Ett databashanteringssystem är informationens starkbox. Vi kommer att försöka designa databashanteringssystemet så att databasen ska förbli välskött och tillhandahålla ändamålen.
I den här artikeln kommer vi att diskutera design och administrering av stora databassystem. Vi kommer att använda flera konstitutioner som inkluderar databasteknik, lagring, datadistribution, servertillgångar, arkitekturmönster och några andra.
Helst ska vi leta efter en stor databas inom Telco-domänen, e-handelsplattformar, försäkringsdomän, banksystem, sjukvård, energisystem etc. Vi måste ha några parametrar i åtanke inför valet av rätt databasteknik. d.v.s. Traffic, TPS (Transactions Per Second), uppskattad lagring per dag, HA och DR.
Designa en stor databas
När vi bygger vår databas måste vi vara uppmärksamma på flera parametrar eftersom det ofta är mycket problematiskt att ändra databasen med en ersättning. Låt oss överväga dem nu.
Databasteknik
Databasteknik är den primära faktorn. Om du väljer rätt databashanteringssystem hjälper det ditt företag att drivas effektivt och utan ansträngning.
Det finns olika databastekniker med många funktioner. Men när du arbetar med databastekniker med öppen källkod kanske du inte får tillgång till vissa explicita funktioner i fördefinierade lösningar. Företagsdatabastekniker som Microsoft SQL Server, Oracle, etc. skulle tillhandahålla dem.
Många företagsdatabasteknologier implementerar HA (High Availability), DR (Disaster Recovery), Mirroring, Datareplikering, Secondary Read Replica och betydligt mer bekväma och färdiga konfigurerbara affärslösningar. De kanske finns i databaser med öppen källkod eller inte.
Det finns många många anledningar. Till exempel upptäcker vi ibland att den befintliga arkitekturen störs eftersom de faktorer som nämns ovan inte fungerar som vi behöver dem.
Lagring
Lagringen påverkar affärslösningens prestanda drastiskt. Affärslösningar kräver förstklassig lagring eller SSD med en viss mängd IOPS. Men är det så? On-premises eller Cloud, Storleken och typen av lagring avgör infrastrukturkostnaderna.
Medan vi överväger lagringsprestanda måste vi vara uppmärksamma på typen av data och beteendet för databehandlingen. Vi måste välja lagringsval enligt användarens data och bearbetning av dem. Om användaren ska använda flera databaser måste vi tillhandahålla lagringsvalet framför SAN för olika databaser för datatyperna och databearbetningsbeteendet.
Databasingenjören kommer att ge en bättre retrospektion på de olika databaserna som behövs IOPS-beräkning om användarna inte behöver premiumlagring alls.
Datadistribution
De flesta av de senaste databasteknikerna (SQL eller NoSQL) erbjuder funktioner för partitionering eller delning.
- Partitionen omfördelar data i filsystemet som är baserat på partitionsnyckeln.
- Sharding distribuerar information över databasnoderna och data lagras i samma eller annan maskin.
I grund och botten kommer inte varje databastjänst eller databastabell att kräva funktionerna för datapartitionering/delning. De behöver bara tillämpas på databaser som innehåller större objekt. Det kommer att förbättra prestandan.
Servertillgångar
Olika maskiner kräver olika typer och storlekar av minne och CPU. Du måste ta hänsyn till tillgångarna på hårdvarunivå, såsom minne, processor, etc. Till exempel kommer en maskin som måste hantera större databaser eller flera databaser att behöva mer minne och processorer. Därför är kvaliteten på minne och processor betydande. Den kommer att hantera olika typer av processorer som finns på marknaden med olika CPU-cacher.
Många gånger stöter vi på problem som vi kanske inte är medvetna om. Vi uppmärksammade inte användningen och rollen för hårdvarans CPU-cache. Men det är avgörande för att välja och uppfylla hårdvarukraven med större databassystem.
Arkitekturmönster
I databasdesign spelar arkitekturmönstret alltid en exemplarisk roll. Tidigare designades databassystem på ett extremt monolitiskt sätt. Nu använder vi Micro-Service-baserad eller hybrid (monolitisk + mikro).
Prestanda, utbyggbarhet och noll driftstopp beror mycket på arkitekturmönstret och databasdesignen. Varje applikation kan ha en separat databas och alla databaser kan kopplas löst med varandra. Om någon applikation eller databas går ner, kommer en annan del av produkten inte att störas. Alla mikrotjänster skulle vara oberoende och löst kopplade.
Mikrotjänst
Diagrammet nedan förklarar hur alla applikationer distribueras och kommunicerar med hjälp av sina databaser, som är löst kopplade samtidigt. Vi kan manipulera data med T-SQL. Informationen kommer att samlas in eller ackumuleras av olika applikationer, och klienten kommer att kunna komma åt data. Se diagrammet med antalet skalade applikationer och dess integrerade databas.
