
Alldeles för ofta ser jag folk som klagar på hur deras transaktionslogg tog över deras hårddisk. Många gånger visar det sig att de utförde en stor raderingsoperation, som att rensa eller arkivera data, i en stor transaktion.
Jag ville köra några tester för att visa effekten, på både varaktighet och transaktionsloggen, av att utföra samma dataoperation i bitar jämfört med en enskild transaktion. Jag skapade en databas och fyllde den med en stor tabell SalesOrderDetailEnlarged ,
Efter att ha fyllt i tabellen säkerhetskopierade jag databasen, säkerhetskopierade loggen och körde en DBCC SHRINKFILE (skjut mig inte) så att effekten på loggfilen kunde fastställas från en baslinje (med välveten om att dessa operationer *kommer* att få transaktionsloggen att växa).
Jag använde avsiktligt en mekanisk disk i motsats till en SSD. Även om vi kan börja se en mer populär trend att flytta till SSD, har det inte hänt ännu i tillräckligt stor skala; i många fall är det fortfarande för dyrt att göra det i stora lagringsenheter.
Testen
Så härnäst var jag tvungen att bestämma vad jag ville testa för störst effekt. Eftersom jag var inblandad i en diskussion med en kollega igår om att radera data i bitar, valde jag raderingar. Och eftersom det klustrade indexet i den här tabellen är på SalesOrderID , jag ville inte använda det – det skulle vara för enkelt (och skulle mycket sällan matcha hur borttagningar hanteras i verkligheten). Så jag bestämde mig istället för att gå efter en serie ProductID värden, vilket skulle säkerställa att jag skulle träffa ett stort antal sidor och kräva mycket loggning. Jag bestämde vilka produkter som skulle raderas genom följande fråga:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Detta gav följande resultat:
ProductID ProductCount --------- ------------ 870 187520 712 135280 873 134160
Detta skulle ta bort 456 960 rader (cirka 10 % av tabellen), fördelade på många beställningar. Detta är inte en realistisk ändring i detta sammanhang, eftersom det kommer att röra sig med förberäknade ordersummor, och du kan inte riktigt ta bort en produkt från en beställning som redan har skickats. Men genom att använda en databas som vi alla känner och älskar, är det analogt med att till exempel ta bort en användare från en forumsajt och även ta bort alla deras meddelanden – ett riktigt scenario som jag har sett i det vilda.
Så ett test skulle vara att utföra följande, engångsradering:
DELETE dbo.SalesOrderDetailEnlarged WHERE ProductID IN (712, 870, 873);
Jag vet att detta kommer att kräva en massiv genomsökning och ta en enorm vägtull på transaktionsloggen. Det är liksom poängen. :-)
Medan det kördes satte jag ihop ett annat skript som kommer att utföra denna radering i bitar:25 000, 50 000, 75 000 och 100 000 rader åt gången. Varje del kommer att committeras i sin egen transaktion (så att om du behöver stoppa skriptet kan du det, och alla tidigare bitar kommer redan att committeras, istället för att behöva börja om), och kommer att följas beroende på återställningsmodellen antingen med en CHECKPOINT eller en BACKUP LOG för att minimera den pågående påverkan på transaktionsloggen. (Jag kommer också att testa utan dessa operationer.) Det kommer att se ut ungefär så här (jag tänker inte störa mig på felhantering och andra snällheter för det här testet, men du ska inte vara lika kavaljer):
SET NOCOUNT ON;
DECLARE @r INT;
SET @r = 1;
WHILE @r > 0
BEGIN
BEGIN TRANSACTION;
DELETE TOP (100000) -- this will change
dbo.SalesOrderDetailEnlarged
WHERE ProductID IN (712, 870, 873);
SET @r = @@ROWCOUNT;
COMMIT TRANSACTION;
-- CHECKPOINT; -- if simple
-- BACKUP LOG ... -- if full
END
Naturligtvis, efter varje test, skulle jag återställa den ursprungliga säkerhetskopian av databasen WITH REPLACE, RECOVERY , ställ in återställningsmodellen därefter och kör nästa test.
Resultaten
Resultatet av det första testet var inte alls särskilt överraskande. För att utföra raderingen i ett enda uttalande tog det 42 sekunder i sin helhet och 43 sekunder i det enkla. I båda fallen ökade detta loggen till 579 MB.
