION kontra UNION ALL .
FINNS INTE
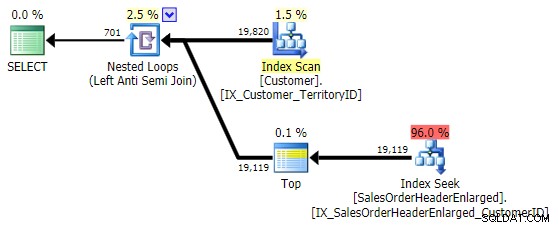
Min preferens för det här mönstret är definitivt NOT EXISTS :
SELECT CustomerID
FROM Sales.Customer AS c
WHERE NOT EXISTS
(
SELECT 1
FROM Sales.SalesOrderHeaderEnlarged
WHERE CustomerID = c.CustomerID
);
(Och ja, jag använder SELECT 1 istället för SELECT * … inte av prestandaskäl, eftersom SQL Server inte bryr sig om vilka kolumner du använder i EXISTS och optimerar bort dem, men helt enkelt för att förtydliga avsikten:detta påminner mig om att denna "underfråga" faktiskt inte returnerar någon data.)
Dess prestanda liknar NOT IN och EXCEPT , och det producerar en identisk plan, men är inte benägen för de potentiella problem som orsakas av NULL eller dubbletter:
Prestandatester
Jag körde en mängd tester, med både en kall och varm cache, för att bekräfta att min långvariga uppfattning om NOT EXISTS att vara det rätta valet förblev sant. Den typiska utgången såg ut så här:
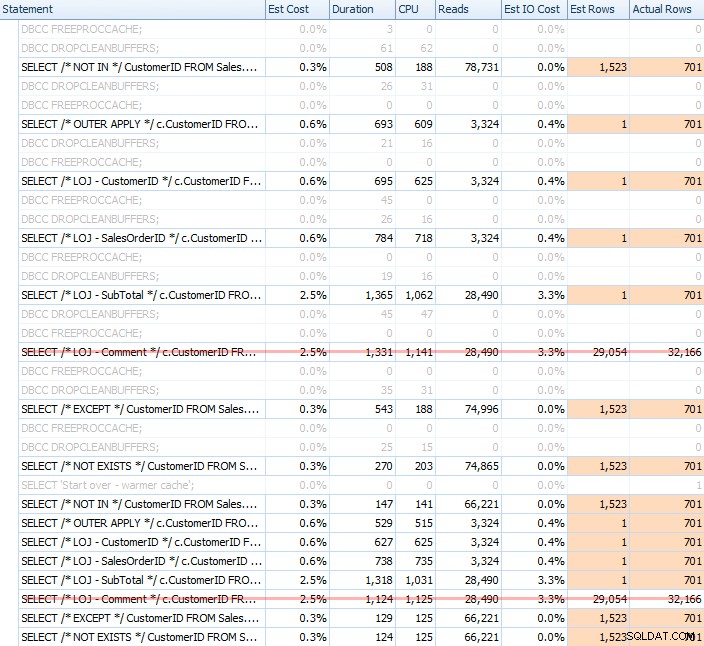
Jag tar bort det felaktiga resultatet ur mixen när jag visar den genomsnittliga prestandan för 20 körningar på en graf (jag inkluderade bara det för att visa hur fel resultaten är), och jag körde frågorna i olika ordningsföljd över testerna för att vara säker att en fråga inte konsekvent gynnades av arbetet med en tidigare fråga. Med fokus på varaktighet, här är resultaten:
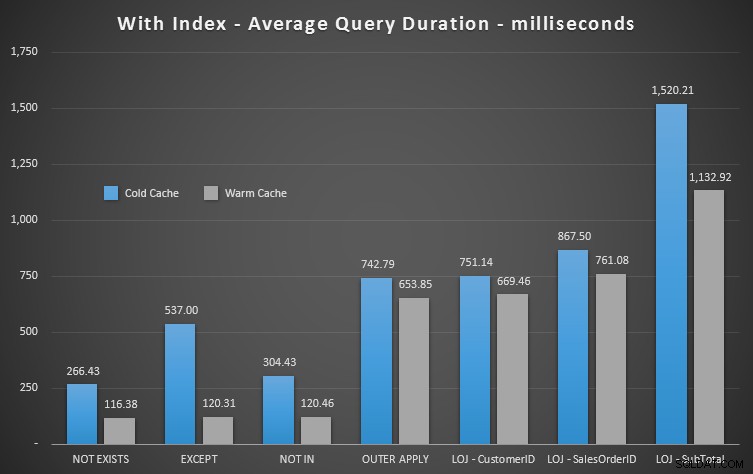
Om vi tittar på varaktighet och ignorerar läsningar, är INTE FINNS din vinnare, men inte mycket. EXCEPT och NOT IN är inte långt efter, men återigen måste du titta på mer än prestanda för att avgöra om dessa alternativ är giltiga och testa i ditt scenario.
