Vill du lära dig att designa ett databassystem och kartlägga en affärsprocess till en datamodell? Då är detta inlägg för dig.
I den här artikeln kommer du att se hur du designar ett enkelt databasschema för ett rekryteringsföretag. Efter att ha läst den här handledningen kommer du att kunna förstå hur databasscheman är designade för verkliga applikationer.
Rekryteringssystemets affärsprocess
Innan du designar någon databas eller datamodell är det absolut nödvändigt att förstå den grundläggande affärsprocessen för det systemet. Databasschemat vi kommer att skapa är för ett tänkt rekryteringsföretag eller -team. Låt oss först se stegen för att anställa nya medarbetare:
- Företag kontaktar rekryteringsbyråer för att anställa för deras räkning. I vissa fall rekryterar företag anställda direkt.
- Den person som ansvarar för rekryteringen startar rekryteringsprocessen. Denna process kan ha flera steg, såsom den första screeningen, ett skriftligt prov, den första intervjun, uppföljningsintervjun, själva anställningsbeslutet, etc.
- När rekryterarna har kommit överens om en viss process – och detta kan ändras beroende på klienten, företaget eller jobbet i fråga – annonseras den lediga tjänsten på olika plattformar.
- Sökande börjar söka jobbet.
- De sökande nomineras och bjuds in till ett test eller inledande intervju.
- De sökande kommer till provet/intervjun.
- Testerna betygsätts av rekryterarna. I vissa fall skickas tester vidare till specialister för betygsättning.
- De sökandes intervjuer poängsätts av en eller flera rekryterare.
- Sökande utvärderas på basis av tester och intervjuer.
- Anställningsbeslutet fattas.
Ett databasschema för rekryteringssystem
Med tanke på ovannämnda process är vårt databasschema uppdelat i fem ämnesområden:
ProcessJobsApplication, Applicant, and DocumentsTest and InterviewsRecruiters and Application Evaluation
Vi kommer att granska vart och ett av dessa områden i detalj, i den ordning de är listade. Nedan kan du se hela datamodellen.
Process
Processkategorin innehåller information relaterad till rekryteringsprocesserna. Den innehåller tre tabeller:process , step och process_step . Vi kommer att titta på var och en.
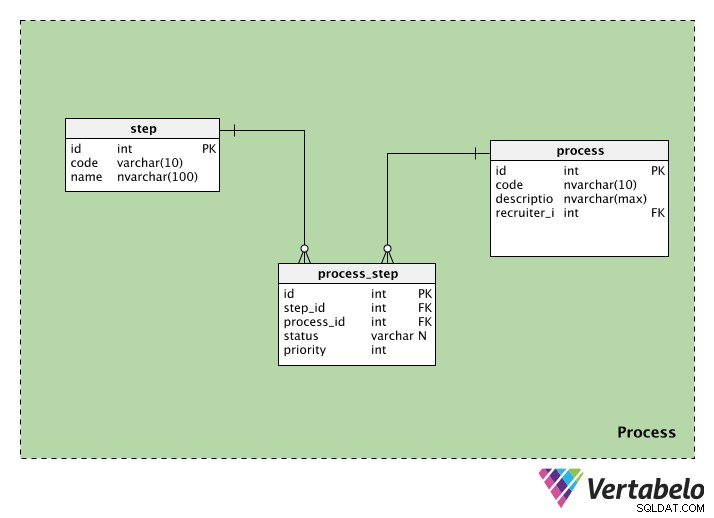
process Tabellen lagrar information om varje rekryteringsprocess. Varje process kommer att ha ett speciellt ID, en kod och en description av den processen. Vi kommer också att ha recruiter_id av den person som initierar processen.
step Tabellen innehåller information om de steg som följts under hela rekryteringsprocessen. Varje steg har ett id och en code namn. Namnkolumnen kan ha värden som "initial screening", "skriftligt test", "HR-intervju" etc.
