Ett av de filtrerade indexanvändningsfallen som nämns i Books Online gäller en kolumn som mest innehåller NULLs värden. Tanken är att skapa ett filtrerat index som exkluderar NULLs , vilket resulterar i ett mindre icke-klustrat index som kräver mindre underhåll än motsvarande ofiltrerade index. En annan populär användning av filtrerade index är att filtrera NULLs från en UNIQUE index, vilket ger det beteende som användare av andra databasmotorer kan förvänta sig av en standard UNIQUE index eller begränsning:unikhet upprätthålls endast för icke-NULLs värden.
Tyvärr har frågeoptimeraren begränsningar när det gäller filtrerade index. Det här inlägget tittar på ett par mindre kända exempel.
Exempeltabeller
Vi kommer att använda två tabeller (A &B) som har samma struktur:en surrogat-klustrad primärnyckel, en mestadels-NULLs kolumn som är unik (bortsett från NULLs ), och en utfyllnad kolumn som representerar de andra kolumner som kan finnas i en riktig tabell.
Intressekolumnen är mestadelsNULLs en, som jag har deklarerat som SPARSE . Det glesa alternativet krävs inte, jag inkluderar det bara eftersom jag inte får mycket chans att använda det. I alla fall SPARSE förmodligen vettigt i många scenarier där kolumndata förväntas vara mestadels NULLs . Ta gärna bort attributet sparse från exemplen om du vill.
CREATE TABLE dbo.TableA( pk heltal IDENTITY PRIMARY KEY, data bigint SPARSE NULL, padding binary(250) NOT NULL DEFAULT 0x); CREATE TABLE dbo.TableB( pk heltal IDENTITY PRIMARY KEY, data bigint SPARSE NULL, padding binary(250) NOT NULL DEFAULT 0x);
Varje tabell innehåller siffrorna från 1 till 2 000 i datakolumnen med ytterligare 40 000 rader där datakolumnen är NULLs :
-- Nummer 1 - 2 000INSERT dbo.TableA MED (TABLOCKX) (data)SELECT TOP (2000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL))FRÅN sys.columns AS cCROSS JOIN sys.columns AS c2ORDER BY ROW_NUMBER() ÖVER (ORDER BY (VÄLJ NULL)); -- NULLsINSERT TOP (40000) dbo.TableA MED (TABLOCKX) (data)SELECT CONVERT(bigint, NULL)FROM sys.columns AS cCROSS JOIN sys.columns AS c2; -- Kopiera till TableBINSERT dbo.TableB MED (TABLOCKX) (data)SELECT ta.dataFROM dbo.TableA AS ta;
Båda tabellerna får en UNIQUE filtrerat index för de 2 000 icke-NULLs datavärden:
SKAPA UNIKT INKLUSTERAT INDEX uqAON dbo.TableA (data) DÄR data INTE ÄR NULL; SKAPA UNIKT INKLUSTERAT INDEX uqBON dbo.TableB (data) DÄR data INTE ÄR NULL;
Utdata från DBCC SHOW_STATISTICS sammanfattar situationen:
DBCC SHOW_STATISTICS (TabellA, uqA) MED STAT_HEADER;DBCC SHOW_STATISTICS (TabellB, uqB) MED STAT_HEADER;

Exempelfråga
Frågan nedan utför en enkel sammanfogning av de två tabellerna – tänk dig att tabellerna är i någon sorts förälder-barn-relation och att många av de främmande nycklarna är NULL. Något i den stilen i alla fall.
SELECT ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data;
Standard exekveringsplan
Med SQL Server i standardkonfigurationen väljer optimeraren en exekveringsplan som innehåller en parallell kapslad loop-koppling:
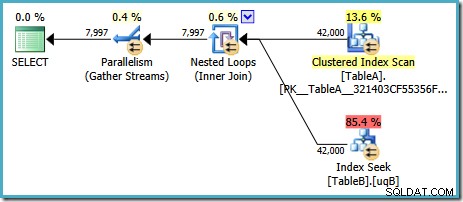
Denna plan har en beräknad kostnad på 7,7768 magic optimizer units™.
