Introduktion
Sedan deras introduktion i SQL Server 2005 fungerar fönster som ROW_NUMBER och RANK har visat sig vara extremt användbara för att lösa en mängd olika vanliga T-SQL-problem. I ett försök att generalisera sådana lösningar försöker databasdesigners ofta att införliva dem i vyer för att främja kodinkapsling och återanvändning. Tyvärr innebär en begränsning i SQL Server-frågeoptimeraren ofta att vyer som innehåller fönsterfunktioner inte fungerar så bra som förväntat. Det här inlägget går igenom ett illustrativt exempel på problemet, beskriver orsakerna och ger ett antal lösningar.
Det här problemet kan också uppstå i härledda tabeller, vanliga tabelluttryck och inline-funktioner, men jag ser det oftast med vyer eftersom de avsiktligt är skrivna för att vara mer generiska.
Fönsterfunktioner
Fönsterfunktioner kännetecknas av närvaron av en OVER() klausul och finns i tre varianter:
- Rankningsfönsterfunktioner
ROW_NUMBERRANKDENSE_RANKNTILE
- Aggregerade fönsterfunktioner
MIN,MAX,AVG,SUMCOUNT,COUNT_BIGCHECKSUM_AGGSTDEV,STDEVP,VAR,VARP
- Analytiska fönsterfunktioner
LAG,LEADFIRST_VALUE,LAST_VALUEPERCENT_RANK,PERCENTILE_CONT,PERCENTILE_DISC,CUME_DIST
Funktionerna för rangordning och aggregerade fönster introducerades i SQL Server 2005 och utökades avsevärt i SQL Server 2012. De analytiska fönsterfunktionerna är nya för SQL Server 2012.
Alla fönsterfunktioner som anges ovan är mottagliga för optimeringsbegränsningen som beskrivs i den här artikeln.
Exempel
Med hjälp av exempeldatabasen AdventureWorks är uppgiften att skriva en fråga som returnerar alla produkt #878-transaktioner som inträffade på det senaste tillgängliga datumet. Det finns alla möjliga sätt att uttrycka detta krav i T-SQL, men vi kommer att välja att skriva en fråga som använder en fönsterfunktion. Det första steget är att hitta transaktionsposter för produkt #878 och rangordna dem i fallande datumordning:
VÄLJ th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Quantity, rnk =RANK() OVER (ORDER BY th.TransactionDate DESC)FROM Production.TransactionHistory AS thWHERE th.ProductID =878ORDER BY rnk; före>
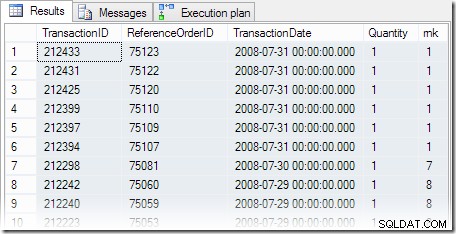
Resultaten av frågan är som förväntat, med sex transaktioner som inträffade på det senaste tillgängliga datumet. Utförandeplanen innehåller en varningstriangel som varnar oss om ett saknat index:
Som vanligt för saknade indexförslag måste vi komma ihåg att rekommendationen inte är resultatet av en genomgående analys av frågan – det är mer en indikation på att vi måste tänka lite på hur denna fråga kommer åt den data den behöver.
