I mitt förra inlägg startade jag en serie för att täcka proaktiva hälsokontroller som är avgörande för din SQL Server. Vi började med diskutrymme, och i det här inlägget kommer vi att diskutera underhållsuppgifter. En av de grundläggande skyldigheterna för en DBA är att se till att följande underhållsuppgifter körs regelbundet:
- Säkerhetskopiering
- Integritetskontroller
- Indexunderhåll
- Statistikuppdateringar
Min insats är att du redan har jobb på plats för att hantera dessa uppgifter. Och jag skulle också slå vad om att du har aviseringar konfigurerade för att skicka e-post till dig och ditt team om ett jobb misslyckas. Om båda är sanna, är du redan proaktiv när det gäller underhåll. Och om du inte gör båda, är det något att fixa just nu – som i, sluta läsa det här, ladda ner Ola Hallengrens skript, schemalägg dem och se till att du ställer in aviseringar. (Ett annat alternativ specifikt för indexunderhåll, som vi också rekommenderar till kunder, är SQL Sentry Fragmentation Manager.)
Om du inte vet om dina jobb är inställda på att skicka e-post till dig om de misslyckas, använd den här frågan:
SELECT [Name], [Description] FROM [dbo].[sysjobs] WHERE [enabled] = 1 AND [notify_level_email] NOT IN (2,3) ORDER BY [Name];
Att vara proaktiv när det gäller underhåll går dock ett steg längre. Utöver att bara se till att dina jobb löper måste du veta hur lång tid de tar. Du kan använda systemtabellerna i msdb för att övervaka detta:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
CASE [h].[run_status]
WHEN 0 THEN 'Failed'
WHEN 1 THEN 'Succeeded'
WHEN 2 THEN 'Retry'
WHEN 3 THEN 'Cancelled'
WHEN 4 THEN 'In Progress'
END AS [ExecutionStatus],
[h].[message] AS [MessageGenerated]
FROM [msdb].[dbo].[sysjobhistory] [h]
INNER JOIN [msdb].[dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [j].[name] = 'DatabaseBackup - SYSTEM_DATABASES – FULL'
AND [step_id] = 0
ORDER BY [RunDate]; Eller, om du använder Olas skript och loggningsinformation, kan du fråga hans CommandLog-tabell:
SELECT [DatabaseName], [CommandType], [StartTime], [EndTime], DATEDIFF(MINUTE, [StartTime], [EndTime]) AS [Duration_Minutes] FROM [master].[dbo].[CommandLog] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'BACKUP DATABASE%' ORDER BY [StartTime];
Skriptet ovan visar säkerhetskopieringstiden för varje fullständig säkerhetskopia för AdventureWorks2014-databasen. Du kan förvänta dig att underhållsuppgifternas varaktighet långsamt kommer att öka med tiden, allt eftersom databaser växer sig större. Som sådan letar du efter stora ökningar, eller oväntade minskningar, i varaktigheten. Till exempel hade jag en klient med en genomsnittlig säkerhetskopieringstid på mindre än 30 minuter. Helt plötsligt börjar säkerhetskopieringar ta mer än en timme. Databasen hade inte ändrats nämnvärt i storlek, inga inställningar hade ändrats för instansen eller databasen, ingenting hade ändrats med hårdvara eller diskkonfiguration. Några veckor senare sjönk säkerhetskopieringstiden tillbaka till mindre än en halvtimme. En månad efter det gick de upp igen. Vi korrelerade så småningom förändringen i backup-varaktighet till failovers mellan klusternoder. På en nod tog säkerhetskopieringarna mindre än en halvtimme. Å andra sidan tog de över en timme. En liten undersökning av konfigurationen av nätverkskortet och SAN-tyget och vi kunde lokalisera problemet.
