Många människor använder väntestatistik som en del av deras övergripande felsökningsmetod för prestanda, liksom jag, så frågan jag ville utforska i det här inlägget handlar om väntetyper förknippade med observatörskostnader. Med observatörskostnader menar jag påverkan på SQL Server-arbetsbelastning som orsakas av SQL Profiler, spårningar på serversidan eller utökade händelsesessioner. För mer om ämnet observer overhead, se följande två inlägg från min kollega Jonathan Kehayias :
- Mätning av "Observer Overhead" av SQL Trace vs. Extended Events
- Effekten av query_post_execution_showplan Extended Event i SQL Server 2012
Så i det här inlägget skulle jag vilja gå igenom några varianter av observatörsoverhead och se om vi kan hitta konsekventa väntetyper förknippade med den uppmätta nedbrytningen. Det finns en mängd olika sätt som SQL Server-användare implementerar spårning i sina produktionsmiljöer, så dina resultat kan variera, men jag ville täcka några breda kategorier och rapportera tillbaka om vad jag hittade:
- Användning av SQL Profiler-session
- Spåranvändning på serversidan
- Spåra användning på serversidan, skriva till en långsam I/O-väg
- Utökad händelseanvändning med ett ringbuffertmål
- Utökad användning av händelser med ett filmål
- Utökad händelseanvändning med ett filmål på en långsam I/O-sökväg
- Utökad händelseanvändning med ett filmål på en långsam I/O-sökväg utan händelseförlust
Du kan antagligen komma på andra varianter av temat och jag inbjuder dig att dela med dig av alla intressanta rön om observatörsoverhead och väntestatistik som en kommentar i det här inlägget.
Baslinje
För testet använde jag en virtuell VMware-maskin med fyra vCPU:er och 4 GB RAM. Min virtuella maskingäst var på OCZ Vertex SSD:er. Operativsystemet var Windows Server 2008 R2 Enterprise och versionen av SQL Server är 2012, SP1 CU4.
När det gäller "arbetsbelastningen" använder jag en skrivskyddad fråga i en loop mot 2008 års kreditprovsdatabas, inställd på GO 10 000 000 gånger.
USE [Credit];
GO
SELECT TOP 1
[member].[member_no],
[member].[lastname],
[payment].[payment_no],
[payment].[payment_dt],
[payment].[payment_amt]
FROM [dbo].[payment]
INNER JOIN [dbo].[member]
ON [member].[member_no] = [payment].[member_no];
GO 10000000 Jag kör också den här frågan via 16 samtidiga sessioner. Slutresultatet på mitt testsystem är 100 % CPU-användning över alla vCPU:er på den virtuella gästen och i genomsnitt 14 492 batchförfrågningar per sekund under en period på två minuter.
När det gäller händelsespårningen använde jag i varje test Showplan XML Statistics Profile för spårningstesterna SQL Profiler och Server-side – och query_post_execution_showplan för utökade evenemangssessioner. Exekutivplanshändelser är mycket dyra, det är just därför jag valde dem så att jag kunde se om jag under extrema omständigheter kunde härleda teman av väntetyp eller inte.
För att testa ackumulering av väntetyp under en testperiod använde jag följande fråga. Inget märkvärdigt – bara att rensa statistiken, vänta 2 minuter och sedan samla de 10 bästa vänteackumuleringarna för SQL Server-instansen under nedbrytningstestperioden:
-- Clearing the wait stats
DBCC SQLPERF('waitstats', clear);
WAITFOR DELAY '00:02:00';
GO
SELECT TOP 10
[wait_type],
[waiting_tasks_count],
[wait_time_ms]
FROM sys.[dm_os_wait_stats] AS [ws]
ORDER BY [wait_time_ms] DESC; Observera att jag inte är det filtrera bort bakgrundsväntetyper som vanligtvis filtreras bort, och det beror på att jag inte ville eliminera något som normalt är godartat – men i den här omständigheten faktiskt pekar på ett verkligt område att undersöka vidare.
SQL Profiler Session
Följande tabell visar före- och efter-batchförfrågningar per sekund när du aktiverar en lokal SQL Profiler-spårningsspårning Showplan XML Statistics Profile (kör på samma virtuella dator som SQL Server-instansen):
| Baslinjebatchbegäranden per sekund (2 minuter i genomsnitt) | SQL Profiler Session Batch Requests per Second (2 minuter i genomsnitt) |
|---|---|
| 14 492 | 1 416 |
Du kan se att spårningen av SQL Profiler orsakar en betydande minskning av genomströmningen.