Eftersom en process kan ha flera steg och ett steg kan vara en del av många processer behöver vi en uppslagstabell. process_step Tabellen innehåller information om varje steg (i step_id ) och processen den tillhör (i process_id ). Vi har också en status som talar om för oss statusen för det steget i den processen; detta kan vara NULL om steget inte har påbörjats ännu. Slutligen har vi en priority , som talar om för oss i vilken ordning stegen ska utföras. Stegen med högst priority värdet kommer att köras först.
Jobb
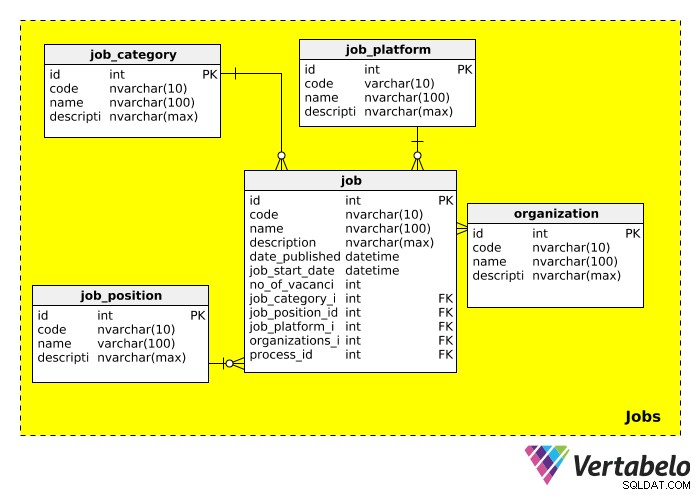
Därefter har vi Jobs ämnesområde, som lagrar all information relaterad till jobbet/jobben vi rekryterar till. Schemat för denna kategori ser ut så här:
Låt oss förklara var och en av tabellerna i detalj.
job_category Tabellen beskriver i stora drag typen av jobb. Vi kan förvänta oss att se jobbkategorier som "IT", "ledning", "ekonomi", "utbildning" etc.
job_position tabellen innehåller den faktiska befattningen. Eftersom en titel kan annonseras för flera jobb (t.ex. "IT-chef", "försäljningschef"), har vi skapat en separat tabell för jobbpositioner. Vi kan förvänta oss att se värden som "IT Team Lead", "Vice President" och "Manager" i den här tabellen.
job_platform Tabellen hänvisar till det medium som används för att annonsera jobbet. Ett jobb kan till exempel läggas ut på Facebook, en jobbbräda online eller i en lokaltidning. En länk till det jobbannonsen kan läggas till i description fält.
organization tabellen lagrar information om alla företag som någonsin har använt denna databas som en del av sin anställningsprocess. Uppenbarligen är denna tabell viktig när rekrytering görs för ett annat företag.
Den sista tabellen i detta ämnesområde, job , innehåller den faktiska arbetsbeskrivningen. De flesta av attributen är självförklarande. Vi bör notera att den här tabellen har många främmande nycklar, vilket betyder att den kan användas för att slå upp kategorin, positionen, plattformen, anställningsorganisationen och rekryteringsprocessen relaterad till det jobböppningen.
Ansökan, sökande och dokument
Den tredje delen av schemat består av tabellerna som lagrar information om arbetssökande, deras ansökningar och eventuella dokument som följer med ansökningarna.
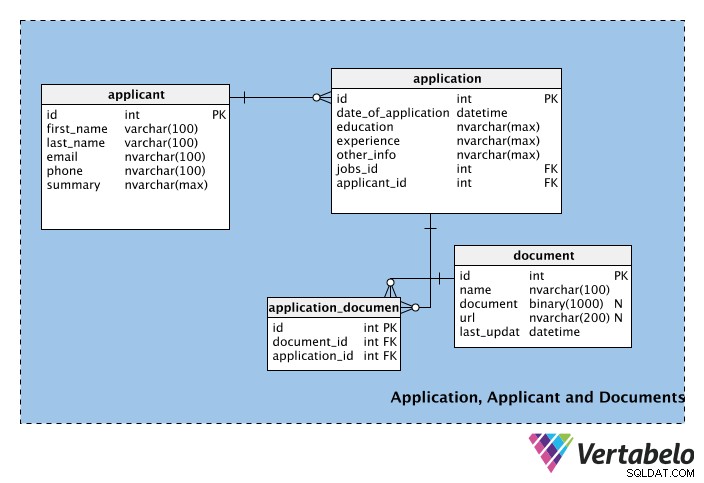
Den första tabellen, applicant , lagrar sökandes personliga information, såsom deras förnamn, efternamn, e-post, telefonnummer, etc. Sammanfattningsfältet kan användas för att lagra kort profil för sökanden (dvs. ett stycke).
