Tabellpartitionering i SQL Server är i huvudsak ett sätt att få flera fysiska tabeller (raduppsättningar) att se ut som en enda tabell. Denna abstraktion utförs helt av frågeprocessorn, en design som gör det enklare för användarna, men som ställer komplexa krav på frågeoptimeraren. Det här inlägget tittar på två exempel som överträffar optimerarens förmågor i SQL Server 2008 och framåt.
Gå med i Column Order Matters
Detta första exempel visar hur textordningen ON klausulvillkor kan påverka frågeplanen som skapas när partitionerade tabeller sammanfogas. Till att börja med behöver vi ett partitioneringsschema, en partitioneringsfunktion och två tabeller:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T1
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T1
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
);
CREATE TABLE dbo.T2
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T2
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
); Därefter laddar vi båda tabellerna med 150 000 rader. Uppgifterna spelar inte så stor roll; det här exemplet använder en standardtabell med nummer som innehåller alla heltalsvärden från 1 till 150 000 som datakälla. Båda tabellerna är laddade med samma data.
INSERT dbo.T1 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
INSERT dbo.T2 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
Vår testfråga utför en enkel inre sammanfogning av dessa två tabeller. Återigen, frågan är inte viktig eller avsedd att vara särskilt realistisk, den används för att visa en udda effekt när man går med i partitionerade tabeller. Den första formen av frågan använder en ON klausul skriven i c3, c2, c1 kolumnordning:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1; Exekveringsplanen som skapats för den här frågan (på SQL Server 2008 och senare) har en parallell hash-join, med en uppskattad kostnad på 2,6953 :
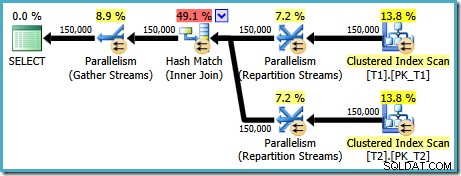
Det här är lite oväntat. Båda tabellerna har ett klustrat index i (c1, c2, c3) ordning, partitionerat med c1, så vi förväntar oss en sammanfogning, som drar fördel av indexordningen. Låt oss försöka skriva ON sats i (c1, c2, c3) ordning istället:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c1 = t2.c1
AND t1.c2 = t2.c2
AND t1.c3 = t2.c3; Utförandeplanen använder nu den förväntade sammanfogningen, med en beräknad kostnad på 1,64119 (ned från 2,6953 ). Optimeraren avgör också att det inte är värt att använda parallell körning:
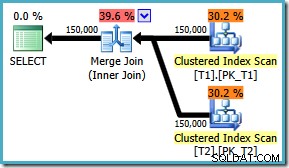
Med tanke på att sammanfogningsplanen är klart mer effektiv, kan vi försöka tvinga fram en sammanfogning för den ursprungliga ON satsordning med hjälp av en frågetips:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (MERGE JOIN); Den resulterande planen använder en sammanfogning enligt begäran, men den har också sorteringar på båda ingångarna och går tillbaka till att använda parallellism. Den beräknade kostnaden för denna plan är en jättestor 8,71063 :
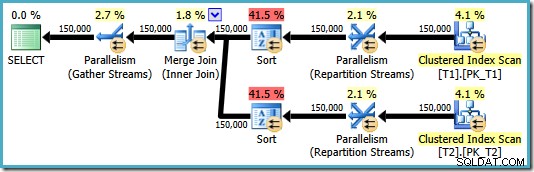
Båda sorteringsoperatorerna har samma egenskaper:
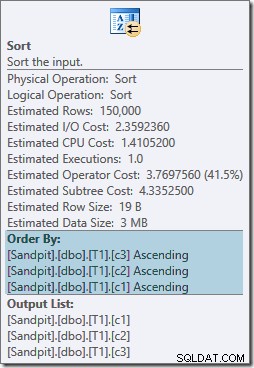
Optimeraren tror att sammanslagningen behöver sina indata sorterade i strikt skrivordning ON klausul, vilket innebär att explicita sorteringar införs. Optimeraren är medveten om att en merge join kräver att dess inmatningar sorteras på samma sätt, men den vet också att kolumnordningen inte spelar någon roll. Merge join on (c1, c2, c3) är lika nöjd med ingångar sorterade på (c3, c2, c1) som med ingångar sorterade på (c2, c1, c3) eller någon annan kombination.