Det föreslagna indexet skulle förvisso vara mer effektivt än att skanna tabellen helt, eftersom det skulle tillåta en indexsökning till den specifika produkt vi är intresserade av. Indexet skulle också täcka alla de kolumner som behövs, men det skulle inte undvika sorteringen (av
TransactionDatenedåtgående). Det idealiska indexet för den här frågan skulle tillåta en sökning påProductID, returnera de valda posterna i omvändTransactionDateordning och täck de andra returnerade kolumnerna:SKAPA INKLUSTERAT INDEX ixON Production.TransactionHistory (ProductID, TransactionDate DESC)INCLUDE (ReferenceOrderID, Quantity);Med det indexet på plats är genomförandeplanen mycket mer effektiv. Den klustrade indexsökningen har ersatts av en intervallsökning, och en explicit sortering är inte längre nödvändig:
Det sista steget för den här frågan är att begränsa resultaten till bara de rader som rankas #1. Vi kan inte filtrera direkt i
WHEREsats i vår fråga eftersom fönsterfunktioner endast kan visas iSELECTochORDER BYklausuler.Vi kan kringgå denna begränsning med hjälp av en härledd tabell, vanligt tabelluttryck, funktion eller vy. Vid det här tillfället kommer vi att använda ett vanligt tabelluttryck (aka en in-line-vy):
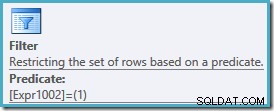
MED rankade transaktioner AS( SELECT th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Quantity, rnk =RANK() OVER (ORDER BY th.TransactionDate DESC) FROM Production.TransactionHistory AS th WHERE th.ProductID =878 )SELECT TransactionID, ReferenceOrderID, TransactionDate, QuantityFROM rankedTransactionsWHERE rnk =1;Utförandeplanen är densamma som tidigare, med ett extra filter för att endast returnera rader rankade #1:
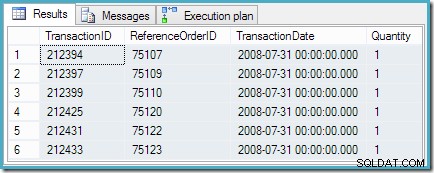
Frågan returnerar de sex lika rankade rader som vi förväntar oss:
Generalisera frågan
Det visar sig att vår fråga är mycket användbar, så beslutet fattas att generalisera den och lagra definitionen i en vy. För att detta ska fungera för alla produkter måste vi göra två saker:returnera
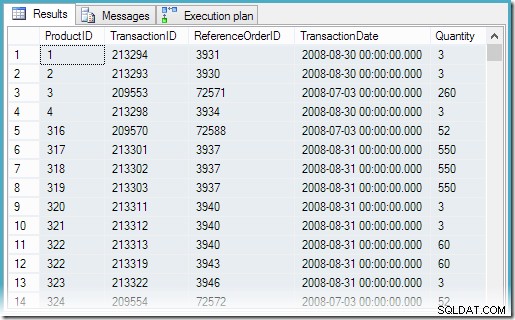
ProductIDfrån vyn och dela upp rankningsfunktionen efter produkt:SKAPA VISNING dbo.MostRecentTransactionsPerProductWITH SCHEMABINDINGASSELECT sq1.ProductID, sq1.TransactionID, sq1.ReferenceOrderID, sq1.TransactionDate, sq1.QuantityFROM ( SELECT th.ProductID, th.ReactionID, th.Reaction-ID, th.Transactionth.Orth. rnk =RANK() OVER ( PARTITION BY th.ProductID ORDER BY th.TransactionDate DESC) FROM Production.TransactionHistory AS th) AS sq1WHERE sq1.rnk =1;Att välja alla rader från vyn resulterar i följande utförandeplan och korrekta resultat:
Vi kan nu hitta de senaste transaktionerna för produkt 878 med en mycket enklare fråga på vyn:
SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =878;Vår förväntning är att exekveringsplanen för den här nya frågan kommer att vara exakt densamma som innan vi skapade vyn. Frågeoptimeraren bör kunna trycka på filtret som anges i
WHEREklausul ner i vyn, vilket resulterar i en indexsökning.Vi måste dock stanna upp och fundera lite nu. Frågeoptimeraren kan bara producera exekveringsplaner som garanterat ger samma resultat som den logiska frågespecifikationen – är det säkert att driva vår
WHEREklausul i vyn?PARTITION BY klausul i fönsterfunktionen i vyn. Resonemanget är att eliminering av kompletta grupper (partitioner) från fönsterfunktionen inte kommer att påverka rangordningen av rader som returneras av frågan. Frågan är, vet SQL Server-frågeoptimeraren detta? Svaret beror på vilken version av SQL Server vi kör. SQL Server 2005 exekveringsplan
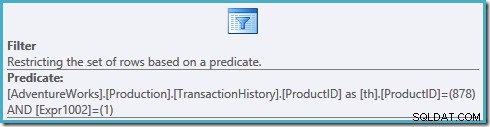
En titt på filteregenskaperna i denna plan visar att den tillämpar två predikat:
ProductID = 878predikatet har inte tryckts ner i vyn, vilket resulterar i en plan som skannar vårt index, rankar varje rad i tabellen innan den filtreras efter produkt #878 och rader rankade #1.SQL Server 2005-frågeoptimeraren kan inte skjuta lämpliga predikat förbi en fönsterfunktion i ett lägre frågeomfång (vy, vanligt tabelluttryck, in-line-funktion eller härledd tabell). Denna begränsning gäller för alla SQL Server 2005-byggen.
