[ Del 1 | Del 2 | Del 3 ]
Nyligen bad någon på jobbet om mer utrymme för att få plats med ett snabbt växande bord. Vid den tiden hade den 3,75 miljarder rader, presenterade på 143 miljoner sidor och upptog ~1,14TB. Naturligtvis kan vi alltid kasta mer disk vid ett bord, men jag ville se om vi kunde skala detta mer effektivt än den nuvarande linjära trenden. Låter som ett bra jobb för komprimering, eller hur? Men jag ville också testa några andra lösningar, inklusive columnstore – som folk är förvånansvärt ovilliga att prova. Jag är ingen Niko, men jag ville göra ett försök att se vad det kan göra för oss här.
Observera att jag inte fokuserar på att rapportera arbetsbelastning eller annan prestanda för läsfrågor just nu – jag vill bara se vilken inverkan jag kan ha på lagringsutrymmet (och minnes) av denna data.
Här är originaltabellen. Jag har ändrat tabell- och kolumnnamn för att skydda oskyldiga, men allt annat är relativt korrekt.
CREATE TABLE dbo.tblOriginal
(
OID bigint IDENTITY(1,1) NOT NULL PRIMARY KEY, -- there are gaps!
IN1 int NOT NULL,
IN2 int NOT NULL,
VC1 varchar(3) NULL,
BI1 bigint NULL,
IN3 int NULL,
VC2 varchar(128) NOT NULL,
VC3 varchar(128) NOT NULL,
VC4 varchar(128) NULL,
NM1 numeric(24,12) NULL,
NM2 numeric(24,12) NULL,
NM3 numeric(24,12) NULL,
BI2 bigint NULL,
IN4 int NULL,
BI3 bigint NULL,
NM4 numeric(24,12) NULL,
IN5 int NULL,
NM5 numeric(24,12) NULL,
DT1 date NULL,
VC5 varchar(128) NULL,
BI4 bigint NULL,
BI5 bigint NULL,
BI6 bigint NULL,
BT1 bit NOT NULL,
NV1 nvarchar(512) NULL,
VB1 AS (HASHBYTES('MD5',VC2+VC3)),
IN6 int NULL,
IN7 int NULL,
IN8 int NULL
);
Det finns några andra småsaker där inne som är bredare än de borde vara och/eller som radkomprimering kan rensa upp, som de numeric(24,12) och bigint kolumner som kan vara överdimensionerade i förtid, men jag tänker inte gå tillbaka till applikationsteamet och ta reda på om det finns små effektivitetsvinster där, och jag kommer att hoppa över radkomprimering för den här övningen och fokusera på komprimering av sida och kolumnbutik.
Detta är en kopia av data, på en ledig server (8 kärnor, 64 GB RAM), med gott om diskutrymme (väl över 6 TB). Så först, låt oss lägga till ett par filgrupper, en för standard klustrad kolumnlagring och en för en partitionerad version av tabellen (där alla utom den senaste partitionen kommer att komprimeras med COLUMNSTORE_ARCHIVE , eftersom all den äldre data nu är "skrivskyddad och sällan"):
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_PARTITIONED;
Och så några filer för dessa filgrupper (en fil per kärna, snygg och enhetlig storlek på 256 GB):
ALTER DATABASE OCopy ADD FILE (name = N'CCI_1', size = 250000, filename = 'K:\Data\o_cci_1.mdf') TO FILEGROUP FG_CCI; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_8', size = 250000, filename = 'K:\Data\o_cci_8.mdf') TO FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_1', size = 250000, filename = 'K:\Data\o_p_1.mdf') TO FILEGROUP FG_CCI_PARTITIONED; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_8', size = 250000, filename = 'K:\Data\o_p_8.mdf') TO FILEGROUP FG_CCI_PARTITIONED;
På just denna hårdvara (YMMV!) tog detta cirka 10 sekunder per fil och gav följande:
För att generera partitionerna delade jag naivt upp data "jämnt" - eller så trodde jag. Jag tog bara de 3,75 miljarder raderna och partitionerade i något som jag trodde skulle vara hanterbart:38 partitioner med 100 miljoner rader i de första 37 partitionerna, och resten i den sista. (Kom ihåg att detta bara är del 1! Det finns ett inneboende antagande här om jämn fördelning av värden i källtabellen, och även kring vad som är optimalt för radgruppspopulationen i destinationstabellen.) Att skapa partitionsschemat och funktionen för detta är som följer:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES (100000000, 200000000, /* ... 33 more ... */ , 3600000000, 3700000000); CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID ALL TO (FG_CCI_PARTITIONED);
Jag använder RANGE LEFT eftersom, som Cathrine Wilhelmsen fortsätter att påminna mig om, betyder detta att gränsvärdet är en del av skiljeväggen till vänster om den. Med andra ord, värdena jag anger är maxvärdena i varje partition (med datum vill du vanligtvis ha RANGE RIGHT ).
