Den allmänna strategin som SQL Server-databasmotorn använder för att hålla en indexerad vy synkroniserad med dess bastabeller – som jag beskrev mer i detalj i mitt förra inlägg – är att utföra inkrementellt underhåll av vyn närhelst en dataändringsoperation inträffar mot en av tabellerna som refereras till i vyn. I stora drag är tanken att:
- Samla information om ändringarna i bastabellen
- Använd projektionerna, filtren och kopplingarna som definierats i vyn
- Aggregera ändringarna per klustrad nyckel för indexerad vy
- Bestämma om varje ändring ska resultera i en infogning, uppdatering eller borttagning mot vyn
- Beräkna värdena som ska ändras, läggas till eller tas bort i vyn
- Tillämpa vyändringarna
Eller ännu mer kortfattat (om än med risk för grov förenkling):
- Beräkna de inkrementella vyeffekterna av de ursprungliga dataändringarna;
- Tillämpa dessa ändringar på vyn
Detta är vanligtvis en mycket effektivare strategi än att bygga om hela vyn efter varje underliggande dataändring (det säkra men långsamma alternativet), men det förlitar sig på att den inkrementella uppdateringslogiken är korrekt för varje tänkbar dataändring, mot alla möjliga indexerade vyer.
Som rubriken antyder handlar den här artikeln om ett intressant fall där logiken för inkrementell uppdatering går sönder, vilket resulterar i en korrupt indexerad vy som inte längre matchar de underliggande data. Innan vi kommer till själva buggen måste vi snabbt granska skalära och vektoraggregat.
Skalära och vektoraggregat
Om du inte är bekant med termen finns det två typer av aggregat. Ett aggregat som är associerat med en GROUP BY-sats (även om listan grupp efter är tom) kallas vektoraggregat . Ett aggregat utan en GROUP BY-sats är känt som ett skalärt aggregat .
Medan ett vektoraggregat garanterat producerar en enda utdatarad för varje grupp som finns i datamängden, är skalära aggregat lite annorlunda. Skalära sammanställningar alltid producera en enda utgångsrad, även om ingångsuppsättningen är tom.
Vektoraggregatexempel
Följande AdventureWorks-exempel beräknar två vektoraggregat (en summa och ett antal) på en tom ingångsuppsättning:
-- There are no TransactionHistory records for ProductID 848 -- Vector aggregate produces no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID;
Dessa frågor ger följande utdata (inga rader):

Resultatet är detsamma, om vi ersätter GROUP BY-satsen med en tom uppsättning (kräver SQL Server 2008 eller senare):
-- Equivalent vector aggregate queries with -- an empty GROUP BY column list -- (SQL Server 2008 and later required) -- Still no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY (); SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY ();
Utförandeplanerna är identiska även i båda fallen. Detta är exekveringsplanen för räkningsfrågan:
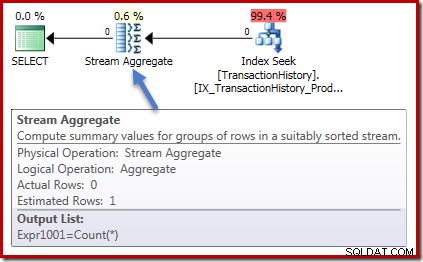
Noll rader inmatade till Stream Aggregate och noll rader ut. Summans genomförandeplan ser ut så här:

Återigen, noll rader in i aggregatet och noll rader ut. Alla bra enkla saker hittills.