SQL Server 2008+ exekveringsplan
Detta är exekveringsplanen för samma fråga på SQL Server 2008 eller senare:
ProductIDPredikatet har framgångsrikt förts förbi rankningsoperatorerna och ersätter indexsökningen med den effektiva indexsökningen.2008 års frågeoptimerare inkluderar en ny förenklingsregel
SelOnSeqPrj(välj på sekvensprojekt) som kan trycka på säkra yttre scope-predikater tidigare fönsterfunktioner. För att skapa en mindre effektiv plan för den här frågan i SQL Server 2008 eller senare måste vi tillfälligt inaktivera den här frågeoptimeringsfunktionen:SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =878OPTION (QUERYRULEOFF SelOnSeqPrj);
Tyvärr har
SelOnSeqPrjförenklingsregeln fungerar bara när predikatet utför en jämförelse med en konstant . Av den anledningen producerar följande fråga den suboptimala planen på SQL Server 2008 och senare:DECLARE @ProductID INT =878; VÄLJ mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =@ProductID;
Problemet kan fortfarande uppstå även om predikatet använder ett konstant värde. SQL Server kan besluta att autoparameterisera triviala frågor (en för vilken det finns en uppenbar bästa plan). Om den automatiska parametreringen lyckas, ser optimeraren en parameter istället för en konstant och
SelOnSeqPrjregeln tillämpas inte.För frågor där automatisk parametrering inte har försökts (eller där det har fastställts att det är osäkert), kan optimeringen fortfarande misslyckas, om databasalternativet för
FORCED PARAMETERIZATIONär på. Vår testfråga (med det konstanta värdet 878) är inte säker för automatisk parametrering, men inställningen för forcerad parametrering åsidosätter detta, vilket resulterar i den ineffektiva planen:ÄNDRAR DATABAS AdventureWorksSET PARAMETERISERING TVÄNGD;GOSELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE MRT.>
SQL Server 2008+ Lösning
För att tillåta optimeraren att "se" ett konstant värde för en fråga som refererar till en lokal variabel eller parameter kan vi lägga till en
OPTION (RECOMPILE)frågetips:DECLARE @ProductID INT =878; VÄLJ mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =@ProductIDOPTION (RECOMPILE);Obs! Exekveringsplanen för pre-exekvering ('uppskattad') visar fortfarande en indexskanning eftersom värdet på variabeln faktiskt inte är inställt ännu. När frågan körs , dock visar exekveringsplanen den önskade indexsökplanen:
SelOnSeqPrjregeln finns inte i SQL Server 2005, såOPTION (RECOMPILE)kan inte hjälpa där. Om du undrar,OPTION (RECOMPILE)lösningen resulterar i en sökning även om databasalternativet för forcerad parametrering är aktiverat.Alla versioner lösning #1
I vissa fall är det möjligt att ersätta den problematiska vyn, det vanliga tabelluttrycket eller den härledda tabellen med en parameteriserad in-line-tabellvärderad funktion:
CREATE FUNCTION dbo.MostRecentTransactionsForProduct( @ProductID heltal) RETURNERAR TABELL MED SCHEMABINDING ASRETURN SELECT sq1.ProductID, sq1.TransactionID, sq1.ReferenceOrderID, sq1.TransactionDate, sq1.SELECTID FTransaction. SELECTID. ReferenceOrderID, th.TransactionDate, th.Quantity, rnk =RANK() OVER ( PARTITION BY th.ProductID ORDER BY th.TransactionDate DESC) FRÅN Production.TransactionHistory AS th WHERE th.ProductID =@ProductID ) AS sq1 WHERE =sq1 WHERE 1;Denna funktion placerar uttryckligen
ProductIDpredikat i samma omfattning som fönsterfunktionen, vilket undviker optimeringsbegränsningen. Skrivet för att använda in-line-funktionen, blir vår exempelfråga:SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsForProduct(878) AS mrt;Detta ger den önskade indexsökplanen på alla versioner av SQL Server som stöder fönsterfunktioner. Den här lösningen skapar en sökning även där predikatet refererar till en parameter eller lokal variabel –
OPTION (RECOMPILE)krävs inte.PARTITION BY och för att inte längre returnera ProductIDkolumn. Jag lämnade definitionen på samma sätt som uppfattningen den ersatte för att tydligare illustrera orsaken till skillnaderna i genomförandeplanen.Alla versioner lösning #2
Den andra lösningen gäller endast rankningsfönsterfunktioner som filtreras för att returnera rader numrerade eller rankade #1 (med
ROW_NUMBER,RANK, ellerDENSE_RANK). Detta är dock en mycket vanlig användning, så det är värt att nämna.En ytterligare fördel är att den här lösningen kan skapa planer som är ännu mer effektiva än indexsökplanerna sett tidigare. Som en påminnelse såg den tidigare bästa planen ut så här:
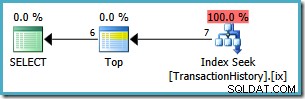
Den genomförandeplanen rankas 1 918 rader även om det i slutändan bara returnerar 6 . Vi kan förbättra denna exekveringsplan genom att använda fönsterfunktionen i en
ORDER BYsats istället för att rangordna rader och sedan filtrera efter rang #1:VÄLJ TOP (1) MED TIES th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.QuantityFROM Production.TransactionHistory AS thWHERE th.ProductID =878ORDER BY RANK() OVER (ORDER BY th.