Jag skapade sedan två kopior av tabellen, en på varje filgrupp. Den första hade ett standardiserat kolumnlagerindex, de enda skillnaderna var OID kolumnen är inte en IDENTITY och den beräknade kolumnen är bara en varbinary(8000) :
CREATE TABLE dbo.tblCCI ( OID bigint NOT NULL, -- ... other columns ... ) ON FG_CCI; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_IX ON dbo.tblCCI;
Den andra byggdes på partitionsschemat, så det behövdes en namngiven PK först, som sedan måste ersättas av ett klustrade kolumnbutiksindex (även om Brent Ozar visar i det här korta inlägget att det finns en ointuitiv syntax som kommer att åstadkomma detta i färre steg ):
CREATE TABLE dbo.tblCCI_Partitioned ( OID bigint NOT NULL, -- ... other columns ..., CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID (OID) ); GO ALTER TABLE dbo.tblCCI_Partitioned DROP CONSTRAINT PK_CCI_Part; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblCCI_Partitioned ON PS_OID (OID);
Sedan, för att sätta arkivkomprimering på alla utom den sista partitionen, körde jag följande:
ALTER TABLE dbo.tblCCI_Part
REBUILD PARTITION = ALL WITH
(
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (38),
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 37)
); Nu var jag redo att fylla i dessa tabeller med data, mäta tiden och den resulterande storleken och jämföra. Jag modifierade ett användbart batch-skript från Andy Mallon och infogade raderna i båda tabellerna sekventiellt, med en batchstorlek på 10 miljoner rader. Det finns mycket mer än detta i det verkliga skriptet (inklusive uppdatering av en kötabell med framsteg), men i princip:
DECLARE @BatchSize int = 10000000, @MaxID bigint, @LastID bigint = 0;
SELECT @MaxID = MAX(OID) FROM dbo.tblOriginal;
WHILE @LastID < @MaxID
BEGIN
INSERT dbo.tblCCI
(
-- all columns except the computed column
)
SELECT -- all columns except the computed column
FROM dbo.tblOriginal AS o
WHERE o.CostID >= @LastID
AND o.CostID < @LastID + @BatchSize;
SET @LastID += @BatchSize;
END Efter att jag fyllt i båda kolumnlagringstabellerna från den ursprungliga (okomprimerade) källan, byggde jag om dessa partitioner igen för att rensa upp eventuell radgrupp och ordboksröra. Slutligen tillämpade jag sidkomprimering på plats på källtabellen. Här var tidpunkterna och kompressionsresultaten för varje typ:
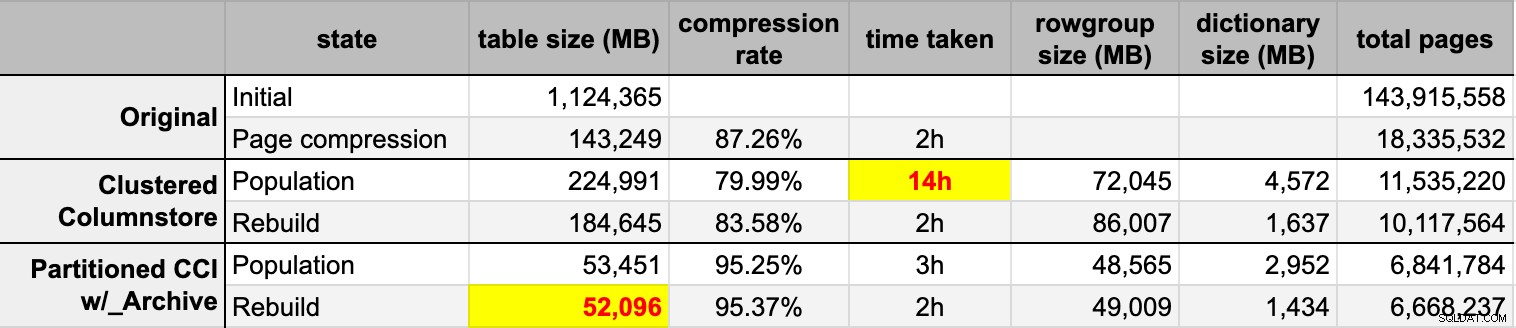
Jag är både imponerad och besviken. Imponerad eftersom denna data komprimeras riktigt bra – Att krympa lagringsutrymmet till 5 % av den ursprungliga 1 TB är ganska fantastiskt. Besviken eftersom:
- Jag gjorde dessa datafiler på sätt för stor.
- Jag förstår inte vad som hände med den 14 timmar långa inledande kolumnbutikskomprimeringen:
- Jag observerade inget minne eller loggtryck.
- Det förekom inga filtillväxthändelser.
- Tyvärr tänkte jag inte spåra väntan. Nej, jag tänker inte försöka igen. :-)
- Sidkomprimering överträffade vanlig kolumnlagringskomprimering – kanske på grund av data.
- Återuppbyggnaden av columnstore-arkivpartitionerna tog upp mycket CPU-tid för nästan noll förstärkning.
I kommande inlägg, och efter att ha granskat mina anteckningar från en fantastisk kolumnbutikspresentation av Joe Obbish på PASS Summit (som jag skulle länka till direkt, om bara PASS visste hur man använder UI), ska jag prata lite om de förändringar jag ska göra gör till serverkonfigurationen och mitt populationsskript för att se om jag kan få bättre prestanda från columnstore-populationen.
[ Del 1 | Del 2 | Del 3 ]