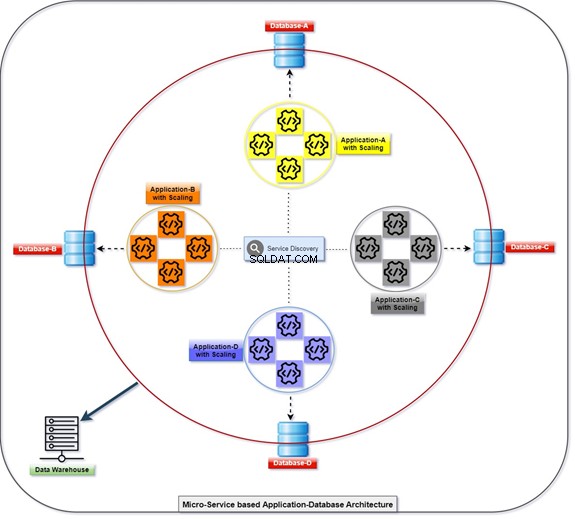
Monolithic
Vilket RDBMS ska vi använda? Det kan vara Oracle, Microsoft SQL Server, Postgres, MySQL, MongoDB eller någon annan databas. Det konventionella sättet att hantera alla tabeller eller objekt som hanteras i enstaka eller flera databaser på en enda server kallas Monolithic.
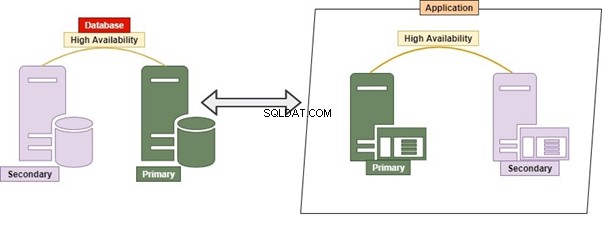
Hybrid
Hybrid är en permutation av Monolithic och Micro Service. Det är ganska vanligt, eftersom det tillåter många applikationer, många databaser och databasservrar. Många databaser och databasservrar kan vara tätt kopplade till varandra.
Till exempel, fråga med JOINs mellan tabeller som tillhör två eller flera databaser i samma databasserver eller olika. Fjärrfråga som används för datahämtning/manipulering med en annan databasserver.
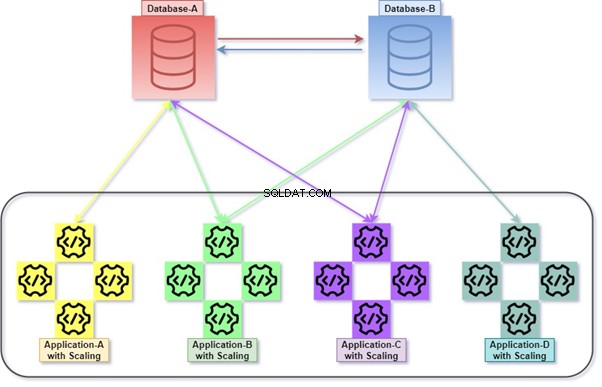
Allt handlar om SQL Server-arkitektur. Men vi talar om datamanipulation mellan olika tabeller inom samma databas eller olika databaser som kan finnas på samma server eller olika servrar.
Antingen i hybrid eller monolitisk arkitektur använder vi JOINs mellan olika tabeller inom samma eller olika databaser. Det är ganska komplicerat när vi följer de grundläggande Micro-Service-standarderna eftersom tabellernas distribution kan ske mellan databastjänsterna (Dbas).
Under Enterprise-databasteknologier som Microsoft SQL Server, Oracle, etc., kunde användaren fråga den distribuerade databasens tabeller med hjälp av Linked Server Joins. Men det är inte tillgängligt i alla databastekniker med öppen källkod. Det är känt som Tight-Coupled-metoden som kanske inte fungerar när fjärrdatabastjänsten inte är tillgänglig.
Låt oss nu diskutera att göra det löst kopplat. Varför behöver vi datamanipulation mellan fjärrdatabaser?
Varför kräver vi datamanipulation mellan fjärrdatabaser?
Användare kommer att kräva att data hämtas från mer än en databastjänst när systemet är designat med hjälp av Micro eller Hybrid Services. Hela processen ses från backend som kan hantera datamängder som manipuleras av applikationen.
När vi tittar på korsdatabasförfrågningar i realtid ansluter vi alltid huvudentitetstabellerna, inte metadatatabellerna. Mastertabellerna kommer inte att vara större än metadatatabeller. För rapporteringsändamål använder vi alltid datalagret för att få ihop all information. Men det är inte lätt att hantera och underhålla för varje produkt. Om vi designar företagslösningen har vi råd med lagret. Men vi har inte råd med det för små eller medelstora produkter.
Till exempel behöver vi en rapport med data från flera tabeller som finns i olika databaser. Det är inte en lätt uppgift att utföra, eftersom den sammanställer data med hjälp av olika mikrotjänster och slår samman den för att producera rapporten. Därför måste nödvändiga data synkroniseras.
Vad kan vi använda som standardlösning göra löskopplade tabelldatasynkronisering mellan två databaser?
Tabellreplikering bör användas för enkel datasynkronisering mellan flera databaser. Exemplet är transaktionsreplikeringen för Simplex datasynkronisering och Merge Replication för Duplex datasynkronisering som tillhandahålls av SQL Server.
Det finns några betalda tredjeparts- och öppen källkodslösningar som kan synkronisera data mellan flera databaser. Även löst kopplade lösningar med hjälp av meddelandeköer som SQL Server Transaction Replication kan utvecklas av användare på egen hand.
Slutsats
DBA:er designar databaser på sitt sätt. När de bygger databasen och väljer databashanteringssystem måste de ha många aspekter i åtanke. Vi presenterade de viktigaste faktorerna för databasdesignen, särskilt för de större databaserna. Håll utkik efter nästa material!