Index är hastighetshöjare i SQL-databaser. De kan vara klustrade eller icke-klustrade. Men vad betyder det och var ska du ansöka var och en?
Jag känner igen den här känslan. Jag har varit där. Nybörjare är ofta förvirrade över vilket index som ska användas på vilka kolumner. Men även experter måste tänka igenom denna fråga innan de fattar ett beslut, och olika situationer kräver olika beslut. Som du kommer att se senare finns det frågor där ett klustrat index kommer att lysa jämfört med ett icke-klustrat index, och vice versa.
Ändå, först måste vi känna till var och en av dem. Om du letar efter samma information är idag din lyckodag.
Den här artikeln kommer att berätta vad dessa index är och när du ska använda var och en. Självklart kommer det att finnas kodexempel som du kan prova i praktiken. Så ta dina chips eller pizza och lite läsk eller kaffe och gör dig redo att fördjupa dig i denna insiktsfulla resa.
Klar?
Vad är Clustered Index
Ett klustrat index är ett index som definierar den fysiska sorteringsordningen för rader i en tabell eller vy.
För att se detta i verklig form, låt oss ta Anställd tabellen i AdventureWorks2017 databas.
Den primära nyckeln är också ett klustrat index, och nyckeln är baserad på BusinessEntityID kolumn. När du gör en SELECT på den här tabellen utan en ORDER BY, kommer du att se att den är sorterad efter primärnyckeln.
Prova själv med koden nedan:
USE AdventureWorks2017
GO
SELECT TOP 10 * FROM HumanResources.Employee
GO
Se nu resultatet i figur 1:
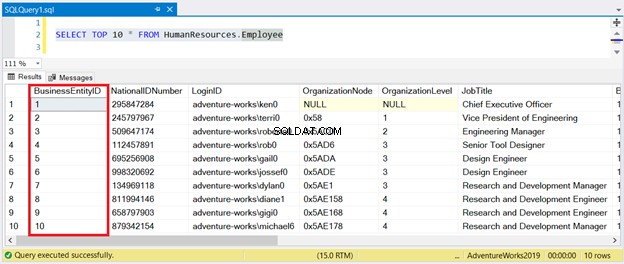
Som du kan se behöver du inte sortera resultatuppsättningen med BusinessEntityID . Det klustrade indexet tar hand om det.
Till skillnad från icke-klustrade index kan du bara ha 1 klustrade index per tabell. Vad händer om vi provar detta på anställd bord?
CREATE CLUSTERED INDEX IX_Employee_NationalID
ON HumanResources.Employee (NationalIDNumber)
GO
Vi har ett liknande fel nedan:
Msg 1902, Level 16, State 3, Line 4
Cannot create more than one clustered index on table 'HumanResources.Employee'. Drop the existing clustered index 'PK_Employee_BusinessEntityID' before creating another.
När ska man använda ett klusterindex?
En kolumn är den bästa kandidaten för ett klustrat index om något av följande är sant:
- Det används i ett stort antal frågor i WHERE-satsen och joins.
- Den kommer att användas som en främmande nyckel till en annan tabell, och i slutändan för att ansluta.
- Unika kolumnvärden.
- Det är mindre sannolikt att värdet ändras.
- Den kolumn används för att fråga ett värdeintervall. Operatorer som>, <,>=, <=eller BETWEEN används med kolumnen i WHERE-satsen.
Men klustrade index är inte bra om kolumnen eller kolumnerna
- byter ofta
- är breda tangenter eller en kombination av kolumner med en stor nyckelstorlek.
Exempel
Klustrade index kan skapas med hjälp av T-SQL-kod eller valfritt SQL Server GUI-verktyg. Du kan göra det i T-SQL när tabell skapas, så här:
CREATE TABLE [Person].[Person](
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL,
[Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC
)
GO
Eller så kan du göra detta med ALTER TABLE efter skapa tabellen utan ett klustrat index:
ALTER TABLE Person.Person ADD CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED (BusinessEntityID)
GO
Ett annat sätt är att använda CREATE CLUSTERED INDEX:
CREATE CLUSTERED INDEX [PK_Person_BusinessEntityID] ON Person.Person (BusinessEntityID)
GO
Ett annat alternativ är att använda ett SQL Server-verktyg som SQL Server Management Studio eller dbForge Studio för SQL Server.