Nästa tabell innehåller information för varje application inklusive dess datum. Tabellen innehåller också experience och education kolumner. Dessa kolumner kan vara en del av applicant tabell, men en sökande kanske vill eller kanske inte vill visa en viss utbildningskvalifikation eller arbetserfarenhet i varje ansökan de skickar in. Därför är dessa kolumner en del av application tabell. other_info kolumnen lagrar all annan programrelaterad information. I application tabellen, jobb-id och sökande_id är främmande nycklar från jobb- respektive sökandetabellerna.
Eftersom det kan finnas flera ansökningar för varje jobb men varje ansökan bara gäller ett jobb, kommer det att finnas en en-till-många-relation mellan jobs och applications tabeller. På samma sätt kan en sökande skicka in flera ansökningar (dvs. för olika jobb), men varje ansökan kommer från endast en deltagare; vi har implementerat ytterligare en en-till-många-relation mellan applicants och applications tabeller för att hantera detta.
document tabell hanterar de styrkande handlingar som sökande kan bifoga sin ansökan. Dessa kan vara CV:n, meritförteckningar, referensbrev, följebrev, etc. Observera att denna tabell har en binär kolumn med namnet dokument, som lagrar filen i binärt format. En länk till dokumentet kan lagras i url fält; namnkolumnen lagrar namnet på dokumentet och last_update betecknar den senaste versionen som laddats upp av den sökande. Observera att både document och url är nullbara; ingendera är obligatorisk, och en sökande kan välja att använda endera eller båda metoderna för att lägga till information till sin ansökan.
Inte varje ansökan kommer att ha ett dokument bifogat. Ett dokument kan bifogas flera ansökningar och en ansökan kan ha flera stödjande dokument. Det betyder att det finns ett många-till-många-förhållande mellan application och document tabeller. För att hantera denna relation, söktabellen application_document har skapats.
Tester och intervjuer
Nu går vi vidare till tabellerna som lagrar information om testerna och intervjuerna relaterade till rekryteringsprocessen.
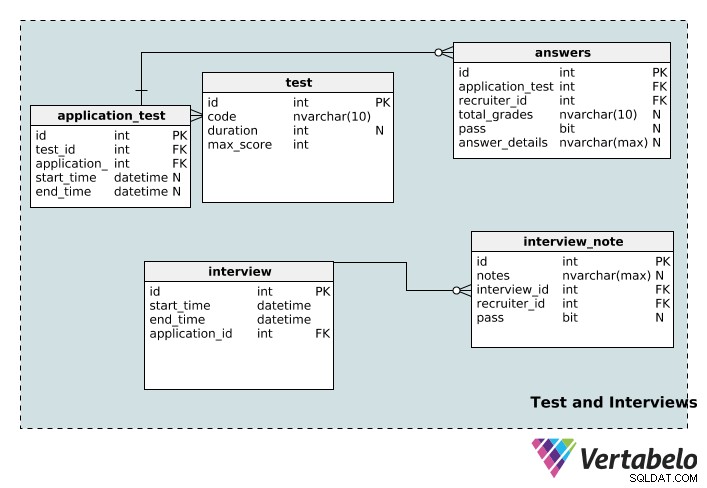
test Tabell lagrar testdetaljer inklusive dess unika id , code namn, dess duration i minuter och maximum möjliga poäng för det testet.