Skalära aggregat
Titta nu vad som händer om vi tar bort GROUP BY-satsen från frågorna helt:
-- Scalar aggregate (no GROUP BY clause) -- Returns a single output row from an empty input SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848;
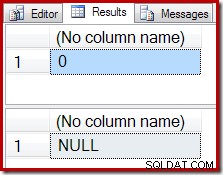
Istället för ett tomt resultat ger COUNT-aggregatet en nolla och SUMMA returnerar en NULL:
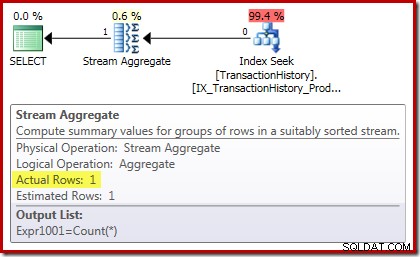
Räkneexekveringsplanen bekräftar att nollinmatningsrader producerar en enda rad med utdata från Stream Aggregate:
Summans genomförandeplan är ännu mer intressant:
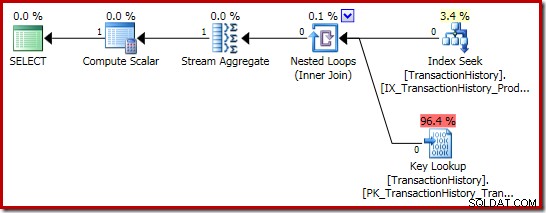
Egenskaperna för Stream Aggregate visar ett antal aggregat som beräknas utöver summan vi bad om:
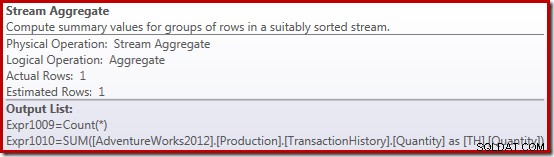
Den nya Compute Scalar-operatorn används för att returnera NULL om antalet rader som tas emot av Stream Aggregate är noll, annars returnerar den summan av data som påträffas:
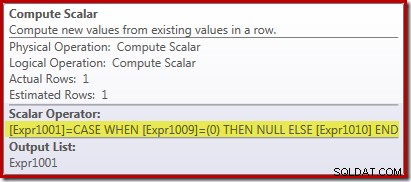
Det här kan verka lite konstigt, men så här fungerar det:
- Ett vektoraggregat med nollrader returnerar nollrader;
- Ett skalärt aggregat producerar alltid exakt en rad med utdata, även för en tom indata;
- Det skalära antalet nollrader är noll; och
- Den skalära summan av nollrader är NULL (inte noll).
Den viktiga poängen för våra nuvarande syften är att skalära aggregat alltid producerar en enda rad med utdata, även om det innebär att skapa en ur ingenting. Dessutom är den skalära summan av nollrader NULL, inte noll.
Dessa beteenden är alla "korrekta" förresten. Saker och ting är som de är eftersom SQL-standarden ursprungligen inte definierade beteendet för skalära aggregat, vilket lämnade det upp till implementeringen. SQL Server bevarar sin ursprungliga implementering av bakåtkompatibilitetsskäl. Vektoraggregat har alltid haft väldefinierade beteenden.
Indexerade vyer och vektoraggregation
Tänk nu på en enkel indexerad vy som innehåller ett par (vektor)aggregat:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
GroupSum = SUM(T1.Value),
RowsInGroup = COUNT_BIG(*)
FROM dbo.T1 AS T1
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Följande frågor visar innehållet i bastabellen, resultatet av att fråga den indexerade vyn och resultatet av att köra vyfrågan på tabellen som ligger bakom vyn:
-- Sample data SELECT * FROM dbo.T1 AS T1; -- Indexed view contents SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Underlying view query results SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
Resultaten är:
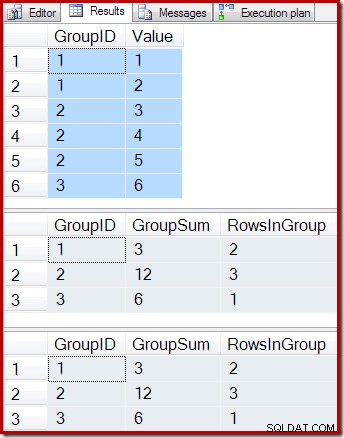
Som förväntat ger den indexerade vyn och den underliggande frågan exakt samma resultat. Resultaten kommer att fortsätta att förbli synkroniserade efter alla möjliga ändringar av bastabellen T1. För att påminna oss själva om hur allt detta fungerar, överväg det enkla fallet att lägga till en enda ny rad i bastabellen:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Exekveringsplanen för denna infogning innehåller all logik som behövs för att hålla den indexerade vyn synkroniserad:
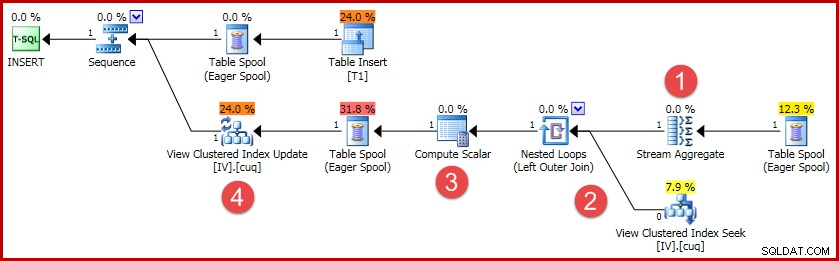
De viktigaste aktiviteterna i planen är:
- Strömaggregatet beräknar ändringarna per indexerad vynyckel
- Ytteranslutningen till vyn länkar ändringssammanfattningen till målvyraden, om någon
- Compute Scalar avgör om varje ändring kommer att kräva en infogning, uppdatering eller radering mot vyn och beräknar de nödvändiga värdena.
