Förändringarna i den interna representationen av partitionerade tabeller mellan SQL Server 2005 och SQL Server 2008 resulterade i förbättrade frågeplaner och prestanda i de flesta fall (särskilt när parallell exekvering är inblandad). Tyvärr gjorde samma förändringar att vissa saker som fungerade bra i SQL Server 2005 plötsligt inte fungerade så bra i SQL Server 2008 och senare. Det här inlägget tittar på ett exempel där SQL Server 2005-frågeoptimeraren producerade en överlägsen exekveringsplan jämfört med senare versioner.
Exempeltabell och data
Exemplen i det här inlägget använder följande partitionerade tabell och data:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T4
(
RowID integer IDENTITY NOT NULL,
SomeData integer NOT NULL,
CONSTRAINT PK_T4
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T4 WITH (TABLOCKX)
(SomeData)
SELECT
ABS(CHECKSUM(NEWID()))
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
CREATE NONCLUSTERED INDEX nc1
ON dbo.T4 (SomeData)
ON PS (RowID); Partitionerad datalayout
Vår tabell har ett partitionerat klustrat index. I det här fallet fungerar klustringsnyckeln också som partitioneringsnyckel (även om detta inte är ett krav i allmänhet). Partitionering resulterar i separata fysiska lagringsenheter (raduppsättningar) som frågeprocessorn presenterar för användare som en enda enhet.
Diagrammet nedan visar de tre första partitionerna i vår tabell (klicka för att förstora):
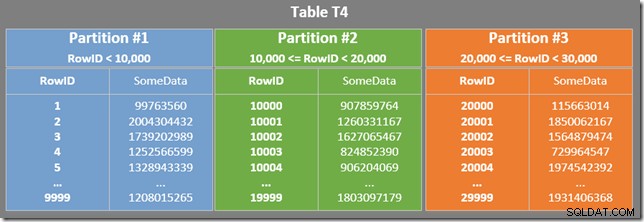
Det icke-klustrade indexet är partitionerat på samma sätt (det är "justerat"):

Varje partition i det icke-klustrade indexet täcker ett intervall av RowID-värden. Inom varje partition sorteras data av SomeData (men RowID-värdena kommer inte att ordnas i allmänhet).
MIN/MAX-problemet
Det är ganska välkänt att MIN och MAX aggregeringar optimerar inte bra på partitionerade tabeller (såvida inte kolumnen som aggregeras också råkar vara partitioneringskolumnen). Denna begränsning (som fortfarande finns i SQL Server 2014 CTP 1) har det skrivits om många gånger under åren; min favoritbevakning finns i den här artikeln av Itzik Ben-Gan. För att kort illustrera problemet, överväg följande fråga:
SELECT MIN(SomeData) FROM dbo.T4;
Exekveringsplanen på SQL Server 2008 eller senare är följande:

Den här planen läser alla 150 000 rader från indexet och ett Stream Aggregate beräknar minimivärdet (exekveringsplanen är i huvudsak densamma om vi begär maxvärdet istället). SQL Server 2005-exekveringsplanen är något annorlunda (men inte bättre):
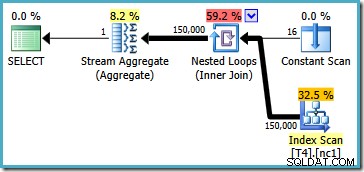
Denna plan itererar över partitionsnummer (anges i Constant Scan) och genomsöker en partition i taget. Alla 150 000 rader läses och bearbetas så småningom av Stream Aggregate.
Titta tillbaka på de partitionerade tabellen och indexdiagrammen och fundera på hur frågan kan bearbetas mer effektivt på vår datamängd. Det icke-klustrade indexet verkar vara ett bra val för att lösa frågan eftersom det innehåller SomeData-värden i en ordning som kan utnyttjas vid beräkning av aggregatet.
Nu, det faktum att indexet är partitionerat komplicerar saken lite:varje partition av indexet sorteras efter SomeData-kolumnen, men vi kan inte bara läsa det lägsta värdet från någon specifik partition för att få rätt svar på hela frågan.