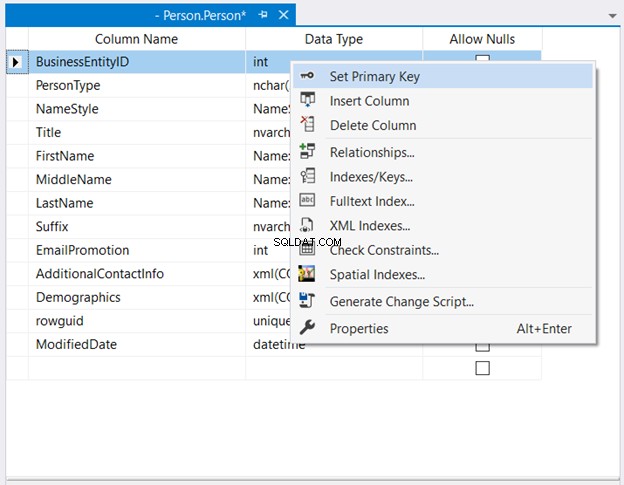
I Objektutforskaren , expandera databasen och tabellnoderna. Högerklicka sedan på önskad tabell och välj Design . Högerklicka slutligen på den kolumn du vill ska vara primärnyckel> Ange primärnyckel > Spara ändringarna i tabellen.
Bild 2 nedan visar var BusinessEntityID är inställd som primärnyckel.
Förutom att skapa ett klustrat index med en kolumn kan du använda flera kolumner. Se ett exempel i T-SQL:
CREATE CLUSTERED INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person]
(
[LastName] ASC,
[FirstName] ASC,
[MiddleName] ASC
)
GO
Efter att ha skapat detta klustrade index, Personen Tabellen kommer att sorteras fysiskt efter Efternamn , Förnamn och Mellannamn .
En av fördelarna med detta tillvägagångssätt är förbättrad frågeprestanda baserat på namnet. Dessutom sorterar den resultat efter namn utan att specificera ORDER BY. Men observera att om namnet ändras måste tabellen omarrangeras. Även om detta inte kommer att hända varje dag, kan effekten bli enorm om bordet är mycket stort.
Vad är icke-klustrade index
Ett icke-klustrat index är ett index med en nyckel och en pekare till raderna eller de klustrade indexnycklarna. Detta index kan gälla både tabeller och vyer.
Till skillnad från klustrade index är strukturen här separat från tabellen. Eftersom den är separat behöver den en pekare till tabellraderna, även kallad radlokalisering. Således innehåller varje post i ett icke-klustrat index en lokalisering och ett nyckelvärde.
Icke-klustrade index sorterar inte tabellen fysiskt baserat på nyckeln.
Indexnycklar för icke-klustrade index har en maximal storlek på 1700 byte. Du kan kringgå denna gräns genom att lägga till inkluderade kolumner. Den här metoden är bra om din fråga behöver täcka fler kolumner utan att öka nyckelstorleken.
Du kan också skapa filtrerade icke-klustrade index. Detta kommer att minska indexunderhållskostnaderna och lagringen samtidigt som frågeprestanda förbättras.
När ska man använda ett icke-klustrat index?
En kolumn eller kolumner är bra kandidater för icke-klustrade index om följande är sant:
- Kolumnen eller kolumnerna används i en WHERE-sats eller join.
- Frågan kommer inte att returnera en stor resultatuppsättning.
- Den exakta matchningen i WHERE-satsen med hjälp av likhetsoperatorn behövs.
Exempel
Detta kommando kommer att skapa ett unikt, icke-klustrat index i Anställd tabell:
CREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber] ON [HumanResources].[Employee]
(
[NationalIDNumber] ASC
)
GO
Bortsett från en tabell kan du skapa ett icke-klustrat index för en vy:
CREATE NONCLUSTERED INDEX [IDX_vProductAndDescription_ProductModel] ON [Production].[vProductAndDescription]
(
[ProductModel] ASC
)
GO
Andra vanliga frågor och tillfredsställande svar
Vilka är skillnaderna mellan klustrade och icke-klustrade index?