En applikation kan associeras med flera tester och ett test kan associeras med flera applikationer. Återigen har vi en uppslagstabell för att implementera denna relation:application_test . start_time och end_time kolumner är nullbara eftersom ett test kanske inte har någon specifik varaktighet, starttid eller sluttid.
Ett test kan betygsättas av flera rekryterare och en rekryterare kan betygsätta flera test. answers table är bordet som gör detta möjligt. total_grades kolumnen registrerar hur bra kandidaten klarade sig på provet, och kolumnen för godkänt anger helt enkelt om den personen godkänts eller underkändes. Detaljerna för varje enskilt test registreras i answer_details kolumn. Observera att dessa tre kolumner är nullbara; ett ansökningstest kan tilldelas en rekryterare som ännu inte har betygsatt det. Dessutom kan en rekryterare tilldelas ett test innan det faktiskt tas.
interview Tabell lagrar grundläggande information (start_time , end_time , ett unikt id och relevant application_id ) för varje intervju. En intervju kan kopplas till endast en ansökan. Å andra sidan kan en ansökan ha flera intervjuer. Därför finns ett en-till-många-förhållande mellan ansöknings- och intervjutabellen.
En intervju kan genomföras av flera granskare och en granskare kan ta flera intervjuer. Det är en annan många-till-många-relation, så vi har skapat uppslagstabellen interview_note . Den lagrar information om intervjun (i interview_id ), rekryteraren (i recruiter_id ), och rekryterarens anteckningar om intervjun. Rekryterare kan också registrera huruvida den sökande klarat intervjun eller inte i kolumnen för godkänt, som är null.
Ansökningsutvärdering och status för rekryterare
Den sista delen av vår rekryteringsmodell lagrar information om rekryterare, ansökningsstatus och ansökningsutvärderingar.
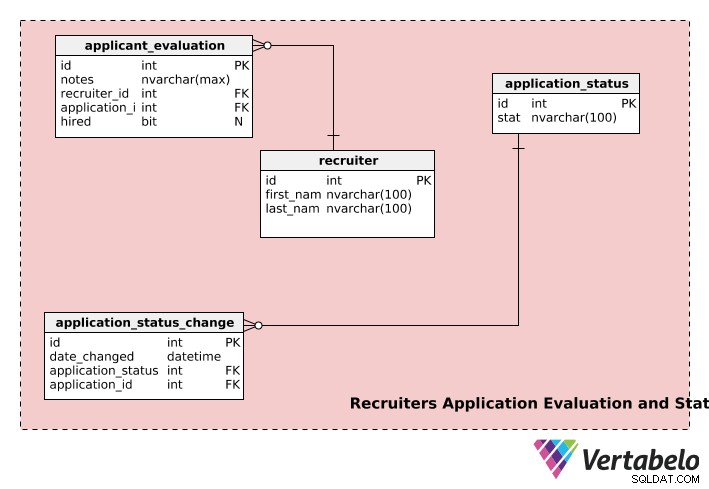
recruiters tabellen lagrar varje rekryterares first_name , last_name och unikt id siffra.
application_evaluation Tabellen innehåller information om ansökningsutvärderingar. Förutom application_id och recruiter_id , den innehåller rekryterarens feedback (i notes ) och det slutliga anställningsbeslutet, om något, i hired . En ansökan kan utvärderas av flera rekryterare och en rekryterare kan utvärdera flera ansökningar, så både recruiter och application tabellen har en en-till-många-relation med application_evaluation tabell.
En ansökan kan gå igenom flera steg under anställningsprocessen, t.ex. ”ej inskickad”, ”under granskning”, ”väntar på beslut”, ”beslut fattat” etc. En ansökan kommer att ha statusen ”ej_inlämnad” när användaren har startat en ansökan men inte lämnat in den för att rekryterarna ska kunna granska den. När ansökan är inlämnad ändras statusen till "under granskning" och så vidare. application_status tabell används för att lagra sådan information.
application_status_change Tabellen används för att upprätthålla statusändringar för alla inskickade ansökningar. date_changed kolumnen lagrar datumet för statusändringen. Denna tabell kan vara praktisk om du vill analysera handläggningstiden för varje steg av olika applikationer. Dessutom kan statusen för en viss kolumn hämtas med application_id kolumnen från application_status_change tabell.
