När en exekveringsplan innehåller en skanning av en b-tree indexstruktur, kan lagringsmotorn kunna välja mellan två fysiska åtkomststrategier när planen exekveras:
- Följ index b-trädstrukturen; eller,
- hitta sidor med hjälp av intern sidtilldelningsinformation.
Där ett val är tillgängligt, fattar lagringsmotorn körtidsbeslutet för varje exekvering. En planomkompilering är inte krävs för att den ska ändra sig.
B-trädstrategin börjar vid roten av trädet, sjunker till en ytterkant av bladnivån (beroende på om skanningen är framåt eller bakåt), följer sedan sidlänkar på bladnivå tills den andra änden av indexet nås . Allokeringsstrategin använder Index Allocation Map-strukturer (IAM) för att hitta databassidor som allokerats till indexet. Varje IAM-sida mappar tilldelningar till ett 4GB-intervall i en enda fysisk databasfil, så att genomsökning av IAM-kedjorna som är associerade med ett index tenderar att komma åt indexsidor i fysisk filordning (åtminstone så vitt SQL Server kan säga).
De huvudsakliga skillnaderna mellan de två strategierna är:
- En b-trädskanning kan leverera rader till frågeprocessorn i indexnyckelordning; en IAM-driven skanning kan inte;
- en b-tree-skanning kanske inte kan utfärda stora I/O-förfrågningar om läs framåt om logiskt sammanhängande indexsidor inte också är fysiskt sammanhängande (t.ex. som ett resultat av siddelning i indexet).
En b-trädskanning är alltid tillgänglig för ett index. Villkoren som ofta nämns för att tilldelningsorderskanningar ska vara tillgängliga är:
- Frågeplanen måste tillåta en oordnad genomsökning av indexet;
- indexet måste vara minst 64 sidor stort; och,
- antingen en
TABLOCKellerNOLOCKledtråd måste anges.
Det första villkoret betyder helt enkelt att frågeoptimeraren måste ha markerat skanningen med Ordered:False fast egendom. Markering av skanningen Ordered:False betyder att korrekta resultat från genomförandeplanen inte kräver skanna för att returnera rader i indexnyckelordning (även om det kan göra det om det är lämpligt eller på annat sätt nödvändigt).
Det andra villkoret (storlek) gäller endast för SQL Server 2005 och senare. Det återspeglar det faktum att det finns en viss startkostnad för att utföra en IAM-driven skanning, så det måste finnas ett minsta antal sidor för att de potentiella besparingarna ska kunna betala tillbaka den initiala investeringen. "64 sidor" hänvisar till värdet av data_sidor för IN_ROW_DATA Endast allokeringsenhet, som rapporterats i sys.allocation_units.
Naturligtvis kan det bara finnas en utdelning från en tilldelningsorderskanning om de eventuellt större avläsningarna faktiskt överväger kommer in, men SQL Server tar för närvarande inte hänsyn till denna faktor. I synnerhet tar det inte hänsyn till hur mycket av indexet som för närvarande finns i minnet, och det bryr sig inte heller om hur fragmenterat indexet är.
Det tredje villkoret är förmodligen den minst fullständiga beskrivningen i listan. Tips är faktiskt inte obligatoriska , även om de kan användas för att uppfylla de verkliga kraven:Uppgifterna måste garanteras inte ändras under skanningen, eller (mer kontroversiellt) måste vi indikera att vi inte bryr oss om potentiellt felaktiga resultat, genom att utföra skanningen på isoleringsnivån för läs oengagerad.
Även med dessa förtydliganden är listan över villkor för en tilldelningsbeordrad skanning fortfarande inte komplett. Det finns ett antal viktiga varningar och undantag som vi kommer att komma till inom kort.
Demo
Följande fråga använder exempeldatabasen AdventureWorks:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P; Observera att tabellen Person innehåller 3 869 sidor. Planen efter körning (faktisk) är som följer (visas i SQL Sentry Plan Explorer):
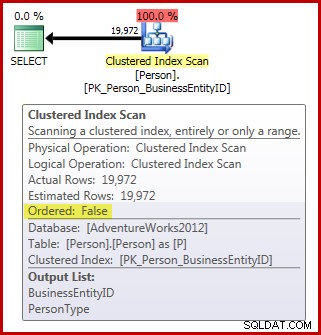
När det gäller allokeringsorderskanningskraven har vi hittills:
- Planet har den obligatoriska
Ordered:Falsefast egendom; och, - tabellen har mer än 64 sidor; men,
- vi har inte gjort något för att säkerställa att data inte kan ändras under skanningen. Förutsatt att vår session använder standardvärdet read committed isoleringsnivå, skanningen utförs inte vid läs oengagerad isoleringsnivå heller.