Från det du såg tidigare kan du redan bilda dig idéer om hur olika klustrade och icke-klustrade index är. Men låt oss ha det på ett bord för enkel referens.
| Information | Klustrat index | Icke-klustrat index |
| Gäller för | Tabell och vyer | Tabell och vyer |
| Tillåten per tabell | 1 | 999 |
| Nyckelstorlek | 900 byte | 1700 byte |
| Kolumner per indexnyckel | 32 | 32 |
| Bra för | Räckviddsfrågor (>,<,>=, <=, MELLAN) | Exakta matchningar (=) |
| Icke-nyckelinkluderade kolumner | Inte tillåtet | Tillåtet |
| Filter med villkor | Inte tillåtet | Tillåtet |
Ska primärnycklar vara klustrade eller icke-klustrade index?
En primärnyckel är en begränsning. När du gör en kolumn till en primärnyckel, skapas ett klustrat index automatiskt av den, såvida inte ett befintligt klustrat index redan finns på plats.
Blanda inte ihop en primärnyckel med ett klustrat index! En primärnyckel kan också vara den klustrade indexnyckeln. Men en klustrad indexnyckel kan vara en annan kolumn än primärnyckeln.
Låt oss ta ett annat exempel. I Person tabell över AdventureWorks201 7 har vi BusinessEntityID primärnyckel. Det är också den klustrade indexnyckeln. Du kan ta bort det klustrade indexet. Skapa sedan ett klustrat index baserat på Efternamn , Förnamn och Mellannamn . Den primära nyckeln är fortfarande BusinessEntityID kolumn.
Men ska dina primärnycklar alltid vara klustrade?
Det beror på. Gå tillbaka till frågan om när ett klustrat index ska användas.
Om en kolumn eller kolumner förekommer i din WHERE-sats i många frågor, är detta en kandidat för ett klustrat index. Men en annan faktor är hur bred den klustrade indexnyckeln är. För bred – och storleken på varje icke-klustrat index kommer att öka om de finns. Kom ihåg att icke-klustrade index också använder den klustrade indexnyckeln som en pekare. Så håll din klustrade indexnyckel så smal som möjligt.
Om ett stort antal frågor använder primärnyckeln i WHERE-satsen, lämna den också som den klustrade indexnyckeln. Om inte, skapa din primärnyckel som ett icke-klustrat index.
Men vad händer om du fortfarande är osäker? Sedan kan du bedöma prestandafördelarna med en kolumn när den är klustrad eller icke-klustrad. Så lyssna på nästa avsnitt om det.
Vilket är snabbare:klustrade eller icke-klustrade index?
Bra fråga. Det finns ingen generell regel. Du måste kontrollera de logiska läsningarna och exekveringsplanen för dina frågor.
Vårt korta experiment kommer att inkludera kopior av följande tabeller från AdventureWorks2017 databas:
- Person
- BusinessEntityAddress
- Adress
- Adresstyp
Här är manuset:
IF NOT EXISTS(SELECT name FROM sys.databases WHERE name = 'TestDatabase')
BEGIN
CREATE DATABASE TestDatabase
END
USE TestDatabase
GO
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkClustered FROM AdventureWorks2017.Person.Person
ALTER TABLE Person_pkClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID2] PRIMARY KEY CLUSTERED (BusinessEntityID)
CREATE NONCLUSTERED INDEX [IX_Person_Name2] ON Person_pkClustered (LastName, FirstName, MiddleName, Suffix)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkNonClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkNonClustered FROM AdventureWorks2017.Person.Person
CREATE CLUSTERED INDEX [IX_Person_Name1] ON Person_pkNonClustered (LastName, FirstName, MiddleName, Suffix)
ALTER TABLE Person_pkNonClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID1] PRIMARY KEY NONCLUSTERED (BusinessEntityID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'AddressType')
BEGIN
SELECT * INTO AddressType FROM AdventureWorks2017.Person.AddressType
ALTER TABLE AddressType
ADD CONSTRAINT [PK_AddressType] PRIMARY KEY CLUSTERED (AddressTypeID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Address')
BEGIN
SELECT * INTO Address FROM AdventureWorks2017.Person.Address
ALTER TABLE Address
ADD CONSTRAINT [PK_Address] PRIMARY KEY CLUSTERED (AddressID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'BusinessEntityAddress')
BEGIN
SELECT * INTO BusinessEntityAddress FROM AdventureWorks2017.Person.BusinessEntityAddress
ALTER TABLE BusinessEntityAddress
ADD CONSTRAINT [PK_BusinessEntityAddress] PRIMARY KEY CLUSTERED (BusinessEntityID, AddressID, AddressTypeID)
END
GO
Med hjälp av strukturen ovan kommer vi att jämföra frågehastigheter för klustrade och icke-klustrade index.