Ett enkelt användningsfall för rekrytering
Låt oss se hur vår databas kan hjälpa rekryteringsprocessen.
Anta att ett företag har gett dig i uppdrag att anställa en IT-chef med erfarenhet av programmering. Vår databas kan hjälpa oss att anställa en sådan person genom att utföra följande steg:
- Det första steget är att starta en ny anställningsprocess. För att göra det läggs data in i
processochsteptabeller. En rekryterare kan lägga till så många steg som de behöver. - Under ovanstående uppgift kan rekryteraren skapa ett nytt jobb och ange detaljerna i
job,job_category,job_positionochorganizationtabeller. Slutligen kommer en platsannons att placeras på en av plattformarna som finns lagrade ijob_platformtabell. - Närnäst kommer sökande att skapa en profil genom att skicka in sina uppgifter till
applicanttabell. Sedan kommer de att starta en ny applikation genom att ange mer data iapplicationtabell. - Sökande kan också bifoga dokument till sina ansökningar. Dessa data kommer att lagras i
documentochapplication_documenttabeller. - Om en användare vill ansöka om mer än ett jobb kommer de att upprepa steg 3 och 4.
- När ansökan har skickats in kommer statusen för ansökan att ställas in på "skickad" (eller annat statusnamn som rekryteraren valt).
- Rekryteraren kommer att utvärdera ansökan och ange sin feedback i
application_evaluationtabell. I det här skedet kommer den hyrda kolumnen inte att innehålla någon information. - När ett tillräckligt antal ansökningar har tagits emot kommer rekryteraren att utföra nästa steg som visas i
process_steptabell. - Om nästa steg är att administrera någon form av test, kommer rekryteraren att skapa ett test genom att lägga till data i
testtabell. - Testen som skapades i steg 9 kommer att tilldelas en viss applikation. Informationen som tilldelar varje test till varje applikation kommer att lagras i
application_testtabell. Observera att applikationens status kommer att ändras under varje steg. Detta kommer att registreras iapplication_status_changetabell. - När den sökande har slutfört testet kommer betygen för varje ansökningstest att markeras av rekryteraren och skrivas in i
answertabell. - När testet har tagits, nästa steg från
process_steptabell kommer att köras. Låt oss säga att nästa steg är intervjun. - Intervjudata kommer att matas in i
interviewtabell. Rekryteraren kommer att skriva in sina kommentarer och säga om personen klarade intervjun eller inte. Detta kommer att lagras iinterview_notetabell. - Om
processTabellen innehåller ytterligare intervju- och teststeg, de kommer att utföras tills det sista steget nås. - Det sista steget i
process_steptabell är normalt anställningsbeslutet. Om den sökande klarar sina tester och intervjuer och företaget bestämmer sig för att anställa dem, skrivs uppgifter in i hyrkolumnen iapplication_evaluationbord och personen anställs.
Vad tycker du om vår datamodell för rekryteringssystem?
I den här artikeln såg vi hur man skapar ett mycket enkelt databasschema för ett rekryteringssystem. Vi delade in schemat i fyra kategorier och förklarade sedan var och en av dem i detalj. Slutligen körde vi ett användningsfall för att visa att vårt schema faktiskt kan hjälpa till att rekrytera en anställd.
Databasdesignjobben blomstrar. Vill du utöka din databaskunskaper? Oavsett om du är en nykomling som vill lära dig grunderna i SQL eller en erfaren yrkesman som vill förgrena sig till Skapa tabeller i SQL | Interaktiv kurs | Vertabelo Academy" target="_blank">databasdesign, kolla in LearnSQL.coms kurser i egen takt.