Vad händer om det inte finns något stödjande index?
Frågorna ovan drar naturligtvis nytta av indexet på Sales.SalesOrderHeaderEnlarged.CustomerID . Hur förändras dessa resultat om vi tappar det här indexet? Jag körde samma uppsättning tester igen efter att ha tappat indexet:
DROP INDEX [IX_SalesOrderHeaderEnlarged_CustomerID] ON [Sales].[SalesOrderHeaderEnlarged];
Den här gången var det mycket mindre avvikelse vad gäller prestanda mellan de olika metoderna. Först ska jag visa planerna för varje metod (varav de flesta, inte överraskande, indikerar användbarheten av det saknade indexet som vi just tappade). Sedan visar jag en ny graf som visar prestandaprofilen både med en kall cache och en varm cache.
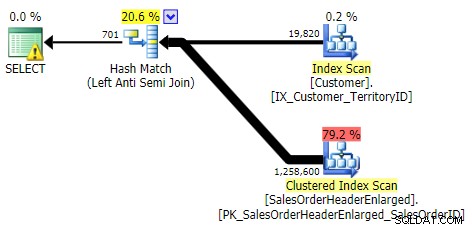
INTE I, UTOM, FINNS INTE (alla tre var identiska)
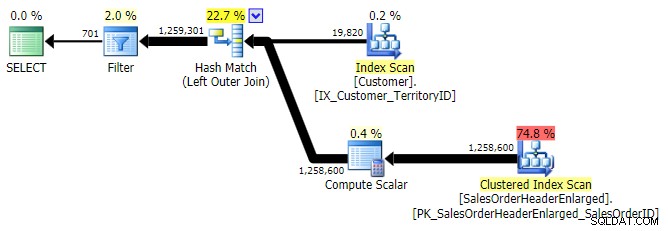
YTTRE ANVÄNDNING
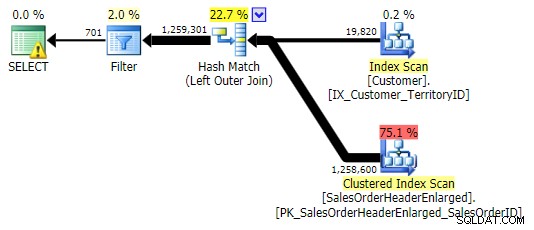
LEFT OUTER JOIN (alla tre var identiska förutom antalet rader)
Prestanda resultat
Vi kan direkt se hur användbart indexet är när vi tittar på dessa nya resultat. I alla fall utom ett (den vänstra yttre sammanfogningen som ändå går utanför indexet) är resultaten klart sämre när vi har tappat indexet:
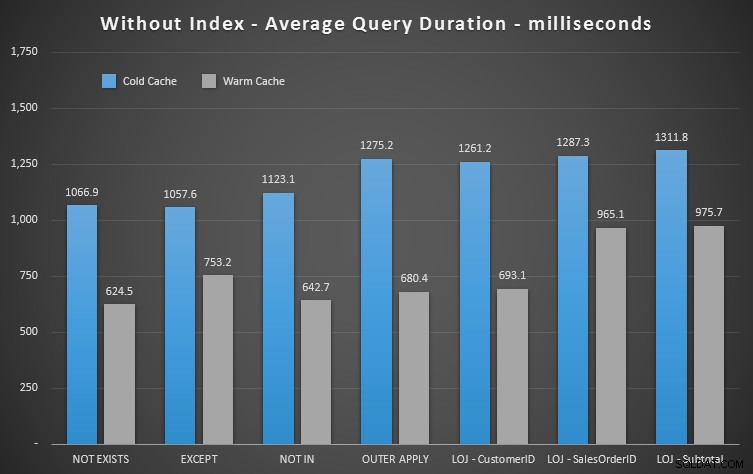
Så vi kan se att även om det är mindre märkbar effekt, NOT EXISTS är fortfarande din marginella vinnare när det gäller varaktighet. Och i situationer där andra tillvägagångssätt är mottagliga för schemavolatilitet, är det också ditt säkraste val.
Slutsats
Det här var bara ett väldigt långrandigt sätt att berätta att för mönstret att hitta alla rader i tabell A där något villkor inte existerar i tabell B, NOT EXISTS kommer vanligtvis att vara ditt bästa val. Men som alltid måste du testa dessa mönster i din egen miljö, med ditt schema, data och hårdvara, och blandas med dina egna arbetsbelastningar.