Det finns dock några konstiga saker med den här planen. Indexsökningen använder vårt filtrerade index i tabell B, men frågan drivs av en Clustered Index Scan av tabell A. Join-predikatet är ett likhetstest på datakolumnerna, vilket kommer att avvisa NULLs (oavsett ANSI_NULLS miljö). Vi kanske hade hoppats att optimeraren skulle utföra några avancerade resonemang baserat på den observationen, men nej. Denna plan läser varje rad från tabell A (inklusive de 40 000 NULLs ), utför en sökning i det filtrerade indexet i tabell B för var och en och förlitar sig på det faktum att NULLs kommer inte att matcha NULLs i det sökandet. Detta är ett enormt slöseri med ansträngning.
Det konstiga är att optimeraren måste ha insett att joinningen avvisar NULLs för att välja det filtrerade indexet för tabellen B-sök, men det tänkte inte på att filtrera NULLs från tabell A först – eller ännu bättre, för att helt enkelt skanna NULLs -gratis filtrerat index på tabell A. Du kanske undrar om detta är ett kostnadsbaserat beslut, kanske statistiken inte är särskilt bra? Vi kanske borde tvinga fram användningen av det filtrerade indexet med en antydan? Att antyda det filtrerade indexet på tabell A resulterar bara i samma plan med rollerna omvända – skanna tabell B och söka in i tabell A. Att tvinga fram det filtrerade indexet för båda tabellerna ger fel 8622 :frågeprocessorn kunde inte skapa en frågeplan.
Lägga till ett NOT NULL-predikat
misstänker att orsaken har att göra med den underförstådda NULLs -avvisande av join-predikatet lägger vi till en explicit NOT NULL predikat till ON satsen (eller WHERE om du föredrar det, kommer det till samma sak här):
VÄLJ ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data OCH ta.data ÄR INTE NULL;
Vi har lagt till NOT NULL kolla till kolumnen tabell A eftersom den ursprungliga planen skannade tabellens klustrade index istället för att använda vårt filtrerade index (sökningen i tabell B var bra – den använde det filtrerade indexet). Den nya frågan är semantiskt exakt densamma som den tidigare, men exekveringsplanen är annorlunda:
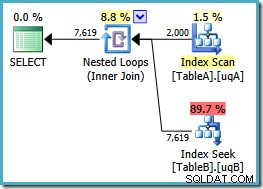
Nu har vi den efterlängtade genomsökningen av det filtrerade indexet i tabell A, vilket ger 2 000 icke-NULLs rader för att driva de kapslade loopsökningarna in i tabell B. Båda tabellerna använder våra filtrerade index tydligen optimalt nu:den nya planen kostar bara 0,362835 enheter (ned från 7,7768). Vi kan dock göra bättre.
Lägga till två NOT NULL-predikat
Den redundanta NOT NULL predikat för tabell A gjorde underverk; vad händer om vi lägger till en för tabell B också?
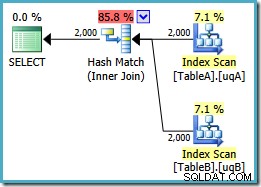
VÄLJ ta.data, tb.dataFRÅN dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data OCH ta.data ÄR INTE NULL OCH tb.data ÄR INTE NULL;
Denna fråga är fortfarande logiskt sett densamma som de två tidigare försöken, men genomförandeplanen är annorlunda igen:
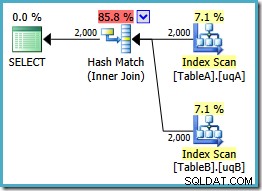
Den här planen bygger en hashtabell för de 2 000 raderna från tabell A och söker sedan efter matchningar med hjälp av de 2 000 raderna från tabell B. Det uppskattade antalet returnerade rader är mycket bättre än tidigare plan (märkte du uppskattningen på 7 619 där?) och den beräknade genomförandekostnaden har sjunkit igen, från 0,362835 till 0,0772056 .