Det är också viktigt att förstå den genomsnittliga exekveringstiden för CHECKDB-operationer. Detta är något som Paul pratar om i vår High Availability and Disaster recovery Immersion Event:du måste veta hur lång tid CHECKDB normalt tar att köra, så att om du hittar korruption och du kör en kontroll på hela databasen, vet du hur lång tid det bör ta för CHECKDB att slutföra. När din chef frågar, "Hur lång tid kvar tills vi vet omfattningen av problemet?" du kommer att kunna ge ett kvantitativt svar på den minsta tid du behöver vänta. Om CHECKDB tar längre tid än vanligt vet du att det har hittat något (som inte nödvändigtvis är korruption; du måste alltid låta kontrollen avslutas).
Nu, om du hanterar hundratals databaser, vill du inte köra ovanstående fråga för varje databas eller varje jobb. Istället kanske du bara vill hitta jobb som faller utanför den genomsnittliga varaktigheten med en viss procent, vilket du kan få med den här frågan:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
[avdur].[Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
INNER JOIN
(
SELECT
[j].[name] AS [JobName],
AVG((([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60))
AS [Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [step_id] = 0
AND CONVERT(DATE, RTRIM(h.run_date)) >= DATEADD(DAY, -60, GETDATE())
GROUP BY [j].[name]
) AS [avdur]
ON [avdur].[JobName] = [j].[name]
WHERE [step_id] = 0
AND (([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
> ([avdur].[Avg_RunDuration_Minutes] + ([avdur].[Avg_RunDuration_Minutes] * .25))
ORDER BY [j].[name], [RunDate]; Den här frågan listar jobb som tog 25 % längre tid än genomsnittet. Frågan kommer att kräva en del justeringar för att tillhandahålla den specifika information du vill ha – vissa jobb med kort varaktighet (t.ex. mindre än 5 minuter) kommer att dyka upp om de bara tar några extra minuter – det kanske inte är ett problem. Ändå är den här frågan en bra början, och inse att det finns många sätt att hitta avvikelser – du kan också jämföra varje utförande med den föregående och leta efter jobb som tog en viss procentandel längre tid än den föregående.
Uppenbarligen är jobbets varaktighet den mest logiska identifieraren att använda för potentiella problem – oavsett om det är ett backupjobb, en integritetskontroll eller jobbet som tar bort fragmentering och uppdaterar statistik. Jag har funnit att den största variationen i varaktighet vanligtvis ligger i uppgifterna att ta bort fragmentering och uppdatera statistik. Beroende på dina trösklar för omorganisering kontra ombyggnad, och volatiliteten i dina data, kan du gå dagar med mestadels omorganiseringar, och sedan plötsligt få ett par indexombyggnationer igång för stora tabeller, där dessa ombyggnader helt förändrar den genomsnittliga varaktigheten. Du kanske vill ändra dina trösklar för vissa index, eller justera fyllningsfaktorn, så att ombyggnader sker oftare eller mer sällan – beroende på index och fragmenteringsnivån. För att göra dessa justeringar måste du titta på hur ofta varje index byggs om eller omorganiseras, vilket du bara kan göra om du använder Olas skript och loggar till CommandLog-tabellen, eller om du har rullat din egen lösning och loggar varje omorganisation eller ombyggnad. För att titta på detta med CommandLog-tabellen kan du börja med att kontrollera vilka index som ändras oftast:
SELECT [DatabaseName], [ObjectName], [IndexName], COUNT(*) FROM [master].[dbo].[CommandLog] [c] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'ALTER INDEX%' GROUP BY [DatabaseName], [ObjectName], [IndexName] ORDER BY COUNT(*) DESC;
Från denna utdata kan du börja se vilka tabeller (och därmed index) som har störst volatilitet och sedan bestämma om tröskeln för omorganisering kontra ombyggnad behöver justeras eller fyllningsfaktorn ändras.
