SQL Server 2014 förde med sig många nya funktioner som DBA:er och utvecklare såg fram emot att testa och använda i sina miljöer, såsom det uppdateringsbara klustrade Columnstore-indexet, Delayed Durability och Buffer Pool Extensions. En funktion som inte ofta diskuteras är inkrementell statistik. Om du inte använder partitionering är detta inte en funktion du kan implementera. Men om du har partitionerade tabeller i din databas, kan inkrementell statistik ha varit något du ivrigt hade förväntat dig.
Obs:Benjamin Nevarez behandlade några grunder relaterade till inkrementell statistik i sitt inlägg från februari 2014, SQL Server 2014 Incremental Statistics. Och även om inte mycket har förändrats i hur den här funktionen fungerar sedan hans inlägg och releasen i april 2014, verkade det vara ett bra tillfälle att gräva i hur aktivering av inkrementell statistik kan hjälpa till med underhållsprestanda.
Inkrementell statistik kallas ibland statistik på partitionsnivå, och detta beror på att SQL Server för första gången automatiskt kan skapa statistik som är specifik för en partition. En av de tidigare utmaningarna med partitionering var att även om du kunde ha 1 till n partitioner för en tabell, fanns det bara en (1) statistik som representerade datafördelningen över alla dessa partitioner. Du kan skapa filtrerad statistik för den partitionerade tabellen – en statistik för varje partition – för att ge frågeoptimeraren bättre information om distributionen av data. Men detta var en manuell process och krävde ett skript för att automatiskt skapa dem för varje ny partition.
I SQL Server 2014 använder du STATISTICS_INCREMENTAL alternativet att låta SQL Server skapa denna statistik på partitionsnivå automatiskt. Denna statistik används dock inte som du kanske tror.
Jag nämnde tidigare att du före 2014 kunde skapa filtrerad statistik för att ge optimeraren bättre information om partitionerna. Den där inkrementella statistiken? De används för närvarande inte av optimeraren. Frågeoptimeraren använder fortfarande bara huvudhistogrammet som representerar hela tabellen. (Inlägg kommer som kommer att visa detta!)
Så vad är poängen med inkrementell statistik? Om du antar att endast data i den senaste partitionen ändras, uppdaterar du helst bara statistik för den partitionen. Du kan göra detta nu med inkrementell statistik – och vad som händer är att information sedan slås samman tillbaka till huvudhistogrammet. Histogrammet för hela tabellen kommer att uppdateras utan att behöva läsa igenom hela tabellen för att uppdatera statistik, och detta kan hjälpa dig att utföra dina underhållsuppgifter.
Inställningar
Vi börjar med att skapa en partitionsfunktion och ett schema, och sedan en ny tabell som vi kommer att partitionera. Observera att jag skapade en filgrupp för varje partitionsfunktion som du kan göra i en produktionsmiljö. Du kan skapa partitionsschemat på samma filgrupp (t.ex. PRIMARY ) om du inte enkelt kan släppa din testdatabas. Varje filgrupp är också några GB stor, eftersom vi kommer att lägga till nästan 400 miljoner rader.