När det gäller ackumulerad väntetid under samma period var de bästa väntetyperna följande (som med resten av testerna i den här artikeln gjorde jag några testkörningar och resultatet var generellt konsekvent):
| wait_type | waiting_tasks_count | väntetid_ms |
|---|---|---|
| TRACEWRITE | 67 142 | 1 149 824 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 003 |
| SLEEP_TASK | 313 | 180 449 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 111 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120 086 |
| LAZYWRITER_SLEEP | 120 | 120 059 |
| DIRTY_PAGE_POLL | 1 198 | 120 038 |
| HADR_WORK_QUEUE | 12 | 120 015 |
| LOGMGR_QUEUE | 937 | 120 011 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 006 |
Väntetypen som hoppar ut för mig är TRACEWRITE – som definieras av Books Online som en väntetyp som "uppstår när spårningsleverantören för SQL Trace-raduppsättning väntar på antingen en ledig buffert eller en buffert med händelser att bearbeta". Resten av väntetyperna ser ut som vanliga väntetyper i bakgrunden som man vanligtvis skulle filtrera bort från din resultatuppsättning. Dessutom pratade jag om ett liknande problem med överspårning i en artikel 2011 som heter Observer overhead – farorna med för mycket spårning – så jag kände till den här väntetypen ibland korrekt pekar på observatörs overhead-problem. Nu i just det fallet jag bloggade om var det inte SQL Profiler, utan en annan applikation som använder rowset-spårningsleverantören (ineffektivt).
Spårning på serversidan
Det var för SQL Profiler, men hur är det med spårning på serversidan? Följande tabell visar före- och efter-batchbegäranden per sekund när du aktiverar en lokal server-side-spårskrivning till en fil:
| Baslinjebatchbegäranden per sekund (2 minuter i genomsnitt) | SQL Profiler Batch Requests per Second (2 minuter i genomsnitt) |
|---|---|
| 14 492 | 4 015 |
De bästa väntetyperna var följande (jag gjorde några testkörningar och resultatet var konsekvent):
| wait_type | waiting_tasks_count | väntetid_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 015 |
| SLEEP_TASK | 253 | 180 871 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 046 |
| HADR_WORK_QUEUE | 12 | 120 042 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 021 |
| XE_DISPATCHER_WAIT | 3 | 120 006 |
| VÄNTA | 1 | 120 000 |
| LOGMGR_QUEUE | 931 | 119 993 |
| DIRTY_PAGE_POLL | 1 193 | 119 958 |
| XE_TIMER_EVENT | 55 | 119 954 |
Den här gången ser vi inte TRACEWRITE (vi använder en filleverantör nu) och den andra spårningsrelaterade väntetypen, den odokumenterade SQLTRACE_INCREMENTAL_FLUSH_SLEEP klättrade upp – men har i jämförelse med det första testet mycket liknande ackumulerad väntetid (120 046 vs. 120 006) – och min kollega Erin Stellato (@erinstellato) pratade om just denna väntetyp i sitt inlägg. . Så om man tittar på de andra väntetyperna är det ingen som hoppar ut som en pålitlig röd flagga.
Server-Side Spåra skrivning till en långsam I/O-väg
Vad händer om vi lägger spårningsfilen på serversidan på långsam disk? Följande tabell visar före- och efter-batchbegäranden per sekund när du aktiverar en lokal spårning på serversidan som skriver till en fil på ett USB-minne:
| Baslinjebatchbegäranden per sekund (2 minuter i genomsnitt) | SQL Profiler Batch Requests per Second (2 minuter i genomsnitt) |
|---|---|
| 14 492 | 260 |
Som vi kan se – är prestandan avsevärt försämrad – även jämfört med föregående test.
De bästa väntetyperna var följande:
| wait_type | waiting_tasks_count | väntetid_ms |
|---|---|---|
| SQLTRACE_FILE_BUFFER | 357 | 351 174 |
| SP_SERVER_DIAGNOSTICS_SLEEP | 2 273 | 299 995 |
| SLEEP_TASK | 240 | 194 264 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 2 | 181 458 |
| REQUEST_FOR_DEADLOCK_SEARCH | 25 | 125 007 |
| LAZYWRITER_SLEEP | 63 | 124 437 |
| LOGMGR_QUEUE | 941 | 120 559 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 67 | 120 516 |
| VÄNTA | 1 | 120 515 |
| DIRTY_PAGE_POLL | 1 204 | 120 513 |
En väntetyp som hoppar ut för detta test är den odokumenterade SQLTRACE_FILE_BUFFER . Inte mycket dokumenterat om den här, men baserat på namnet kan vi göra en välgrundad gissning (särskilt med tanke på det här testets konfiguration).