Nästa uppsättning tester hade ett par överraskningar för mig. En är att även om dessa chunking-metoder avsevärt minskade effekten på loggfilen, var det bara ett par kombinationer som var nära, och ingen var faktiskt snabbare. En annan är att chunking i full återställning (utan att utföra en loggsäkerhetskopiering mellan stegen) i allmänhet fungerade bättre än motsvarande operationer vid enkel återställning. Här är resultaten för varaktighet och loggpåverkan:
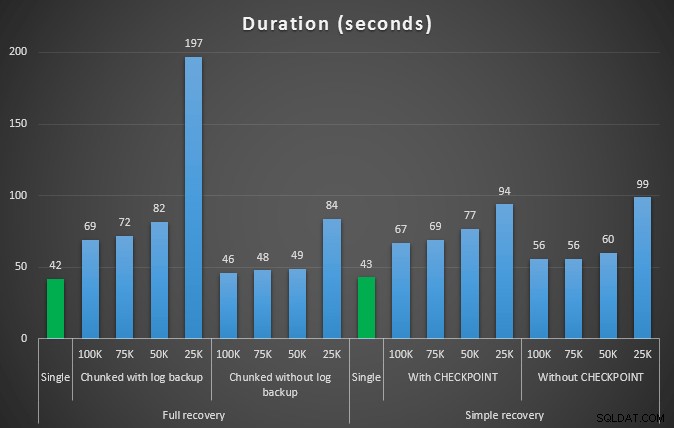
Längden, i sekunder, av olika raderingsoperationer som tar bort 457 000 rader
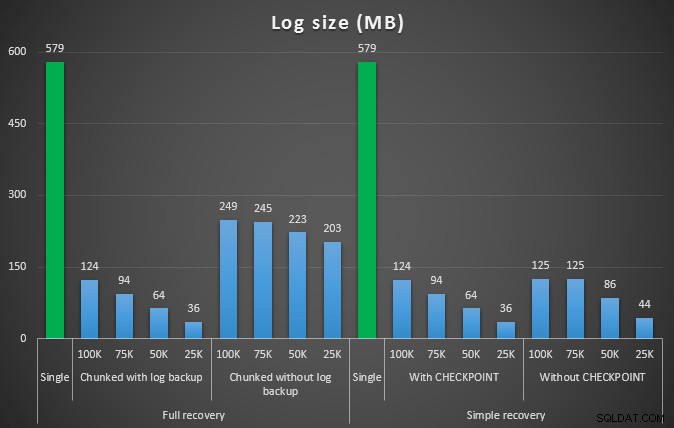
Loggstorlek, i MB, efter olika raderingsoperationer som tar bort 457 000 rader
Återigen, i allmänhet, medan stockstorleken minskar avsevärt, ökar varaktigheten. Du kan använda den här typen av skala för att avgöra om det är viktigare att minska påverkan på diskutrymmet eller att minimera tidsåtgången. För en liten träff i varaktighet (och trots allt körs de flesta av dessa processer i bakgrunden) kan du ha en betydande besparing (upp till 94 %, i dessa tester) i loggutrymmesanvändning.
Observera att jag inte provade något av dessa test med komprimering aktiverad (möjligen ett framtida test!), och jag lämnade logginställningarna för autogrow på de fruktansvärda standardvärdena (10%) – dels av lättja och dels för att många miljöer där ute har behållit denna hemska miljö.
Men vad händer om jag har mer data?
Nästa tänkte jag att jag skulle testa detta på en lite större databas. Så jag skapade en annan databas och skapade en ny, större kopia av dbo.SalesOrderDetailEnlarged . Ungefär tio gånger större, faktiskt. Den här gången istället för en primärnyckel på SalesOrderID, SalesorderDetailID , jag gjorde det bara till ett klustrat index (för att tillåta dubbletter) och fyllde i det så här:
SELECT c.*
INTO dbo.SalesOrderDetailReallyReallyEnlarged
FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged AS c
CROSS JOIN
(
SELECT TOP 10 Number FROM master..spt_values
) AS x;
CREATE CLUSTERED INDEX so ON dbo.SalesOrderDetailReallyReallyEnlarged
(SalesOrderID,SalesOrderDetailID);
-- I also made this index non-unique:
CREATE NONCLUSTERED INDEX rg ON dbo.SalesOrderDetailReallyReallyEnlarged(rowguid);
CREATE NONCLUSTERED INDEX p ON dbo.SalesOrderDetailReallyReallyEnlarged(ProductID); På grund av diskutrymmesbegränsningar var jag tvungen att flytta bort från min bärbara dators virtuella dator för det här testet (och valde en 40-kärnig box, med 128 GB RAM, som bara råkade sitta kvar nästan tomgång :-)), och fortfarande det var inte en snabb process på något sätt. Fyllning av tabellen och skapande av index tog ~24 minuter.