Tyvärr bryts detta resonemang i frågeoptimeraren när partitionering är inblandat. Det här är ett optimeringsfel som har åtgärdats i SQL Server 2008 R2 och senare, även om spårningsflagga 4199 krävs för att aktivera fixen:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (QUERYTRACEON 4199);
Du skulle normalt aktivera denna spårningsflagga med DBCC TRACEON eller som ett startalternativ, eftersom QUERYTRACEON ledtråden är inte dokumenterad för användning med 4199. Spårningsflaggan krävs i SQL Server 2008 R2, SQL Server 2012 och SQL Server 2014 CTP1.
Hur som helst, hur än flaggan är aktiverad, producerar frågan nu den optimala sammanfogningen oavsett ON klausulordning:
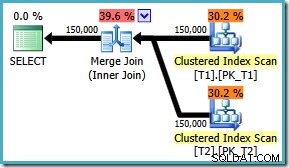
Det finns ingen fix för SQL Server 2008 , lösningen är att skriva ON klausul i "rätt" ordning! Om du stöter på en fråga som denna på SQL Server 2008, försök att tvinga fram en sammanfogning och titta på sorteringen för att avgöra det "rätta" sättet att skriva din frågas ON klausul.
Det här problemet uppstår inte i SQL Server 2005 eftersom den versionen implementerade partitionerade frågor med APPLY modell:

SQL Server 2005-frågeplanen sammanfogar en partition från varje tabell åt gången, med hjälp av en tabell i minnet (Constant Scan) som innehåller partitionsnummer att bearbeta. Varje partition sammanfogas separat på insidan av sammanfogningen, och 2005-optimeraren är smart nog att se att ON satsens kolumnordning spelar ingen roll.
Den senaste planen är ett exempel på en samlokaliserad sammanfogning , en funktion som gick förlorad när man flyttade från SQL Server 2005 till den nya partitioneringsimplementeringen i SQL Server 2008. Ett förslag om Connect för att återställa sammanslagna sammanslagningar har stängts eftersom Won’t Fix.
Grupp efter order ärenden
Den andra egenheten jag vill titta på följer ett liknande tema, men relaterar till ordningen på kolumner i en GROUP BY satsen snarare än ON klausul av en inre sammanfogning. Vi kommer att behöva en ny tabell för att visa:
CREATE TABLE dbo.T3
(
RowID integer IDENTITY NOT NULL,
UserID integer NOT NULL,
SessionID integer NOT NULL,
LocationID integer NOT NULL,
CONSTRAINT PK_T3
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T3 WITH (TABLOCKX)
(UserID, SessionID, LocationID)
SELECT
ABS(CHECKSUM(NEWID())) % 50,
ABS(CHECKSUM(NEWID())) % 30,
ABS(CHECKSUM(NEWID())) % 10
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000; Tabellen har ett justerat icke-klustrat index, där "aligned" helt enkelt betyder att den är uppdelad på samma sätt som det klustrade indexet (eller heapen):
CREATE NONCLUSTERED INDEX nc1 ON dbo.T3 (UserID, SessionID, LocationID) ON PS (RowID);
Vår testfråga grupperar data över de tre icke-klustrade indexkolumnerna och returnerar ett antal för varje grupp:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 GROUP BY LocationID, UserID, SessionID;
Frågeplanen skannar det icke-klustrade indexet och använder ett Hash Match Aggregate för att räkna rader i varje grupp:
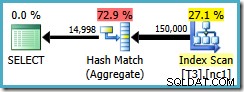
Det finns två problem med Hash Aggregate:
- Det är en blockerande operatör. Inga rader returneras till klienten förrän alla rader har aggregerats.
- Det kräver ett minnestillstånd för att hålla hashtabellen.
I många verkliga scenarier skulle vi föredra ett Stream Aggregate här eftersom den operatören bara blockerar per grupp och inte kräver ett minnesbidrag. Med det här alternativet skulle klientapplikationen börja ta emot data tidigare, inte behöva vänta på att minnet ska beviljas och SQL Server kan använda minnet för andra ändamål.
Vi kan kräva att frågeoptimeraren använder ett Stream Aggregate för den här frågan genom att lägga till ett OPTION (ORDER GROUP) frågetips. Detta resulterar i följande genomförandeplan:

Sorteringsoperatören blockerar helt och kräver också ett minnesanslag, så den här planen verkar vara värre än att bara använda ett hashaggregat. Men varför behövs den sorten? Egenskaperna visar att raderna sorteras i den ordning som anges av vår GROUP BY klausul:
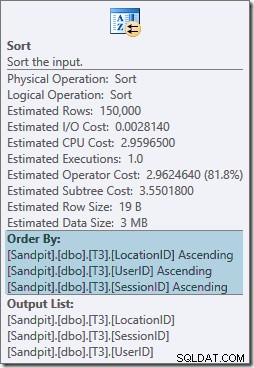
Denna sort är förväntad eftersom partitionsjustering av indexet (i SQL Server 2008 och framåt) innebär att partitionsnumret läggs till som en ledande kolumn i indexet. I själva verket beror de icke-klustrade indexnycklarna (partition, användare, session, plats) på partitioneringen. Rader i indexet är fortfarande sorterade efter användare, session och plats, men bara inom varje partition.