- Operatorn för vyuppdatering utför fysiskt varje ändring av vyklustrade index.
Det finns vissa planskillnader för olika ändringsoperationer mot bastabellen (t.ex. uppdateringar och raderingar), men den breda idén bakom att hålla vyn synkroniserad förblir densamma:aggregera ändringarna per vynyckel, hitta vyraden om den finns och utför sedan en kombination av infoga, uppdatera och ta bort operationer på vyindexet efter behov.
Oavsett vilka ändringar du gör i bastabellen i det här exemplet kommer den indexerade vyn att förbli korrekt synkroniserad – NOEXPAND- och EXPAND VIEWS-frågorna ovan kommer alltid att returnera samma resultatuppsättning. Det är så saker alltid ska fungera.
Indexerade vyer och skalär aggregation
Prova nu detta exempel, där den indexerade vyn använder skalär aggregering (ingen GROUP BY-sats i vyn):
DROP VIEW dbo.IV;
DROP TABLE dbo.T1;
GO
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Detta är en helt laglig indexerad uppfattning; inga fel uppstår när den skapas. Det finns en ledtråd till att vi kan göra något lite konstigt, dock:när det är dags att materialisera vyn genom att skapa det nödvändiga unika klustrade indexet, finns det inte en självklar kolumn att välja som nyckel. Normalt skulle vi naturligtvis välja grupperingskolumnerna från vyns GROUP BY-sats.
Skriptet ovan väljer godtyckligt kolumnen NumRows. Det valet är inte viktigt. Skapa gärna det unika klustrade indexet hur du än väljer. Vyn kommer alltid att innehålla exakt en rad på grund av de skalära aggregaten, så det finns ingen chans till en unik nyckelöverträdelse. I den meningen är valet av indexnyckel för vy överflödig, men krävs ändå.
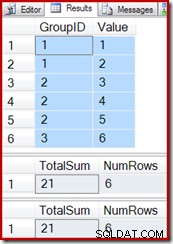
Genom att återanvända testfrågorna från föregående exempel kan vi se att den indexerade vyn fungerar korrekt:
SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
Att infoga en ny rad i bastabellen (som vi gjorde med vektoraggregatets indexerade vyn) fortsätter att fungera korrekt också:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Utförandeplanen är liknande, men inte helt identisk:
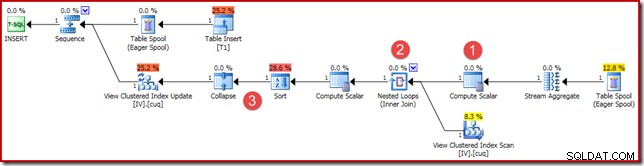
De huvudsakliga skillnaderna är:
- Denna nya Compute Scalar finns där av samma skäl som när vi jämförde vektor- och skalära aggregeringsresultat tidigare:den säkerställer att en NULL-summa returneras (istället för noll) om aggregatet fungerar på en tom uppsättning. Detta är det nödvändiga beteendet för en skalär summa av inga rader.