Vi har 2 exemplar av Personen tabell. Den första kommer att använda BusinessEntityID som den primära och klustrade indexnyckeln. Den andra använder fortfarande BusinessEntityID som primärnyckel. Det klustrade indexet är baserat på Efternamn , Förnamn , Mellannamn och Suffix .
Låt oss börja.
FÖRFRÅGA EXAKTA MATCHAR BASERADE PÅ EFTERNAMNET
Låt oss först ha en enkel fråga. Behöver också aktivera STATISTICS IO. Sedan klistrar vi in resultaten i statistikparser.com för en tabellpresentation.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, p.Title
FROM Person_pkClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SET STATISTICS IO OFF
GO
Förväntningen är att den första SELECT kommer att vara långsammare eftersom WHERE-satsen inte matchar den klustrade indexnyckeln. Men låt oss kontrollera de logiska läsningarna.
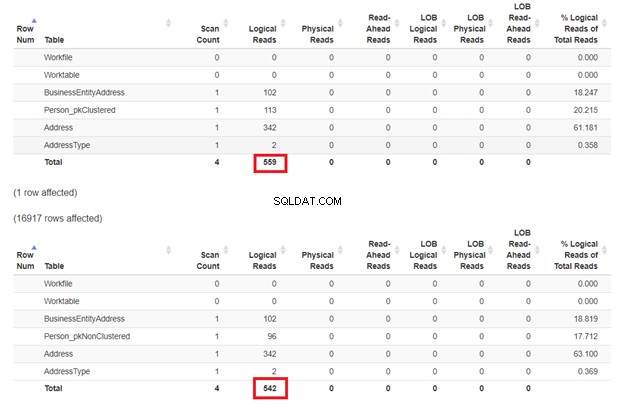
Som förväntat i figur 3, Person_pkClustered hade mer logiska läsningar. Därför behöver frågan mer I/O. Anledningen? Tabellen är sorterad efter BusinessEntityID . Ändå har den andra tabellen det klustrade indexet baserat på namnet. Eftersom frågan vill ha ett resultat baserat på namnet, Person_pkNonClustered vinner. Ju mindre logiska läsningar, desto snabbare är frågan.
Vad mer är på gång? Kolla in figur 4.
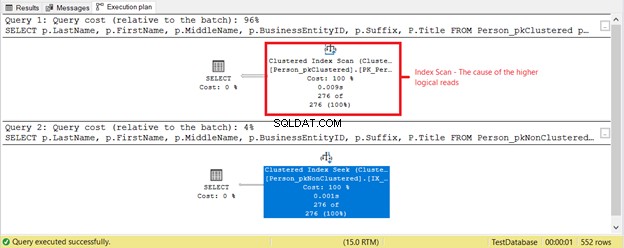
Något annat hände baserat på exekveringsplanen i figur 4. Varför finns en Clustered Index Scan i den första SELECT istället för en Index Seek? Boven är Titel kolumnen i SELECT. Det täcks inte av något av de befintliga indexen. SQL Server Optimizer ansåg att det var snabbare att använda det klustrade indexet baserat på BusinessEntityID. Sedan skannade SQL Server efter rätt efternamn och fick förnamn, mellannamn och titel.
