Tabellvärdade parametrar har funnits sedan SQL Server 2008 och ger en användbar mekanism för att skicka flera rader med data till SQL Server, sammanförda som ett enda parameteranrop. Alla rader är sedan tillgängliga i en tabellvariabel som sedan kan användas i standard T-SQL-kodning, vilket eliminerar behovet av att skriva specialiserad bearbetningslogik för att bryta ner data igen. Enligt själva definitionen är tabellvärdade parametrar starkt skrivna till en användardefinierad tabelltyp som måste finnas i databasen där anropet görs. Men starkt skrivet är inte riktigt strikt "starkt typat" som du kan förvänta dig, vilket den här artikeln kommer att visa, och prestandan kan påverkas som ett resultat.
För att demonstrera de potentiella prestandaeffekterna av felaktigt skrivna tabellvärdade parametrar med SQL Server, kommer vi att skapa ett exempel på en användardefinierad tabelltyp med följande struktur:
CREATE TYPE dbo.PharmacyData AS TABLE ( Dosage int, Drug varchar(20), FirstName varchar(50), LastName varchar(50), AddressLine1 varchar(250), PhoneNumber varchar(50), CellNumber varchar(50), EmailAddress varchar(100), FillDate datetime );
Då kommer vi att behöva en .NET-applikation som kommer att använda denna användardefinierade tabelltyp som en indataparameter för att skicka data till SQL Server. För att använda en tabellvärderad parameter från vår applikation fylls vanligtvis ett DataTable-objekt i och skickas sedan som värdet för parametern med en typ av SqlDbType.Structured. Datatabellen kan skapas på flera sätt i .NET-koden, men ett vanligt sätt att skapa tabellen på är ungefär följande:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData");
DefaultTable.Columns.Add("Dosage", typeof(int));
DefaultTable.Columns.Add("Drug", typeof(string));
DefaultTable.Columns.Add("FirstName", typeof(string));
DefaultTable.Columns.Add("LastName", typeof(string));
DefaultTable.Columns.Add("AddressLine1", typeof(string));
DefaultTable.Columns.Add("PhoneNumber", typeof(string));
DefaultTable.Columns.Add("CellNumber", typeof(string));
DefaultTable.Columns.Add("EmailAddress", typeof(string));
DefaultTable.Columns.Add("Date", typeof(DateTime)); Du kan också skapa datatabellen med hjälp av inline-definitionen enligt följande:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{"Dosage", typeof(int)},
{"Drug", typeof(string)},
{"FirstName", typeof(string)},
{"LastName", typeof(string)},
{"AddressLine1", typeof(string)},
{"PhoneNumber", typeof(string)},
{"CellNumber", typeof(string)},
{"EmailAddress", typeof(string)},
{"Date", typeof(DateTime)},
},
Locale = CultureInfo.InvariantCulture
}; Endera av dessa definitioner av DataTable-objektet i .NET kan användas som en tabellvärderad parameter för den användardefinierade datatypen som skapades, men lägg märke till typen av (sträng) definition för de olika strängkolumnerna; dessa kan alla vara "korrekt" skrivna men de är faktiskt inte starkt skrivna till datatyperna implementerade i den användardefinierade datatypen. Vi kan fylla tabellen med slumpmässiga data och skicka den till SQL Server som en parameter till en mycket enkel SELECT-sats som kommer att returnera exakt samma rader som tabellen som vi skickade in, enligt följande:
using (SqlCommand cmd = new SqlCommand("SELECT * FROM @tvp;", connection))
{
var pList = new SqlParameter("@tvp", SqlDbType.Structured);
pList.TypeName = "dbo.PharmacyData";
pList.Value = DefaultTable;
cmd.Parameters.Add(pList);
cmd.ExecuteReader().Dispose();