- Den yttre kopplingen som vi sett tidigare har ersatts av en inre koppling. Det kommer alltid att finnas exakt en rad i den indexerade vyn (på grund av den skalära aggregeringen) så det är ingen fråga om att behöva en yttre koppling för att testa om en vyrad matchar eller inte. Den ena raden i vyn representerar alltid hela datauppsättningen. Denna Inner Join har inget predikat, så det är tekniskt sett en cross join (till en tabell med en garanterad enkel rad).
- Sorterings- och komprimeringsoperatorerna är närvarande av tekniska skäl som behandlas i min tidigare artikel om underhåll av indexerad vy. De påverkar inte den korrekta driften av underhållet av den indexerade vyn här.
Faktum är att många olika typer av dataändringsoperationer kan utföras framgångsrikt mot bastabellen TI i detta exempel; effekterna kommer att återspeglas korrekt i den indexerade vyn. Följande ändringsoperationer mot bastabellen kan alla utföras samtidigt som den indexerade vyn hålls korrekt:
- Ta bort befintliga rader
- Uppdatera befintliga rader
- Infoga nya rader
Det här kan tyckas vara en heltäckande lista, men det är den inte.
Bugen avslöjad
Frågan är ganska subtil och relaterar (som du borde förvänta dig) till de olika beteendena hos vektor- och skalära aggregat. Nyckelpunkterna är att ett skalärt aggregat alltid kommer att producera en utdatarad, även om det inte får några rader på sin ingång, och den skalära summan av en tom uppsättning är NULL, inte noll.
För att orsaka problem behöver vi bara infoga eller ta bort inga rader i bastabellen.
Det uttalandet är inte så tokigt som det kanske låter vid första tillfället.
Poängen är att en infoga eller ta bort fråga som inte påverkar några bastabellrader fortfarande uppdaterar vyn, eftersom det skalära Stream Aggregate i den indexerade vyns underhållsdel av frågeplanen kommer att producera en utdatarad även när den presenteras utan indata. Compute Scalar som följer Stream Aggregate kommer också att generera en NULL summa när antalet rader är noll.
Följande skript visar hur buggen fungerar:
-- So we can undo BEGIN TRANSACTION; -- Show the starting state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- A table variable intended to hold new base table rows DECLARE @NewRows AS table (GroupID integer NOT NULL, Value integer NOT NULL); -- Insert to the base table (no rows in the table variable!) INSERT dbo.T1 SELECT NR.GroupID,NR.Value FROM @NewRows AS NR; -- Show the final state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Undo the damage ROLLBACK TRANSACTION;
Utdata från det skriptet visas nedan:
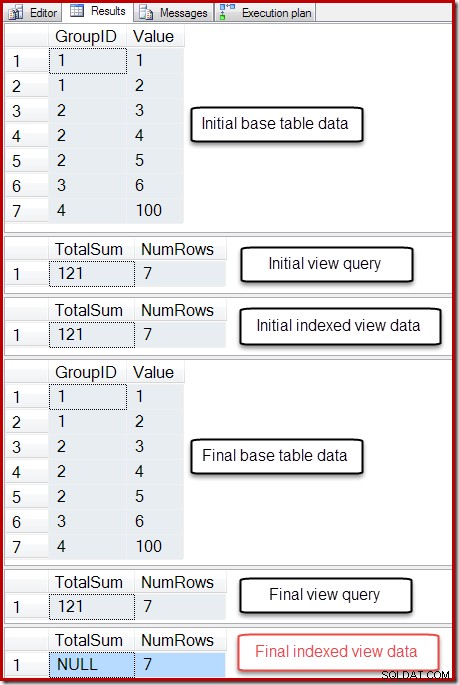
Det slutliga tillståndet för den indexerade vyns kolumn Totalsumma matchar inte den underliggande vyfrågan eller bastabelldata. NULL-summan har skadat vyn, vilket kan bekräftas genom att köra DBCC CHECKTABLE (på den indexerade vyn).