Som en konsekvens skulle vi förvänta oss att denna skanning utförs genom att skanna b-trädet snarare än att vara IAM-driven. Frågeresultaten indikerar att detta sannolikt är sant:
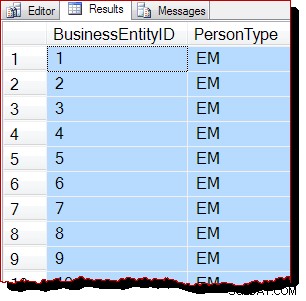
Raderna returneras i Clustered Index-nyckelordning (med BusinessEntityID ). Jag bör tydligt säga att denna resultatordning är absolut inte garanterad , och bör inte förlitas på. Beställda resultat garanteras endast av en lämplig toppnivå ORDER BY klausul.
Icke desto mindre är den observerade utmatningsordningen ett indicier för att skanningen utfördes denna gång genom att följa den klustrade index b-trädstrukturen. Om mer bevis behövs kan vi bifoga en debugger och titta på kodsökvägen som SQL Server exekverar under skanningen:

Anropsstacken visar tydligt skanningen efter b-trädet.
Lägga till en tabelllåstips
Vi modifierar nu frågan så att den inkluderar ett tabelllåstips:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK); På den förinställda isoleringsnivån för läskommitterad låsning förhindrar låset på delad tabellnivå alla möjliga samtidiga modifieringar av data. Med alla tre förutsättningarna för IAM-drivna skanningar uppfyllda skulle vi nu förvänta oss att SQL Server använder en allokeringsorderskanning. Utförandeplanen är densamma som tidigare, så jag kommer inte att upprepa den, men frågeresultaten ser verkligen annorlunda ut:
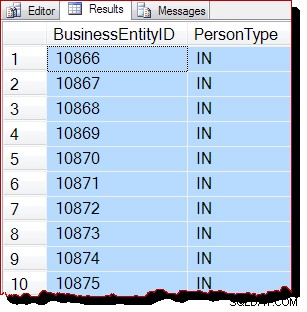
Resultaten är tydligen fortfarande sorterade efter BusinessEntityID , men utgångspunkten (10866) är annorlunda. Faktum är att om vi rullar nedåt i resultaten, stöter vi snart på avsnitt som är mer uppenbart ur nyckelordning:
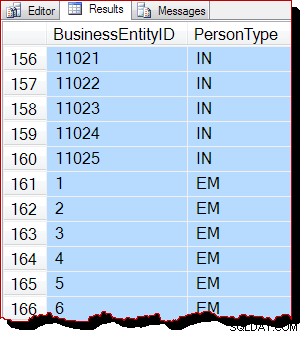
Delbeställningen beror på att allokeringsorderskanningen bearbetar en hel indexsida åt gången. Resultaten inom en sida råkar returneras efter indexnyckeln, men ordningen på de skannade sidorna är nu annorlunda. Återigen, jag bör betona att resultaten kan se annorlunda ut för dig:det finns ingen garanti för utdataordning, inte ens inom en sida, utan en ORDER BY på toppnivån på den ursprungliga frågan.
För jämförelse med anropsstacken som visades tidigare är detta en stackspårning som erhölls medan SQL Server bearbetade frågan med TABLOCK tips:
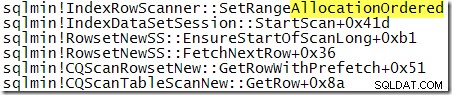
Trampa på lite längre genom utförandet:

Uppenbarligen utför SQL Server en tilldelningsordnad skanning när tabelllåset är specificerat. Det är synd att det inte finns någon indikation i en plan efter genomförandet av vilken typ av skanning som användes under körningen. Som en påminnelse väljs typen av skanning av lagringsmotorn och kan ändras mellan körningar utan en omkompilering av planen.
Andra sätt att uppfylla det tredje villkoret
Jag sa tidigare att för att få en IAM-driven skanning måste vi säkerställa att data inte kan ändras under skanningen medan den pågår, eller så måste vi köra frågan på isoleringsnivån för läs oengagerad. Vi har sett att ett tabelllåstips om att låsa läs-förpliktad isolering är tillräckligt för att uppfylla det första av dessa krav, och det är lätt att visa att man använder en NOLOCK/READUNCOMMITTED hint möjliggör också en allokeringsorderskanning med demofrågan.