Du kan prova att tvinga fram en hash-join med hjälp av en ledtråd om originalet eller singel-NOT NULL frågor, men du kommer inte att få lågkostnadsplanen som visas ovan. Optimeraren har helt enkelt inte förmågan att fullt ut resonera om NULLs -avvisande beteendet hos joinen eftersom det gäller våra filtrerade index utan båda redundanta predikaten.
Du får bli förvånad över detta – även om det bara är tanken att ett överflödigt predikat inte räckte (säkert om ta.data är NOT NULL och ta.data = tb.data , det följer att tb.data är också NOT NULL , eller hur?)
Fortfarande inte perfekt
Det är lite överraskande att se en hash gå med där. Om du är bekant med de huvudsakliga skillnaderna mellan de tre fysiska join-operatörerna vet du förmodligen att hash join är en toppkandidat där:
- Försorterad indata är inte tillgänglig
- Indata för hashbyggd är mindre än sondens indata
- Sondinmatningen är ganska stor
Ingen av dessa saker är sanna här. Vår förväntning skulle vara att den bästa planen för denna fråga och denna datauppsättning skulle vara en sammanfogning, som utnyttjar den ordnade indata som är tillgänglig från våra två filtrerade index. Vi kan försöka antyda en sammanfogning och behålla de två extra ON satspredikat:
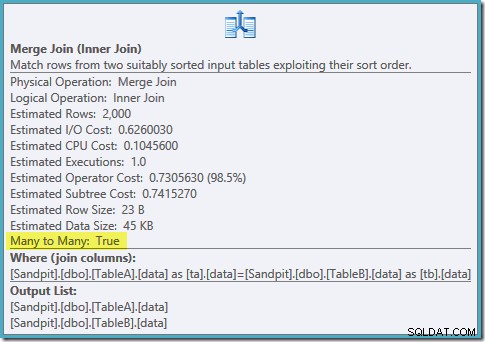
VÄLJ ta.data, tb.dataFRÅN dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data OCH ta.data ÄR INTE NULL OCH tb.data ÄR INTE NULLOPTION (SAMMANSLUTNING JOIN);Planformen är som vi hoppats:
En beställd genomsökning av båda filtrerade indexen, fantastiska kardinalitetsuppskattningar, fantastiskt. Bara ett litet problem:den här genomförandeplanen är mycket värre; den beräknade kostnaden har hoppat från 0,0772056 till 0,741527 . Orsaken till hoppningen i uppskattad kostnad avslöjas genom att kontrollera egenskaperna för sammanslagningsoperatorn:
Detta är en dyr många-till-många-join, där exekveringsmotorn måste hålla reda på dubbletter från den yttre ingången i en arbetstabell och spola tillbaka vid behov. Dubletter? Vi skannar ett unikt index! Det visar sig att optimeraren inte vet att ett filtrerat unikt index producerar unika värden (anslut objekt här). I själva verket är detta en en-till-en-koppling, men optimeraren kostar det som om det vore många-till-många, vilket förklarar varför den föredrar hash-anslutningsplanen.
En alternativ strategi
Det verkar som om vi fortsätter att stöta på optimeringsbegränsningar när vi använder filtrerade index här (trots att det är ett markerat användningsfall i Books Online). Vad händer om vi försöker använda vyer istället?