Avrättningsplanen som är ansvarig för korruptionen visas nedan:
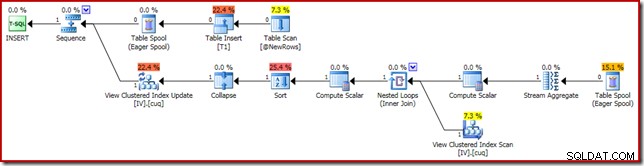
När du zoomar in visas nollradernas indata till Stream Aggregate och enradsutgången:
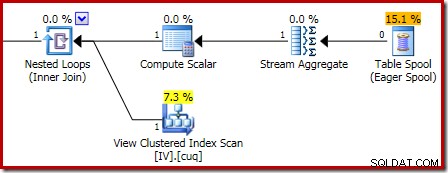
Om du vill prova korruptionsskriptet ovan med en radering istället för en infogning, här är ett exempel:
-- No rows match this predicate DELETE dbo.T1 WHERE Value BETWEEN 10 AND 50;
Borttagningen påverkar inga bastabellrader, men ändrar fortfarande den indexerade vyns summakolumn till NULL.
Generalisera felet
Du kan förmodligen komma på hur många infogning som helst och radera bastabellfrågor som inte påverkar några rader och orsaka korruption av denna indexerade vy. Men samma grundläggande problem gäller för en bredare klass av problem än bara infogar och borttagningar som inte påverkar några bastabellrader.
Det är till exempel möjligt att producera samma korruption med hjälp av en infogning som gör lägg till rader i bastabellen. Den väsentliga ingrediensen är att inga tillagda rader ska kvalificera sig för vyn . Detta kommer att resultera i en tom ingång till Stream Aggregate och den korruptionsorsakande NULL-radutgången från följande Compute Scalar.
Ett sätt att uppnå detta är att inkludera en WHERE-sats i vyn som avvisar några av bastabellraderna:
ALTER VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
-- New!
T1.GroupID BETWEEN 1 AND 3;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Med tanke på den nya begränsningen av grupp-ID:n som ingår i vyn, kommer följande infogning att lägga till rader till bastabellen, men den indexerade vyn är fortfarande korrumperad till en NULL summa:
-- So we can undo
BEGIN TRANSACTION;
-- Show the starting state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- The added row does not qualify for the view
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100);
-- Show the final state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- Undo the damage
ROLLBACK TRANSACTION; Utdatat visar den nu bekanta indexkorruptionen:
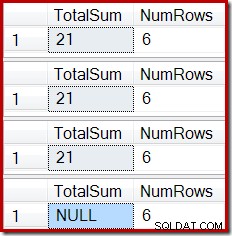
En liknande effekt kan skapas med en vy som innehåller en eller flera inre skarvar. Så länge rader som läggs till i bastabellen avvisas (till exempel genom att inte gå med), kommer Stream Aggregate inte att ta emot några rader, Compute Scalar kommer att generera en NULL summa och den indexerade vyn kommer sannolikt att bli skadad.
Sluta tankar
Det här problemet råkar inte uppstå för uppdateringsfrågor (åtminstone så vitt jag kan se) men det verkar vara mer av misstag än design – det problematiska Stream Aggregate finns fortfarande i potentiellt sårbara uppdateringsplaner, men Compute Scalar som genererar NULL summan läggs inte till (eller kanske optimeras bort). Meddela mig om du lyckas reproducera buggen med en uppdateringsfråga.
Tills denna bugg har rättats (eller, kanske, skalära aggregat blir otillåtna i indexerade vyer) var mycket försiktig med att använda aggregat i en indexerad vy utan en GROUP BY-sats.
Den här artikeln föranleddes av ett Connect-objekt som skickats in av Vladimir Moldovanenko, som var vänlig nog att lämna en kommentar på ett gammalt blogginlägg av mig (som handlar om korruption av en annan indexerad vy orsakad av MERGE-uttalandet). Vladimir använde skalära aggregat i en indexerad vy av sunda skäl, så var inte för snabb att bedöma denna bugg som ett kantfall som du aldrig kommer att stöta på i en produktionsmiljö! Tack till Vladimir för att han gjorde mig uppmärksam på hans Connect-objekt.