Ta bort titeln kolumnen och operatorn som används kommer att vara Indexsökning . Varför? Eftersom resten av fälten täcks av det icke-klustrade indexet baserat på Efternamn , Förnamn , Mellannamn och Suffix . Den innehåller även BusinessEntityID som den klustrade indexnyckeln.
OMRÅDESFRÅGA BASERAD PÅ FÖRETAGSENS ID
Klustrade index kan vara bra för intervallfrågor. Är det alltid så? Låt oss ta reda på det genom att använda koden nedan.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SET STATISTICS IO OFF
GO
Listan behöver rader baserade på en rad BusinessEntityIDs från 285 till 290. Återigen är de klustrade och icke-klustrade indexen för de två tabellerna intakta. Låt oss nu ha de logiska läsningarna i figur 5. Den förväntade vinnaren är Person_pkClustered eftersom primärnyckeln också är den klustrade indexnyckeln.

Ser du lägre logiska läsningar på Person_pkClustered ? Klustrade index visade sitt värde på intervallfrågor i det här scenariot. Låt oss se vad mer genomförandeplanen kommer att avslöja i figur 6.
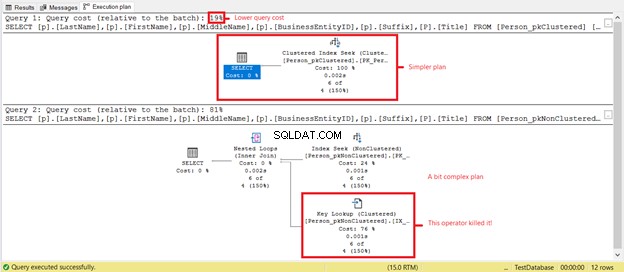
Den första SELECT har en enklare plan och lägre frågekostnad baserat på figur 7. Detta stöder också lägre logiska läsningar. Under tiden har den andra SELECT en Key Lookup-operator som saktar ner frågan. Den skyldige? Återigen är det Titel kolumn. Ta bort kolumnen i frågan eller lägg till den som en Inkluderad kolumn i det icke-klustrade indexet. Då får du en bättre plan och lägre logiska läsningar.
FÖRFRÅGA EXAKT MATCHAR MED EN JOIN
Många SELECT-satser inkluderar joins. Låt oss ta några tester. Här börjar vi med exakta matchningar:
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SET STATISTICS IO OFF
GO
Vi förväntar oss att den andra SELECT från Person_pkNonClustered med ett klustrat index på namnet kommer det att ha mindre logiska läsningar. Men är det? Se figur 7.
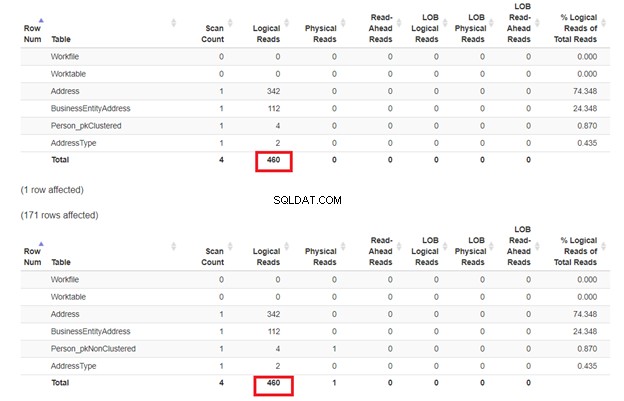
Det verkar som om det icke-klustrade indexet på namnet fungerade bra. De logiska läsningarna är desamma. Om du kontrollerar exekveringsplanen är skillnaden i operatorerna Clustered Index Seek på Person_pkNonClustered , och indexsökningen på Person_pkClustered .
Så vi måste kontrollera de logiska läsningarna och exekveringsplanen för att vara säkra.
OMRÅDESFRÅGA MED JOINS
Eftersom våra förväntningar kan skilja sig från verkligheten, låt oss prova det med intervallfrågor. Klustrade index är i allmänhet bra med det. Men vad händer om du inkluderar en koppling?