Om vi begränsar frågan till en enda partition, borde optimeraren kunna använda indexet för att mata ett Stream Aggregate utan sortering. Om det kräver en viss förklaring innebär att ange en enskild partition att frågeplanen kan eliminera alla andra partitioner från den icke-klustrade indexsökningen, vilket resulterar i en ström av rader som är sorterad efter (användare, session, plats).
Vi kan uppnå denna partitionseliminering explicit genom att använda $PARTITION funktion:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID;
Tyvärr använder den här frågan fortfarande ett Hash Aggregate, med en beräknad plankostnad på 0,287878 :
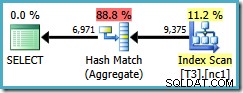
Skanningen är nu drygt en partition, men beställningen (användare, session, plats) har inte hjälpt optimeraren att använda ett Stream Aggregate. Du kan invända att beställning (användare, session, plats) inte är till hjälp eftersom GROUP BY satsen är (plats, användare, session), men nyckelordningen spelar ingen roll för en grupperingsoperation.
Låt oss lägga till en ORDER BY sats i indexnycklarnas ordning för att bevisa poängen:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID ORDER BY UserID, SessionID, LocationID;
Lägg märke till att ORDER BY satsen matchar den icke-klustrade indexnyckelordningen, även om GROUP BY klausul gör det inte. Utförandeplanen för denna fråga är:
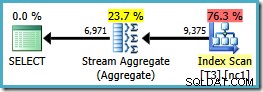
Nu har vi Stream Aggregate vi var ute efter, med en beräknad plankostnad på 0,0423925 (jämfört med 0,287878 för Hash Aggregate-planen – nästan 7 gånger mer).
Det andra sättet att uppnå ett Stream Aggregate här är att ordna om GROUP BY kolumner för att matcha de icke-klustrade indexnycklarna:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1 GROUP BY UserID, SessionID, LocationID;
Den här frågan producerar samma Stream Aggregate-plan som visas omedelbart ovan, med exakt samma kostnad. Denna känslighet för GROUP BY kolumnordningen är specifik för partitionerade tabellfrågor i SQL Server 2008 och senare.
Du kanske känner igen att grundorsaken till problemet här liknar det tidigare fallet med en sammanfogning. Både Merge Join och Stream Aggregate kräver indata sorterad på join- eller aggregeringsnycklarna, men ingen av dem bryr sig om ordningen på dessa nycklar. En sammanfogning på (x, y, z) är lika glada att ta emot rader sorterade efter (y, z, x) eller (z, y, x) och detsamma gäller för Stream Aggregate.
Denna optimeringsbegränsning gäller även för DISTINCT under samma omständigheter. Följande fråga resulterar i en Hash Aggregate-plan med en uppskattad kostnad på 0,286539 :
SELECT DISTINCT LocationID, UserID, SessionID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
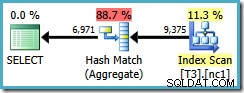
Om vi skriver DISTINCT kolumner i ordningen för de icke-klustrade indexnycklarna...
SELECT DISTINCT UserID, SessionID, LocationID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
…vi belönas med en Stream Aggregate-plan med en kostnad på 0,041455 :

Sammanfattningsvis är detta en begränsning av frågeoptimeraren i SQL Server 2008 och senare (inklusive SQL Server 2014 CTP 1) som inte löses med hjälp av spårningsflagga 4199 som var fallet med Merge Join-exemplet. Problemet uppstår endast med partitionerade tabeller med en GROUP BY eller DISTINCT över tre eller fler kolumner med hjälp av ett justerat partitionerat index, där en enda partition bearbetas.
Som med Merge Join-exemplet representerar detta ett steg bakåt från SQL Server 2005-beteendet. SQL Server 2005 lade inte till en underförstådd ledande nyckel till partitionerade index, med en APPLY teknik istället. I SQL Server 2005, alla frågor som presenteras här med $PARTITION att ange ett enstaka partitionsresultat i frågeplaner som utför partitionseliminering och använda Stream Aggregates utan någon omordning av frågetexten.
Ändringarna av partitionerad tabellbehandling i SQL Server 2008 förbättrade prestandan på flera viktiga områden, främst relaterade till effektiv parallell bearbetning av partitioner. Tyvärr hade dessa ändringar biverkningar som inte alla har lösts i senare utgåvor.