Gör livet enklare
Nu finns det en enklare lösning än att skriva dina egna frågor, så länge du använder SQL Sentry Event Manager (EM). Verktyget övervakar alla agentjobb som ställts in på en instans, och med hjälp av kalendervyn kan du snabbt se vilka jobb som misslyckades, avbröts eller körde längre än vanligt:
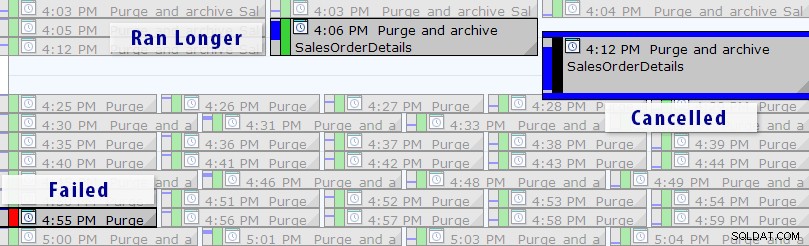 SQL Sentry Event Manager-kalendervy (med etiketter tillagda i Photoshop)
SQL Sentry Event Manager-kalendervy (med etiketter tillagda i Photoshop)
Du kan också borra i individuella körningar för att se hur mycket längre tid det tog ett jobb att köra, och det finns också praktiska körtidsdiagram som gör att du snabbt kan visualisera eventuella mönster i varaktighetsavvikelser eller feltillstånd. I det här fallet kan jag se att var 15:e minut ökade körtiden för detta specifika jobb med nästan 400 %:
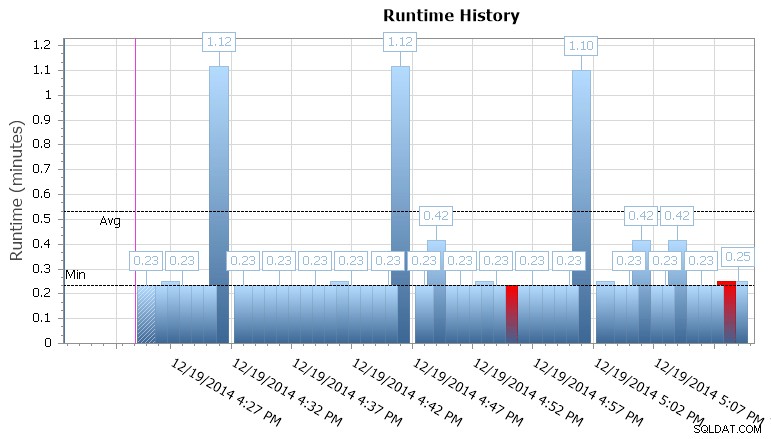 SQL Sentry Event Manager runtime-graf
SQL Sentry Event Manager runtime-graf
Detta ger mig en ledtråd om att jag bör undersöka andra schemalagda jobb som kan orsaka vissa samtidighetsproblem här. Jag skulle kunna zooma ut på kalendern igen för att se vilka andra jobb som körs samtidigt, eller så kanske jag inte ens behöver leta efter att det här är något rapporterings- eller säkerhetskopieringsjobb som körs mot den här databasen.
Sammanfattning
Jag skulle slå vad om att de flesta av er redan har de nödvändiga underhållsjobben på plats, och att ni också har aviseringar inställda för jobbmisslyckanden. Om du inte är bekant med den genomsnittliga varaktigheten för dina jobb, då är det ditt nästa steg i att vara proaktiv. Obs! Du kan också behöva kontrollera hur länge du behåller jobbhistoriken. När jag letar efter avvikelser i jobbets varaktighet föredrar jag att titta på några månaders data snarare än några veckor. Du behöver inte ha dessa körtider memorerade, men när du har verifierat att du har tillräckligt med data för att ha historiken att använda för forskning, börja sedan leta efter varianter regelbundet. I ett idealiskt scenario kan den ökade körtiden varna dig om ett potentiellt problem, så att du kan åtgärda det innan ett problem uppstår i din produktionsmiljö.