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SET STATISTICS IO OFF
GO
Inspektera nu de logiska läsningarna av dessa två frågor i figur 8:
Vad har hänt? I figur 9 biter verkligheten på Person_pkClustered . Mer I/O-kostnader observerades i den jämfört med Person_pkNonClustered . Det är annorlunda än vad vi förväntar oss. Men baserat på detta forumsvar kan en icke-klustrad indexsökning vara snabbare än klustrad indexsökning när alla kolumner i frågan är 100% täckta i indexet. I vårt fall är frågan för Person_pkNonClustered täckte kolumnerna med det icke-klustrade indexet (BusinessEntityID – nyckel; Efternamn , Förnamn , Mellannamn , Suffix – pekare till klustrad indexnyckel).
INFOGA PRESTANDA
Försök sedan att testa INSERT-prestanda över samma tabeller.
SET STATISTICS IO ON
GO
INSERT INTO Person_pkClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
INSERT INTO Person_pkNonClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
SET STATISTICS IO OFF
GO
Figur 9 visar INSERT logiska läsningar:

Båda genererade samma I/O. Båda utförde alltså samma sak.
RADERA PRESTANDA
Vårt senaste test involverar DELETE:
SET STATISTICS IO ON
GO
DELETE FROM Person_pkClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
DELETE FROM Person_pkNonClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
SET STATISTICS IO OFF
GO
Figur 10 visar de logiska avläsningarna. Notera skillnaden.

Varför har vi högre logiska läsningar på Person_pkClustered ? Saken är att DELETE-satsvillkoret är baserat på en exakt matchning av ett namn. Optimeraren måste först ta till det icke-klustrade indexet. Det betyder mer I/O. Låt oss bekräfta med exekveringsplanen i figur 11.
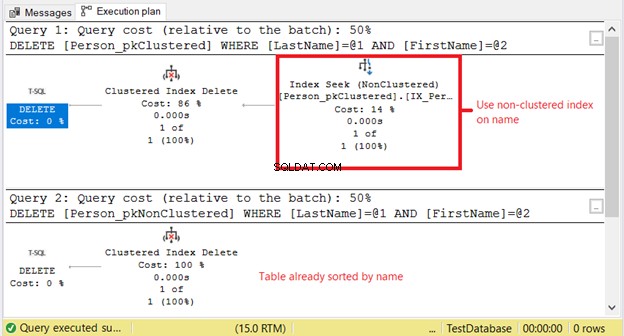
Den första SELECT behöver en indexsökning på det icke-klustrade indexet. Anledningen är WHERE-satsen på Efternamn och Förnamn . Under tiden Person_pkNonClustered är redan fysiskt sorterad efter namn på grund av det klustrade indexet.
Hämtmat
Att skapa högpresterande frågor handlar inte om tur. Du kan inte bara sätta ett klustrat och ett icke-klustrat index och sedan plötsligt har dina frågor hastighetskraften. Du måste fortsätta använda verktygen som din lins för att fokusera på de små detaljerna förutom resultatet.
Men ibland har man helt enkelt inte tid att göra allt detta. Jag tror att det är normalt. Men så länge du inte bråkar så mycket har du ditt jobb nästa dag och du kan fixa det. Detta kommer inte att vara lätt till en början. Det blir faktiskt förvirrande. Du kommer också att ha många frågor. Men med konstant övning kan du uppnå det. Så håll hakan uppe.
Kom ihåg att både klustrade och icke-klustrade index är till för att öka frågor. Att känna till de viktigaste skillnaderna, användningsscenarierna och verktygen hjälper dig i din strävan efter att koda högpresterande frågor.
Jag hoppas att det här inlägget svarar på dina mest angelägna frågor om klustrade och icke-klustrade index. Har du något mer att tillägga för våra läsare? Kommentarsektionen är öppen.
Och om du tycker att det här inlägget är upplysande, vänligen dela det på dina favoritplattformar för sociala medier.
Mer information om index och frågeprestanda finns i artiklarna nedan:
- 22 fiffiga SQL-indexexempel för att förvränga dina frågor
- SQL-frågeoptimering:5 kärnfakta för att öka dina frågor