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 1024MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; /* create partition function */ CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', -- everything in 2011 '20120101', -- everything in 2012 '20130101', -- everything in 2013 '20140101', -- everything in 2014 '20150101' -- everything in 2015 ); GO /* create partition scheme */ CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO /* create the table */ CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Innan vi lägger till data skapar vi det klustrade indexet och noterar att syntaxen inkluderar WITH (STATISTICS_INCREMENTAL = ON) alternativ:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) WITH (STATISTICS_INCREMENTAL = ON) ON [OrderDateRangePScheme] ([OrderDate]);
Det som är intressant att notera här är att om du tittar på ALTER TABLE post i MSDN, inkluderar det inte detta alternativ. Du hittar det bara i ALTER INDEX ingång... men det här fungerar. Om du vill följa dokumentationen till punkt och pricka, kör du:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) ON [OrderDateRangePScheme] ([OrderDate]); GO ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON);
När det klustrade indexet har skapats för partitionsschemat, laddar vi in våra data och kontrollerar sedan hur många rader som finns per partition (observera att detta tar över 7 minuter på min bärbara dator kanske du vill lägga till färre rader beroende på hur mycket lagringsutrymme (och tid) du har tillgängligt):
/* load some data */
SET NOCOUNT ON;
DECLARE @Loops SMALLINT = 0;
DECLARE @Increment INT = 5000;
WHILE @Loops < 10000 -- adjust this to increase or decrease the number
-- of rows in the table, 10000 = 40 millon rows
BEGIN
INSERT [dbo].[Orders]
( [PurchaseOrderID]
,[EmployeeID]
,[VendorID]
,[TaxAmt]
,[Freight]
,[SubTotal]
,[Status]
,[RevisionNumber]
,[ModifiedDate]
,[ShipMethodID]
,[ShipDate]
,[OrderDate]
,[TotalDue]
)
SELECT
[PurchaseOrderID] + @Increment
, [EmployeeID]
, [VendorID]
, [TaxAmt]
, [Freight]
, [SubTotal]
, [Status]
, [RevisionNumber]
, [ModifiedDate]
, [ShipMethodID]
, [ShipDate]
, [OrderDate]
, [TotalDue]
FROM [Purchasing].[PurchaseOrderHeader];
CHECKPOINT;
SET @Loops = @Loops + 1;
SET @Increment = @Increment + 5000;
END
/* Check to see how much data exists per partition */
SELECT
$PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number]
, MIN([o].[OrderDate]) AS [Min_Order_Date]
, MAX([o].[OrderDate]) AS [Max_Order_Date]
, COUNT(*) AS [Rows In Partition]
FROM [dbo].[Orders] AS [o]
GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate])
ORDER BY [Partition Number];
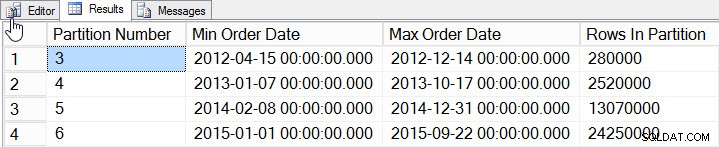 Data per partition
Data per partition
Vi har lagt till data för 2012 till 2015, med betydligt mer data under 2014 och 2015. Låt oss se hur vår statistik ser ut:
DBCC SHOW_STATISTICS ('dbo.Orders',[OrdersPK]);
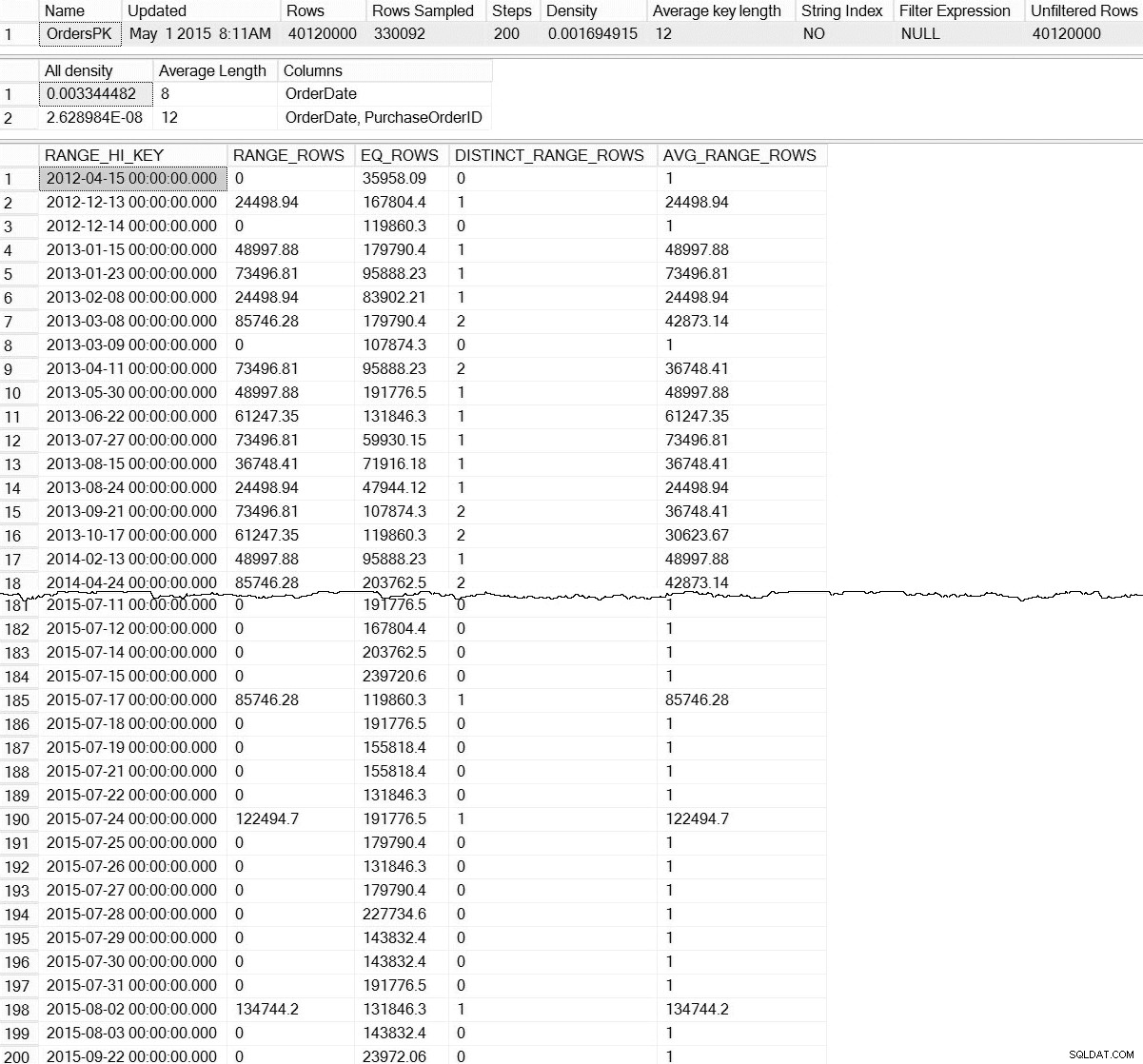 DBCC SHOW_STATISTICS-utdata för dbo.Orders (klicka för att förstora)
DBCC SHOW_STATISTICS-utdata för dbo.Orders (klicka för att förstora)
Med standard DBCC SHOW_STATISTICS kommando har vi ingen information om statistik på partitionsnivå. Frukta inte; vi är inte helt dömda – det finns en odokumenterad dynamisk hanteringsfunktion, sys.dm_db_stats_properties_internal . Kom ihåg att odokumenterad betyder att den inte stöds (det finns ingen MSDN-post för DMF), och att den kan ändras när som helst utan någon varning från Microsoft. Som sagt, det är en bra start för att få en uppfattning om vad som finns för vår inkrementella statistik:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 Histograminformation från dm_db_stats_properties_internal (klicka för att förstora)
Histograminformation från dm_db_stats_properties_internal (klicka för att förstora)
Det här är mycket mer intressant. Här kan vi se bevis på att det finns statistik på partitionsnivå (och mer). Eftersom denna DMF inte är dokumenterad måste vi göra någon tolkning. För idag kommer vi att fokusera på de första sju raderna i utdata, där den första raden representerar histogrammet för hela tabellen (observera rows värde på 40 miljoner), och de efterföljande raderna representerar histogrammen för varje partition. Tyvärr, partition_number värdet i detta histogram stämmer inte överens med partitionsnumret från sys.dm_db_index_physical_stats för högerbaserad partitionering (det korrelerar korrekt för vänsterbaserad partitionering). Observera också att denna utdata också inkluderar last_updated och modification_counter kolumner, som är användbara vid felsökning, och den kan användas för att utveckla underhållsskript som på ett intelligent sätt uppdaterar statistik baserat på ålders- eller radändringar.