Använda vyer
Följande två vyer filtrerar bara bastabellerna för att visa raderna där datakolumnen är
NOT NULL:SKAPA VY dbo.VAWITH SCHEMABINDING ASSELECT pk, data, paddingFROM dbo.TableAWHERE data IS NOT NULL;GOCREATE VIEW dbo.VBWITH SCHEMABINDING ASSELECT pk, data, paddingFROM dbo.TableBWHERE data IS NOT NULL;Att skriva om den ursprungliga frågan för att använda vyerna är trivialt:
SELECT v.data, v2.dataFROM dbo.VA AS vJOIN dbo.VB AS v2 ON v.data =v2.data;Kom ihåg att denna fråga ursprungligen producerade en plan för parallella kapslade loopar till en kostnad på 7,7768 enheter. Med vyreferenserna får vi denna utförandeplan:
Detta är exakt samma hash-anslutningsplan som vi var tvungna att lägga till redundant
NOT NULLpredikat att få med de filtrerade indexen (kostnaden är 0,0772056 enheter som tidigare). Detta förväntas, eftersom allt vi i huvudsak har gjort här är att trycka på den extraNOT NULLpredikat från frågan till en vy.Indexera vyerna
Vi kan också prova att materialisera vyerna genom att skapa ett unikt klustrat index i pk-kolumnen:
SKAPA UNIKT CLUSTERED INDEX cuq PÅ dbo.VA (pk);SKAPA UNIKT CLUSTERED INDEX cuq PÅ dbo.VB (pk);Nu kan vi lägga till unika icke-klustrade index på den filtrerade datakolumnen i den indexerade vyn:
SKAPA UNIKT INKLUSTERAT INDEX ix PÅ dbo.VA (data); SKAPA UNIKT ICLUSTERAT INDEX ix PÅ dbo.VB (data);Observera att filtreringen utförs i vyn, dessa icke-klustrade index filtreras inte själva.
Den perfekta planen
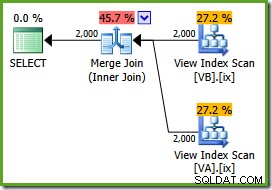
Vi är nu redo att köra vår fråga mot vyn med hjälp av
NOEXPANDtabelltips:SELECT v.data, v2.dataFROM dbo.VA AS v WITH (NOEXPAND)JOIN dbo.VB AS v2 WITH (NOEXPAND) ON v.data =v2.data;Utförandeplanen är:
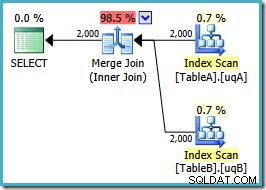
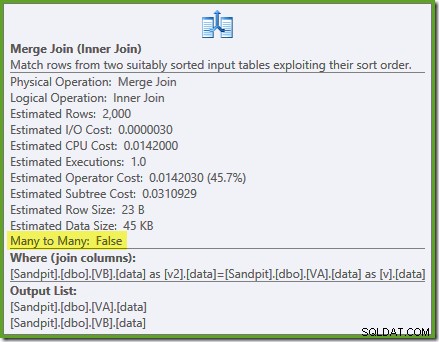
Optimeraren kan se de ofiltrerade icke-klustrade vyindex är unika, så en sammanslagning av många till många behövs inte. Denna slutliga genomförandeplan har en uppskattad kostnad på 0,0310929 enheter – till och med lägre än hash-anslutningsplanen (0,0772056 enheter). Detta bekräftar vår förväntning om att en sammanslagning borde ha den lägsta uppskattade kostnaden för denna fråga och exempeldatauppsättning.
NOEXPANDtips behövs även i Enterprise Edition för att säkerställa att unikhetsgarantin från visningsindexen används av optimeraren.Sammanfattning
Det här inlägget belyser två viktiga optimeringsbegränsningar med filtrerade index:
- Redundanta kopplingspredikat kan vara nödvändiga för att matcha filtrerade index
- Filtrerade unika index ger inte unikhetsinformation till optimeraren
I vissa fall kan det vara praktiskt att helt enkelt lägga till de redundanta predikaten till varje fråga. Alternativet är att kapsla in de önskade underförstådda predikaten i en oindexerad vy. Hash-matchningsplanen i det här inlägget var mycket bättre än standardplanen, även om optimeraren borde kunna hitta den något bättre sammanslagningsplanen. Ibland kan du behöva indexera vyn och använda NOEXPAND tips (krävs ändå för Standard Edition-instanser). Under ytterligare andra omständigheter kommer ingen av dessa metoder att vara lämplig. Ursäkta det :)