Utökade händelser till ringbuffertmålet
Låt oss sedan gå igenom resultaten för motsvarande sessioner för utökad evenemang. Jag använde följande sessionsdefinition:
CREATE EVENT SESSION [ApplicationXYZ] ON SERVER ADD EVENT sqlserver.query_post_execution_showplan, ADD TARGET package0.ring_buffer(SET max_events_limit=(1000)) WITH (STARTUP_STATE=ON); GO
Följande tabell visar batchförfrågningar före och efter per sekund när en XE-session aktiveras med ett ringbuffertmål (fångar query_post_execution_showplan händelse):
| Baslinjebatchbegäranden per sekund (2 minuter i genomsnitt) | SQL Profiler Batch Requests per Second (2 minuter i genomsnitt) |
|---|---|
| 14 492 | 4 737 |
De bästa väntetyperna var följande:
| wait_type | waiting_tasks_count | väntetid_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 612 | 299 992 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 006 |
| SLEEP_TASK | 240 | 181 739 |
| LAZYWRITER_SLEEP | 120 | 120 219 |
| HADR_WORK_QUEUE | 12 | 120 038 |
| DIRTY_PAGE_POLL | 1 198 | 120 035 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 017 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 011 |
| LOGMGR_QUEUE | 936 | 120 008 |
| VÄNTA | 1 | 120 001 |
Ingenting hoppade ut som XE-relaterat, bara bakgrundsuppgift "brus".
Utökade händelser till ett filmål
Vad sägs om att ändra sessionen till att använda ett filmål istället för ett ringbuffertmål? Följande tabell visar före- och efter-batchbegäranden per sekund när du aktiverar en XE-session med ett filmål istället för ett ringbuffertmål:
| Baslinjebatchbegäranden per sekund (2 minuter i genomsnitt) | SQL Profiler Batch Requests per Second (2 minuter i genomsnitt) |
|---|---|
| 14 492 | 4 299 |
De bästa väntetyperna var följande:
| wait_type | waiting_tasks_count | väntetid_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 2 103 | 299 996 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 003 |
| SLEEP_TASK | 253 | 180 663 |
| LAZYWRITER_SLEEP | 120 | 120 187 |
| HADR_WORK_QUEUE | 12 | 120 029 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 019 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 011 |
| VÄNTA | 1 | 120 001 |
| XE_TIMER_EVENT | 59 | 119 966 |
| LOGMGR_QUEUE | 935 | 119 957 |
Ingenting, med undantag för XE_TIMER_EVENT , hoppade ut som XE-relaterad. Bob Wards Wait Type Repository hänvisar till den här som säker att ignorera om det inte var något möjligt fel - men realistiskt sett skulle du märka denna vanligtvis godartade väntetyp om den var på plats 9 på ditt system under en prestandaförsämring? Och vad händer om du redan filtrerar bort det på grund av dess normalt godartade natur?
Utökade händelser till ett långsamt I/O-sökvägsfilmål
Vad händer nu om jag lägger filen på en långsam I/O-väg? Följande tabell visar batchförfrågningar före och efter per sekund när du aktiverar en XE-session med ett filmål på ett USB-minne:
| Baslinjebatchbegäranden per sekund (2 minuter i genomsnitt) | SQL Profiler Batch Requests per Second (2 minuter i genomsnitt) |
|---|---|
| 14 492 | 4 386 |
De bästa väntetyperna var följande:
| wait_type | waiting_tasks_count | väntetid_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 046 |
| SLEEP_TASK | 253 | 180 719 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120 427 |
| LAZYWRITER_SLEEP | 120 | 120 190 |
| HADR_WORK_QUEUE | 12 | 120 025 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 013 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 011 |
| VÄNTA | 1 | 120 002 |
| DIRTY_PAGE_POLL | 1 197 | 119 977 |
| XE_TIMER_EVENT | 59 | 119 949 |
Återigen, inget XE-relaterat hoppar ut förutom XE_TIMER_EVENT .