Det finns faktiskt många sätt att uppfylla det tredje villkoret, inklusive:
- Ändra indexet för att endast tillåta tabelllås;
- gör databasen skrivskyddad (så att data garanterat inte ändras); eller,
- ändra session isoleringsnivå till
READ UNCOMMITTED.
Det finns dock mycket mer intressanta varianter på detta tema som innebär att vi måste ändra de tre villkoren som nämnts tidigare...
Isoleringsnivåer för radversioner
Aktivera read committed snapshot isolation (RCSI) på AdventureWorks-databasen och kör testet med TABLOCK ledtråd igen (vid läsning av engagerad isolering):
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT ON
WITH ROLLBACK IMMEDIATE;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
GO
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK);
GO
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT OFF
WITH ROLLBACK IMMEDIATE;
Med RCSI aktivt, en indexordnad skanning används med TABLOCK , inte allokeringsorderskanningen vi såg precis innan. Anledningen är TABLOCK ledtråd anger ett delat lås på tabellnivå, men med RCSI aktiverat inga delade lås är tagna. Utan det delade tabelllåset har vi inte uppfyllt kravet att förhindra samtidiga modifieringar av data medan skanningen pågår, så en tilldelningsordnad skanning kan inte användas.
Att uppnå en tilldelningsordnad skanning när RCSI är aktiverat är dock möjligt. Ett sätt är att använda en TABLOCKX tips (för en exklusiv tabellnivå lås) istället för TABLOCK . Vi kan också behålla TABLOCK tips och lägg till ytterligare en som READCOMMITTEDLOCK , eller REPEATABLE READ eller SERIALIZABLE … och så vidare. Alla dessa fungerar genom att förhindra möjligheten till samtidiga ändringar genom att ta ett delat bordslås, till priset av att förlora fördelarna med RCSI . Vi kan också fortfarande uppnå en tilldelningsorderskanning med en NOLOCK eller READUNCOMMITTED ledtråd såklart.
Situationen under ögonblicksbildsisolering (SI) är mycket lik RCSI och utforskas inte i detalj av utrymmesskäl.
TABLESAMPLE utför alltid* en allokeringsorderskanning
TABLESAMPLE klausulen är ett intressant undantag från många av de saker vi har diskuterat hittills.
Ange en TABLESAMPLE klausul alltid* resulterar i en allokeringsordningsskanning, även under RCSI eller SI, och även utan tips. För att vara tydlig med det, skanningen av allokeringsorder som är resultatet av att använda TABLESAMPLE behåller RCSI/SI-semantik – skanningen använder radversioner och läsning blockerar inte skrivning (och vice versa).
En andra överraskning är att TABLESAMPLE utför alltid* en IAM-driven skanning även om tabellen har färre än 64 sidor . Detta är vettigt eftersom dokumentationen åtminstone antyder att SYSTEM samplingsmetoden använder IAM-strukturen (så det finns inget annat val än att göra en allokeringsorderskanning):
SYSTEM Är en implementeringsberoende provtagningsmetod specificerad av ISO-standarder. I SQL Server är detta den enda tillgängliga samplingsmetoden och tillämpas som standard. SYSTEM tillämpar en sidbaserad samplingsmetod där en slumpmässig uppsättning sidor från tabellen väljs för urvalet, och alla rader på dessa sidor returneras som provdelmängden.
* Ett undantag inträffar om ROWS eller PERCENT specifikation i TABLESAMPLE klausul verkar betyda 100 % av tabellen. Ange fler ROWS än vad metadata indikerar finns i tabellen kommer inte heller att fungera. Använder TABLESAMPLE SYSTEM (100 PERCENT) eller motsvarande kommer inte tvinga fram en tilldelningsorderskanning.
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
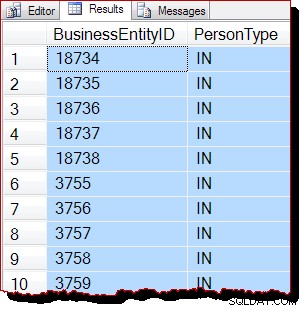
TABLESAMPLE SYSTEM (50 ROWS)
REPEATABLE (12345678)
--WITH (TABLOCK); Resultat:
Effekten av TOP och SET ROWCOUNT
Kort sagt, ingen av dessa har någon effekt på beslutet att använda en tilldelningsorderskanning eller inte. Detta kan tyckas förvånande i fall där det är "uppenbart" att färre än 64 sidor kommer att skannas.