När man väl har förstått problemets väsentliga natur kan en människa se att en effektiv strategi skulle vara att hitta det enskilt lägsta värdet av SomeData i varje partition av indexet och ta sedan det lägsta värdet från resultaten per partition.
Detta är i huvudsak lösningen som Itzik presenterar i sin artikel; skriv om frågan för att beräkna en aggregerad per-partition (med APPLY syntax) och aggregera sedan igen över dessa resultat per partition. Med den metoden, den omskrivna MIN query producerar denna exekveringsplan (se Itziks artikel för den exakta syntaxen):
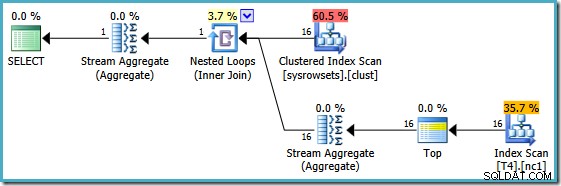
Denna plan läser partitionsnummer från en systemtabell och hämtar det lägsta värdet av SomeData i varje partition. Det slutliga Stream Aggregatet beräknar bara minimum över resultaten per partition.
Den viktiga egenskapen i denna plan är att den läser en en rad från varje partition (utnyttjar sorteringsordningen för indexet inom varje partition). Det är mycket effektivare än optimerarens plan som behandlade alla 150 000 rader i tabellen.
MIN och MAX inom en enda partition
Överväg nu följande fråga för att hitta minimivärdet i kolumnen SomeData, för ett intervall av RowID-värden som finns inom en enda partition :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 18000;
Vi har sett att optimeraren har problem med MIN och MAX över flera partitioner, men vi förväntar oss att dessa begränsningar inte gäller för en enskild partitionsfråga.
Den enskilda partitionen är den som begränsas av RowID-värdena 10 000 och 20 000 (se tillbaka till definitionen av partitioneringsfunktionen). Partitioneringsfunktionen definierades som RANGE RIGHT , så 10 000-gränsvärdet tillhör partition #2 och 20 000-gränsen tillhör partition #3. Omfånget av RowID-värden som specificeras av vår nya fråga finns därför enbart inom partition 2.
De grafiska exekveringsplanerna för den här frågan ser likadana ut på alla SQL Server-versioner från 2005 och framåt:
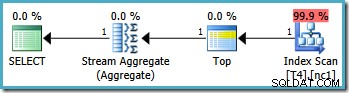
Plananalys
Optimeraren tog RowID-intervallet som anges i WHERE och jämförde den med partitionsfunktionsdefinitionen för att fastställa att endast partition 2 i det icke-klustrade indexet behövde nås. SQL Server 2005-planens egenskaper för Index Scan visar åtkomsten till en enpartition tydligt:
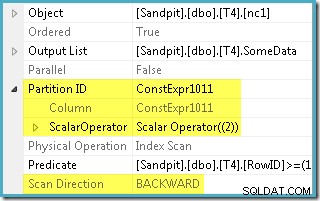
Den andra markerade egenskapen är Scan Direction. Genomsökningsordningen varierar beroende på om frågan söker efter det lägsta eller högsta SomeData-värdet. Det icke-klustrade indexet är ordnat (per partition, kom ihåg) på stigande SomeData-värden, så riktningen för indexsökning är FORWARD om frågan frågar efter minimivärdet och BACKWARD om det maximala värdet behövs (skärmdumpen ovan togs från MAX). frågeplan).