Tabellen har 48,5 miljoner rader och tar upp 7,9 GB i disk (4,9 GB i data och 2,9 GB i index).
Den här gången, min fråga för att bestämma en bra uppsättning kandidat ProductID värden att radera:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailReallyReallyEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Gav följande resultat:
ProductID ProductCount --------- ------------ 870 1828320 712 1318980 873 1308060
Så vi kommer att ta bort 4 455 360 rader, lite under 10 % av tabellen. Efter ett liknande mönster som testet ovan, kommer vi att ta bort allt i ett skott, sedan i bitar av 500 000, 250 000 och 100 000 rader.
Resultat:
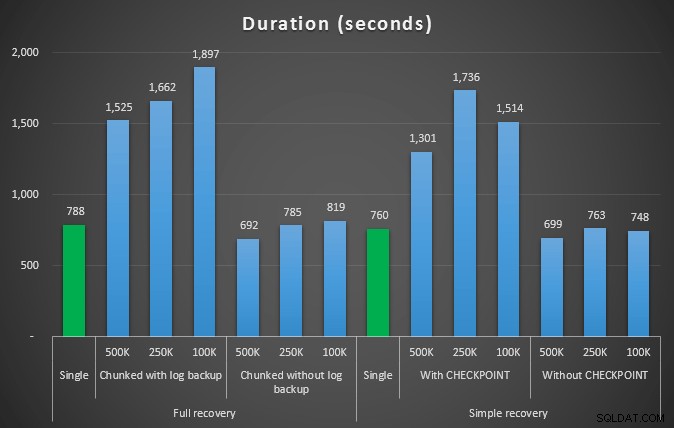 Längden, i sekunder, av olika raderingsoperationer som tar bort 4,5 mm rader
Längden, i sekunder, av olika raderingsoperationer som tar bort 4,5 mm rader
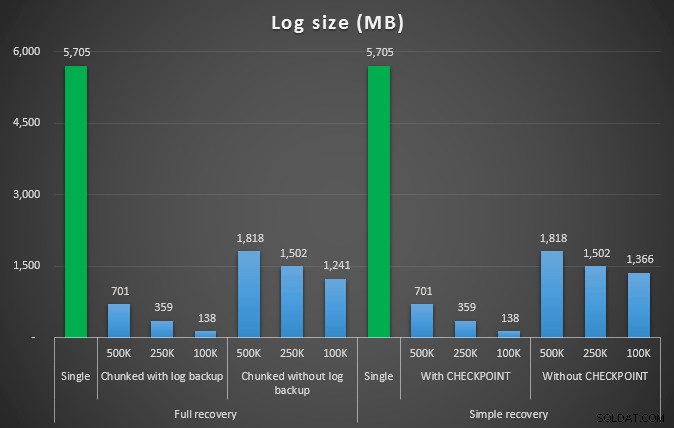 Loggstorlek, i MB, efter olika raderingsoperationer som tar bort 4,5 mm rader
Loggstorlek, i MB, efter olika raderingsoperationer som tar bort 4,5 mm rader
Så återigen ser vi en betydande minskning av loggfilstorleken (över 97 % i fall med den minsta bitstorleken på 100K); Men i den här skalan ser vi några fall där vi också åstadkommer borttagningen på kortare tid, även med alla autogrow-händelser som måste ha inträffat. Det låter väldigt mycket som win-win för mig!