Minimerar underhåll som krävs
Det primära värdet för inkrementell statistik för närvarande är möjligheten att uppdatera statistik för en partition och få den att slås samman i histogrammet på tabellnivå, utan att behöva uppdatera statistiken för hela tabellen (och därför läsa igenom hela tabellen). För att se detta i praktiken, låt oss först uppdatera statistiken för partitionen som innehåller 2015-data, partition 5, och vi kommer att registrera den tid som tagits och en ögonblicksbild av sys.dm_io_virtual_file_stats DMF före och efter för att se hur mycket I/O som förekommer:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH RESAMPLE ON PARTITIONS(6); GO SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture AS f INNER JOIN #SecondCapture AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Utdata:
SQL Server Execution Times:CPU-tid =203 ms, förfluten tid =240 ms.
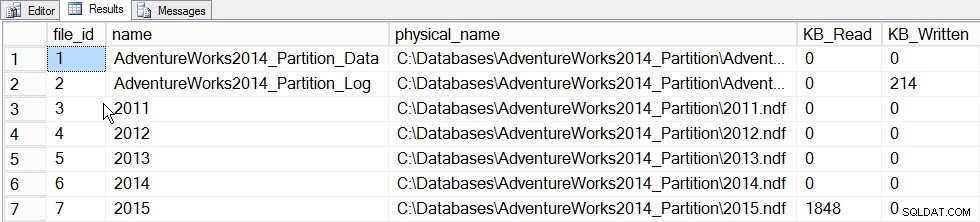 File_stats-data efter uppdatering av en partition
File_stats-data efter uppdatering av en partition
Om vi tittar på sys.dm_db_stats_properties_internal utdata ser vi att last_updated ändrats för både 2015 års histogram och histogrammet på tabellnivå (liksom några andra noder, som är för senare undersökning):
 Uppdaterad histograminformation från dm_db_stats_properties_internal
Uppdaterad histograminformation från dm_db_stats_properties_internal
Nu kommer vi att uppdatera statistiken med en FULLSCAN för tabellen, så tar vi en ögonblicksbild av file_stats före och efter igen:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH FULLSCAN SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture2 AS f INNER JOIN #SecondCapture2 AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Utdata:
SQL Server Execution Times:CPU-tid =12720 ms, förfluten tid =13646 ms
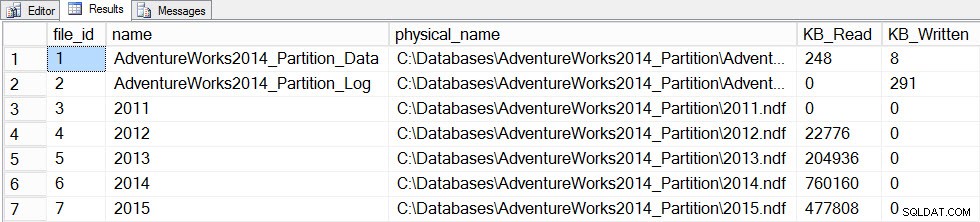 Filestats data efter uppdatering med fullscan
Filestats data efter uppdatering med fullscan
Uppdateringen tog betydligt längre tid (13 sekunder mot ett par hundra millisekunder) och genererade mycket mer I/O. Om vi kontrollerar sys.dm_db_stats_properties_internal igen, vi finner att last_updated ändrat för alla histogrammen:
 Histograminformation från dm_db_stats_properties_internal efter en fullskanning
Histograminformation från dm_db_stats_properties_internal efter en fullskanning
Sammanfattning
Även om inkrementell statistik ännu inte används av frågeoptimeraren för att tillhandahålla information om varje partition, ger den en prestandafördel vid hantering av statistik för partitionerade tabeller. Om statistiken bara behöver uppdateras för utvalda partitioner kan bara de uppdateras. Den nya informationen slås sedan samman i histogrammet på tabellnivå, vilket ger optimeraren mer aktuell information, utan kostnaden för att läsa hela tabellen. Framöver hoppas vi att denna statistik på partitionsnivå kommer användas av optimeraren. Håll utkik...