Utökade händelser till ett långsamt I/O-sökvägsfilmål, ingen händelseförlust
Följande tabell visar före- och efter-batchförfrågningar per sekund när du aktiverar en XE-session med ett filmål på ett USB-minne, men den här gången utan att tillåta händelseförlust (EVENT_RETENTION_MODE=NO_EVENT_LOSS) – vilket inte rekommenderas och du kommer att se i resultaten varför det kan vara:
| Baslinjebatchbegäranden per sekund (2 minuter i genomsnitt) | SQL Profiler Batch Requests per Second (2 minuter i genomsnitt) |
|---|---|
| 14 492 | 539 |
De bästa väntetyperna var följande:
| wait_type | waiting_tasks_count | väntetid_ms |
|---|---|---|
| XE_BUFFERMGR_FREEBUF_EVENT | 8 773 | 1 707 845 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 003 |
| SLEEP_TASK | 337 | 180 446 |
| LAZYWRITER_SLEEP | 120 | 120 032 |
| DIRTY_PAGE_POLL | 1 198 | 120 026 |
| HADR_WORK_QUEUE | 12 | 120 009 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 007 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 006 |
| VÄNTA | 1 | 120 000 |
| XE_TIMER_EVENT | 59 | 119 944 |
Med den extrema genomströmningsminskningen ser vi XE_BUFFERMGR_FREEBUF_EVENT hoppa till nummer ett på våra ackumulerade väntetidsresultat. Den här är dokumenteras i Books Online, och Microsoft berättar för oss att denna händelse är associerad med XE-sessioner som är konfigurerade för ingen händelseförlust och där alla buffertar i sessionen är fulla.
Observatörspåverkan
Bortsett från väntetyperna var det intressant att notera vilken inverkan varje observationsmetod hade på vår arbetsbelastnings förmåga att behandla batchförfrågningar:
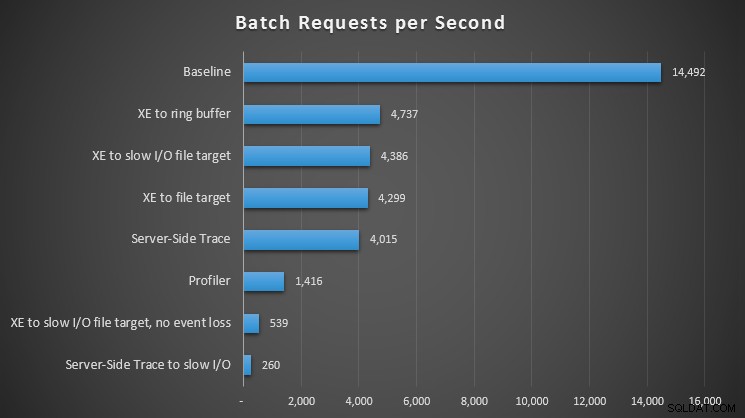
Inverkan av olika observationsmetoder på batchförfrågningar per sekund
För alla tillvägagångssätt fanns det en signifikant – men inte chockerande – träff jämfört med vår baslinje (ingen observation); Den största smärtan kändes dock när du använde Profiler, när du använde Server-Side Trace till en långsam I/O-sökväg, eller utökade händelser till ett filmål på en långsam I/O-sökväg – men bara när den konfigurerades för ingen händelseförlust. Med händelseförlust fungerade den här installationen faktiskt i nivå med ett filmål till en snabb I/O-sökväg, förmodligen för att den kunde släppa mycket fler händelser.
Sammanfattning
Jag testade inte alla möjliga scenarier och det finns säkert andra intressanta kombinationer (för att inte tala om olika beteenden baserade på SQL Server-versionen), men den viktigaste slutsatsen jag drar från denna utforskning är att du inte alltid kan lita på en uppenbar ackumulering av väntetyp. pekare när du står inför ett observatörsscenario. Baserat på testerna i det här inlägget, visade endast tre av sju scenarier en specifik väntetyp som potentiellt skulle kunna hjälpa dig att peka i rätt riktning. Redan då – dessa tester var på ett kontrollerat system – och ofta filtrerar folk bort de tidigare nämnda väntetyperna som godartade bakgrundstyper – så att du kanske inte ser dem alls.
Med tanke på detta, vad kan du göra? För prestandaförsämring utan tydliga eller uppenbara symtom, rekommenderar jag att du breddar omfattningen för att fråga om spår och XE-sessioner (som en åtskillnad – jag rekommenderar också att du utökar omfattningen om systemet är virtualiserat eller kan ha felaktiga strömalternativ). Till exempel, som en del av felsökning av ett system, kontrollera sys.[traces] och sys.[dm_xe_sessions] för att se om något körs på systemet som är oväntat. Det är ett extra lager till det du behöver oroa dig för, men att göra några snabba valideringar kan spara en hel del tid.