Den här gången med en större logg
Nu var jag nyfiken på hur dessa olika raderingar skulle jämföras med en loggfil som är förinställd för att rymma så stora operationer. Jag höll mig till vår större databas och förexpanderade loggfilen till 6 GB, säkerhetskopierade den och körde sedan testerna igen:
ALTER DATABASE delete_test MODIFY FILE (NAME=delete_test_log, SIZE=6000MB);
Resultat, att jämföra varaktigheten med en fast loggfil med fallet där filen måste växa automatiskt kontinuerligt:
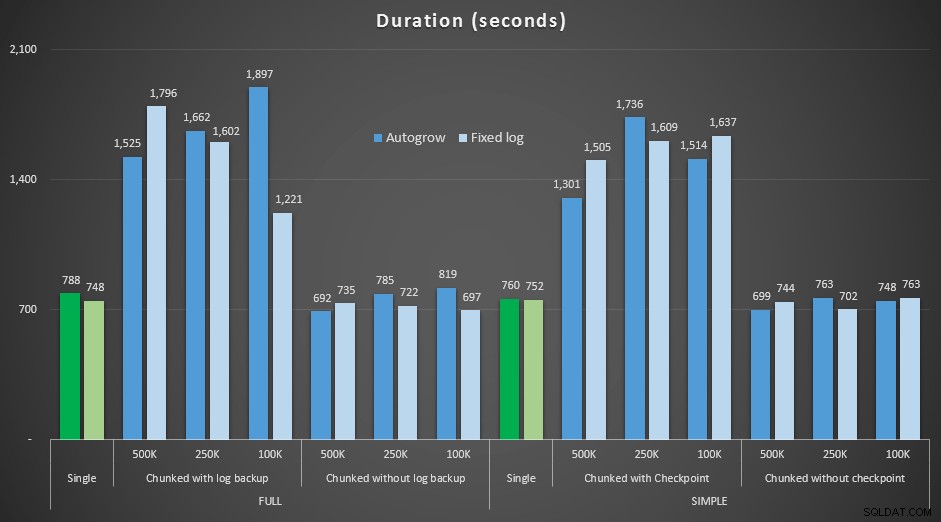
Längden, i sekunder, av olika raderingsoperationer som tar bort 4,5 mm rader , jämför fast loggstorlek och autogrow
Återigen ser vi att metoderna som delar raderingar i partier, och *inte* utför en loggbackup eller en kontrollpunkt efter varje steg, konkurrerar med motsvarande enstaka operation när det gäller varaktighet. Se faktiskt att de flesta faktiskt presterar på kortare totaltid, med den extra bonusen att andra transaktioner kommer att kunna komma in och ut mellan stegen. Vilket är bra om du inte vill att denna raderingsoperation ska blockera alla orelaterade transaktioner.
Slutsats
Det är tydligt att det inte finns något enskilt, korrekt svar på detta problem – det finns många inneboende "det beror på"-variabler. Det kan ta lite experimenterande för att hitta ditt magiska nummer, eftersom det kommer att finnas en balans mellan den omkostnad som krävs för att säkerhetskopiera loggen och hur mycket arbete och tid du sparar vid olika bitstorlekar. Men om du planerar att ta bort eller arkivera ett stort antal rader, är det ganska troligt att du generellt sett kommer att bli bättre av att utföra ändringarna i bitar, snarare än i en, massiv transaktion – även om varaktighetstalen verkar vara att en mindre attraktiv verksamhet. Allt handlar inte om varaktighet – om du inte har en tillräckligt förtilldelad loggfil och inte har utrymme för att ta emot en sådan massiv transaktion, är det förmodligen mycket bättre att minimera loggfilstillväxten till kostnaden för varaktigheten, i så fall vill du ignorera varaktighetsdiagrammen ovan och vara uppmärksam på loggstorleksdiagrammen.
Om du har råd med utrymmet, kanske du fortfarande vill eller kanske inte vill anpassa din transaktionslogg i förväg. Beroende på scenariot gick det ibland att använda standardinställningarna för autogrow något snabbare i mina tester än att använda en fast loggfil med gott om utrymme. Dessutom kan det vara svårt att gissa exakt hur mycket du behöver för att klara en stor transaktion som du inte har kört ännu. Om du inte kan testa ett realistiskt scenario, gör ditt bästa för att föreställa dig ditt värsta scenario – för säkerhets skull, fördubbla det sedan. Kimberly Tripp (blogg | @KimberlyLTripp) har några bra råd i det här inlägget:8 steg för att förbättra transaktionslogggenomströmningen – i detta sammanhang, specifikt, titta på punkt #6. Oavsett hur du bestämmer dig för att beräkna dina utrymmeskrav för loggar, om du ändå kommer att behöva utrymmet, är det bättre att ta det på ett kontrollerat sätt i god tid än att stoppa dina affärsprocesser medan de väntar på en autotillväxt ( strunt samma i flera!).
En annan mycket viktig aspekt av detta som jag inte mätte explicit är effekten på samtidighet – ett gäng kortare transaktioner kommer i teorin att ha mindre inverkan på samtidiga operationer. Medan en enstaka radering tog något kortare tid än de längre, batchade operationerna, höll den alla sina lås under hela varaktigheten, medan de segmenterade operationerna skulle göra det möjligt för andra köade transaktioner att smyga in mellan varje transaktion. I ett framtida inlägg ska jag försöka ta en närmare titt på denna påverkan (och jag har planer på andra djupare analyser också).