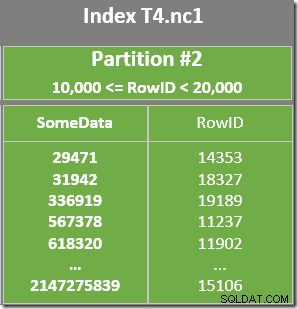
Det finns också ett kvarvarande predikat på Index Scan för att kontrollera att RowID-värdena som skannats från partition 2 matchar WHERE klausulpredikat. Optimizern antar att RowID-värden distribueras ganska slumpmässigt genom det icke-klustrade indexet, så den förväntar sig att hitta den första raden som matchar WHERE klausulpredikat ganska snabbt. Det partitionerade datalayoutdiagrammet visar att RowID-värdena verkligen är ganska slumpmässigt fördelade i indexet (som sorteras efter SomeData-kolumnen kom ihåg):
Topoperatorn i frågeplanen begränsar indexskanningen till en enda rad (från antingen den nedre eller övre delen av indexet beroende på skanningsriktningen). Indexskanningar kan vara problematiska i frågeplaner, men Top-operatören gör det till ett effektivt alternativ här:skanningen kan bara producera en rad, sedan slutar den. Kombinationen av Top och Order Index Scan utför effektivt en sökning till det högsta eller lägsta värdet i indexet som också matchar WHERE klausulpredikat. Ett Stream Aggregate visas också i planen för att säkerställa att en NULL genereras om inga rader returneras av Index Scan. Skalär MIN och MAX aggregat definieras för att returnera en NULL när ingången är en tom uppsättning.
Sammantaget är detta en mycket effektiv strategi, och planerna har en uppskattad kostnad på bara 0,0032921 enheter som ett resultat. Så långt har det gått bra.
Gränsvärdeproblemet
Detta nästa exempel ändrar den övre delen av RowID-intervallet:
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000;
Observera att frågan utesluter värdet på 20 000 genom att använda en "mindre än"-operator. Kom ihåg att värdet 20 000 tillhör partition 3 (inte partition 2) eftersom partitionsfunktionen är definierad som RANGE RIGHT . SQL Server2005 Optimizer hanterar den här situationen på rätt sätt och producerar den optimala frågeplanen med en enda partition, med en uppskattad kostnad på 0,0032878 :
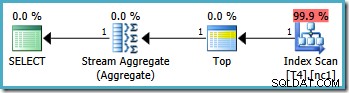
Men samma fråga ger en annan plan på SQL Server2008 och senare (inklusive SQL Server 2014 CTP 1):
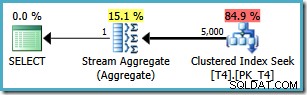
Nu har vi en Clustered Index Seek (istället för den önskade Index Scan och Top-operatörskombinationen). Alla 5 000 rader som matchar WHERE klausulen bearbetas genom Stream Aggregate i denna nya exekveringsplan. Den beräknade kostnaden för denna plan är 0,0199319 enheter – mer än sex gånger kostnaden för SQL Server 2005-planen.
Orsak
SQL Server 2008 (och senare) optimerare får inte riktigt den interna logiken rätt när ett intervall refererar, men exkluderar , ett gränsvärde som tillhör en annan partition. Optimizern tror felaktigt att flera partitioner kommer att nås och drar slutsatsen att den inte kan använda enpartitionsoptimeringen för MIN och MAX aggregat.
Lösningar
Ett alternativ är att skriva om frågan med operatorerna>=och <=så att vi inte refererar till ett gränsvärde från en annan partition (även för att utesluta det!):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID <= 19999;
Detta resulterar i den optimala planen, genom att trycka på en enda partition:
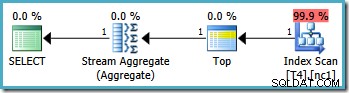
Tyvärr är det inte alltid möjligt att ange korrekta gränsvärden på detta sätt (beroende på typen av partitioneringskolumn). Ett exempel på det är med datum- och tidstyper där det är bäst att använda halvöppna intervaller. En annan invändning mot denna lösning är mer subjektiv:partitioneringsfunktionen utesluter en gräns från intervallet, så det verkar mest naturligt att skriva frågan också med halvöppen intervallsyntax.
En andra lösning är att ange partitionsnumret explicit (och behålla halvöppet intervall):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000 AND $PARTITION.PF(RowID) = 2;
Detta ger den optimala planen, till den dyra kostnaden att kräva ett extra predikat och förlita sig på att användaren räknar ut vad partitionsnumret ska vara.
Naturligtvis skulle det vara bättre om optimerarna från 2008 och senare producerade samma optimala plan som SQL Server 2005 gjorde. I en perfekt värld skulle en mer omfattande lösning också ta itu med flerpartitionsfallet, vilket gör den lösning som Itzik beskriver också onödig.