Den frågan illustrerar på ett bra sätt användningen av en fönsterfunktion i
ORDER BYklausul, men vi kan göra ännu bättre genom att helt eliminera fönsterfunktionen:VÄLJ TOP (1) MED TIES th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.QuantityFROM Production.TransactionHistory AS thWHERE th.ProductID =878ORDER BY th.TransactionDate DESC;
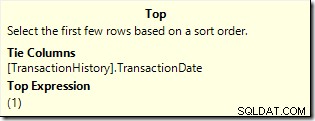
Denna plan läser endast 7 rader från tabellen för att returnera samma 6-rads resultatuppsättning. Varför 7 rader? Topoperatorn körs i
WITH TIESläge:
Den fortsätter att begära en rad i taget från dess underträd tills TransactionDate ändras. Den sjunde raden krävs för att toppen ska vara säker på att inga fler rader med jämna värden kommer att kvalificera sig.
Vi kan utöka logiken i frågan ovan för att ersätta den problematiska vydefinitionen:
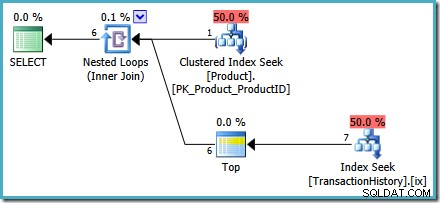
ALTER VIEW dbo.MostRecentTransactionsPerProductWITH SCHEMABINDINGASSELECT p.ProductID, Rankad1.TransaktionsID, Rankad1.ReferensOrderID, Rankad1.Transaktionsdatum, Rankad1.QuantityFROM -- Lista över produkt-ID:n (VÄLJ produkt-ID FRÅN Produktion.Produkt) SOM pCROSS GÄLLER( -- Returer GÄLLER( #1-resultat för varje produkt-ID VÄLJ TOP (1) MED BÅND th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Quantity FROM Production.TransactionHistory AS th WHERE th.ProductID =p.ProductID ORDER BY th.TransactionDate DESC) AS rankad 1;Vyn använder nu en
CROSS APPLYför att kombinera resultaten av vår optimeradeORDER BYfråga för varje produkt. Vår testfråga är oförändrad:DECLARE @ProductID heltal;SET @ProductID =878; VÄLJ mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =@ProductID;Både pre- och post-exekveringsplaner visar en indexsökning utan att behöva ett
OPTION (RECOMPILE)frågetips. Följande är en efterutförande ('faktisk') plan:
Om vyn hade använt
ROW_NUMBERistället förRANK, skulle ersättningsvyn helt enkelt ha utelämnatWITH TIESsats påTOP (1). Den nya vyn kan naturligtvis också skrivas som en parameteriserad in-line-tabellvärderad funktion.Man skulle kunna hävda att den ursprungliga indexsökplanen med
rnk = 1Predikat kan också optimeras för att endast testa 7 rader. När allt kommer omkring bör optimeraren veta att rankningar produceras av Sequence Project-operatören i strikt stigande ordning, så exekveringen kan sluta så snart en rad med en rankning som är större än ett ses. Optimeraren innehåller dock inte denna logik idag.Sluta tankar
Människor blir ofta besvikna över prestanda för vyer som innehåller fönsterfunktioner. Orsaken kan ofta spåras tillbaka till optimeringsbegränsningen som beskrivs i det här inlägget (eller kanske för att vydesignern inte insåg att predikat som tillämpas på vyn måste visas i
PARTITION BYklausul för att säkert tryckas ned).Jag vill betona att den här begränsningen inte bara gäller för visningar, och den är inte heller begränsad till
ROW_NUMBER,RANKochDENSE_RANK. Du bör vara medveten om denna begränsning när du använder någon funktion med enOVERsats i en vy, vanligt tabelluttryck, härledd tabell eller inline-tabellvärderad funktion.SQL Server 2005-användare som stöter på detta problem ställs inför valet att skriva om vyn som en parametriserad in-line tabellvärderad funktion, eller använda
APPLYteknik (där tillämpligt).SQL Server 2008-användare har det extra alternativet att använda ett
OPTION (RECOMPILE)frågetips om problemet kan lösas genom att låta optimeraren se en konstant istället för en variabel eller parameterreferens. Kom dock ihåg att kontrollera efterutförandeplanerna när du använder denna ledtråd:planen före utförande kan i allmänhet inte visa den optimala planen.