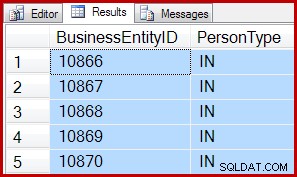
Till exempel använder båda följande frågor en IAM-driven skanning för att returnera 5 rader från en skanning:
SELECT TOP (5)
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 5;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 0; Resultaten är desamma för båda:
Det betyder att TOP och SET ROWCOUNT frågor kanske ådra sig omkostnader för att ställa in en tilldelningsorderskanning, även om färre än 64 sidor skannas. Mer komplexa TOP-frågor med selektiva predikat som skjuts in i skanningen kan fortfarande dra nytta av en allokeringsorderskanning. Om skanningen måste bearbeta 10 000 sidor för att hitta de första 5 raderna som matchar, kan en tilldelningsorderskanning fortfarande vara en vinst.
Förhindra alla* genomsökningar av allokeringsorder över hela instansen
Det här är inte något du förmodligen skulle göra avsiktligt, men det finns en serverinställning som förhindrar genomsökning av allokeringsorder för alla* användarfrågor i alla databaser.
Hur osannolikt det kan verka är inställningen i fråga serverkonfigurationsalternativet för markörtröskeln, som har följande beskrivning i Books Online:
Alternativet för markörtröskel anger antalet rader i marköruppsättningen där markörtangenterna genereras asynkront. När markörer genererar en nyckeluppsättning för en resultatuppsättning, uppskattar frågeoptimeraren antalet rader som kommer att returneras för den resultatuppsättningen. Om frågeoptimeraren uppskattar att antalet returnerade rader är större än detta tröskelvärde, genereras markören asynkront, vilket gör att användaren kan hämta rader från markören medan markören fortsätter att fyllas i. Annars genereras markören synkront och frågan väntar tills alla rader returneras.
Om cursor threshold alternativet är inställt på något annat än –1 (standard), inga tilldelningsordningssökningar kommer att ske för användarfrågor i någon databas på SQL Server-instansen.
Med andra ord, om asynkron markörpopulation är aktiverad, skannar inga IAM-drivna efter dig.
* Undantaget är (icke-100%) TABLESAMPLE frågor. De interna frågorna som genereras av systemet för att skapa statistik och uppdateringar av statistik fortsätter också att använda tilldelningsbeställda skanningar.
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
-- WARNING! Disables allocation-order scans instance-wide
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = 5000;
RECONFIGURE WITH OVERRIDE;
GO
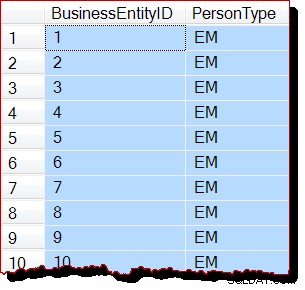
-- Would normally result in an allocation-order scan
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (READUNCOMMITTED);
GO
-- Reset to default allocation-order scans
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = -1;
RECONFIGURE WITH OVERRIDE; Resultat (ingen genomsökning av allokeringsorder):
Man kan bara gissa att asynkron markörpopulation inte fungerar bra med allokeringsordningsskanningar av någon anledning. Det är helt oväntat att denna begränsning skulle påverka alla användares frågor som inte är markörer likaså dock. Det kanske är för svårt för SQL Server att upptäcka om en fråga körs som en del av en externt utfärdad API-markör? Vem vet.
Det skulle vara trevligt om denna bieffekt officiellt dokumenterades någonstans, även om det är svårt att veta exakt var den ska ta vägen i Books Online. Jag undrar hur många produktionssystem där ute som inte använder allokeringsorderskanningar på grund av detta? Kanske inte många, men man vet aldrig.
För att avsluta saker och ting, här är en sammanfattning. En tilldelningsbeställd skanning är tillgänglig om:
- Serveralternativet
cursor thresholdär inställd på –1 (standard); och - Frågeplanens skanningsoperator har
Ordered:Falsefast egendom; och - det totala antalet data_sidor av
IN_ROW_DATAtilldelningsenheter är minst 64; och - antingen:
- SQL Server har en acceptabel garanti för att samtidiga ändringar är omöjliga; eller,
- skanningen körs på isoleringsnivån för läs oengagerad.
Oavsett allt ovan, en skanning med en TABLESAMPLE klausulen använder alltid allokeringsordnade skanningar (med det enda tekniska undantaget som anges i huvudtexten).