} Vi kan sedan använda en felsökningsbrytning så att vi kan inspektera definitionen av DefaultTable under körning, som visas nedan:
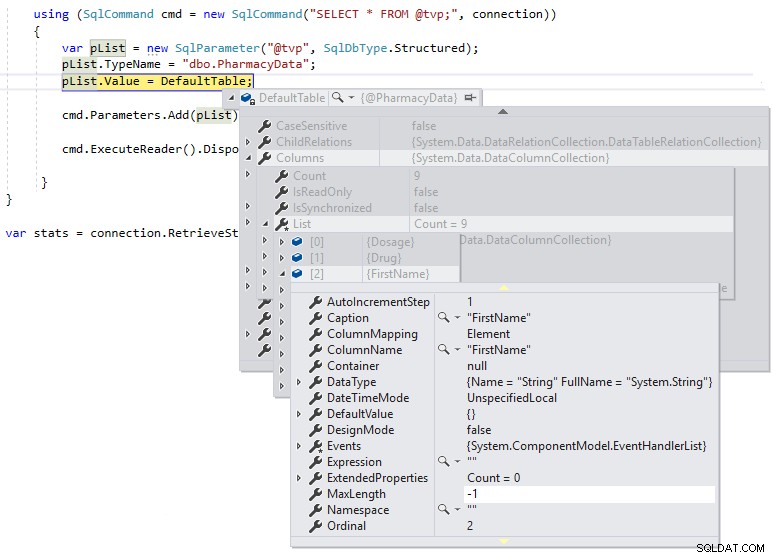
Vi kan se att MaxLength för strängkolumnerna är satt till -1, vilket betyder att de skickas över TDS till SQL Server som LOBs (stora objekt) eller i huvudsak som MAX datatypade kolumner, och detta kan påverka prestandan på ett negativt sätt. Om vi ändrar .NET DataTable-definitionen så att den är starkt skriven till schemadefinitionen för den användardefinierade tabelltypen enligt följande och tittar på MaxLength för samma kolumn med en felsökningsbrytning:
System.Data.DataTable SchemaTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{new DataColumn() { ColumnName = "Dosage", DataType = typeof(int)} },
{new DataColumn() { ColumnName = "Drug", DataType = typeof(string), MaxLength = 20} },
{new DataColumn() { ColumnName = "FirstName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "LastName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "AddressLine1", DataType = typeof(string), MaxLength = 250} },
{new DataColumn() { ColumnName = "PhoneNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "CellNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "EmailAddress", DataType = typeof(string), MaxLength = 100} },
{new DataColumn() { ColumnName = "Date", DataType = typeof(DateTime)} },
},
Locale = CultureInfo.InvariantCulture
};
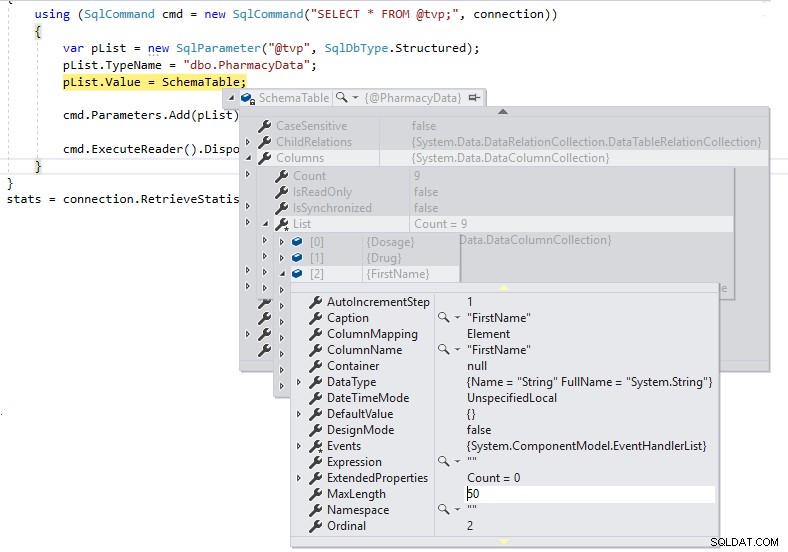
Vi har nu korrekta längder för kolumndefinitionerna, och vi kommer inte att skicka dem som LOBs över TDS till SQL Server.
Hur påverkar detta prestandan kanske du undrar? Det påverkar antalet TDS-buffertar som skickas över nätverket till SQL Server, och det påverkar också den totala bearbetningstiden för kommandona.
Genom att använda exakt samma datauppsättning för de två datatabellerna och använda metoden RetrieveStatistics på SqlConnection-objektet kan vi få ExecutionTime och BuffersSent statistikmått för anropen till samma SELECT-kommando, och bara använda de två olika DataTable-definitionerna som parametrar och att anropa SqlConnection-objektets ResetStatistics-metod tillåter att exekveringsstatistiken rensas mellan testerna.
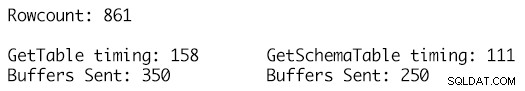
GetSchemaTable-definitionen anger MaxLength för var och en av strängkolumnerna korrekt där GetTable bara lägger till kolumner av typen sträng som har ett MaxLength-värde satt till -1 vilket resulterar i att 100 ytterligare TDS-buffertar skickas för 861 rader med data i tabellen och en körtid av 158 millisekunder jämfört med att endast 250 buffertar skickas för den starkt skrivna DataTable-definitionen och en körtid på 111 millisekunder. Även om detta kanske inte verkar så mycket i det stora hela, är detta ett enda samtal, en enda avrättning, och den ackumulerade effekten över tid för många tusen eller miljoner sådana avrättningar är där fördelarna börjar läggas ihop och har en märkbar effekt på arbetsbelastningsprestanda och genomströmning.
Där detta verkligen kan göra skillnad är i molnimplementationer där du betalar för mer än bara dator- och lagringsresurser. Förutom att ha de fasta kostnaderna för hårdvaruresurser för Azure VM, SQL Database eller AWS EC2 eller RDS, tillkommer en extra kostnad för nätverkstrafik till och från molnet som kopplas till faktureringen för varje månad. Att minska buffertarna som går över tråden kommer att sänka TCO för lösningen över tid, och kodändringarna som krävs för att implementera dessa besparingar är relativt enkla.