Detta är den tredje i en serie i fem delar som tar en djupdykning i hur parallella planer för SQL Server-radläge börjar köras. Del 1 initierade exekveringskontext noll för den överordnade uppgiften, och del 2 skapade frågesökningsträdet. Vi är nu redo att starta sökfrågan, utföra någon tidig fas bearbetning och starta de första ytterligare parallella uppgifterna.
Frågesökningsstart
Kom ihåg att endast föräldrauppgiften existerar just nu, och börserna (parallellismoperatörer) har bara en konsumentsida. Ändå räcker detta för att exekveringen av frågan ska börja, på den överordnade uppgiftens arbetstråd. Frågeprocessorn börjar köra genom att starta söksökningsprocessen via ett anrop till CQueryScan::StartupQuery . En påminnelse om planen (klicka för att förstora):
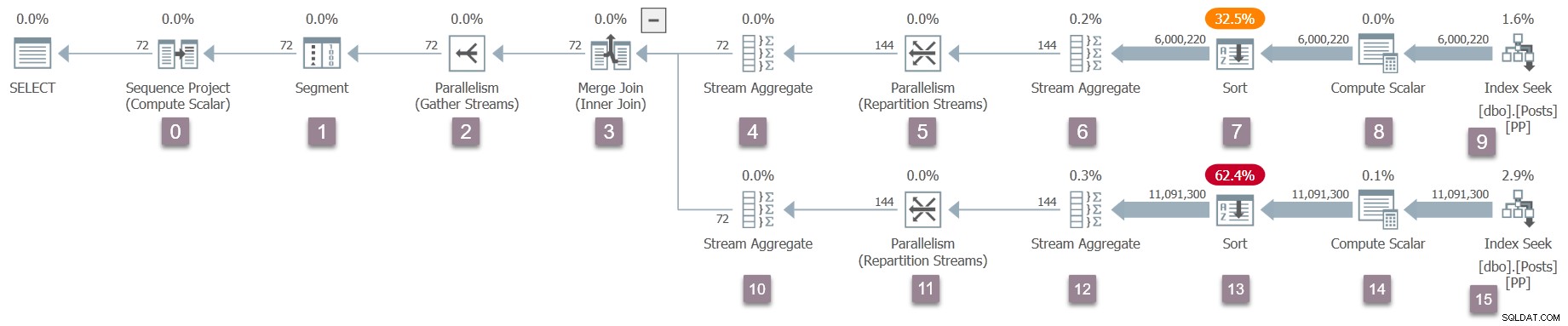
Detta är den första punkten i processen hittills som en utförandeplan under flygning är tillgänglig (SQL Server 2016 SP1 och framåt) i sys.dm_exec_query_statistics_xml . Det finns inget särskilt intressant att se i en sådan plan just nu, eftersom alla transienträknare är noll, men planen är åtminstone tillgänglig . Det finns ingen antydan om att parallella uppgifter inte har skapats ännu, eller att börserna saknar en producentsida. Planen ser "normal" ut i alla avseenden.
Parallell plangrenar
Eftersom detta är en parallell plan, kommer det att vara användbart att visa den uppdelad i grenar. Dessa är skuggade nedan och märkta som grenar A till D:
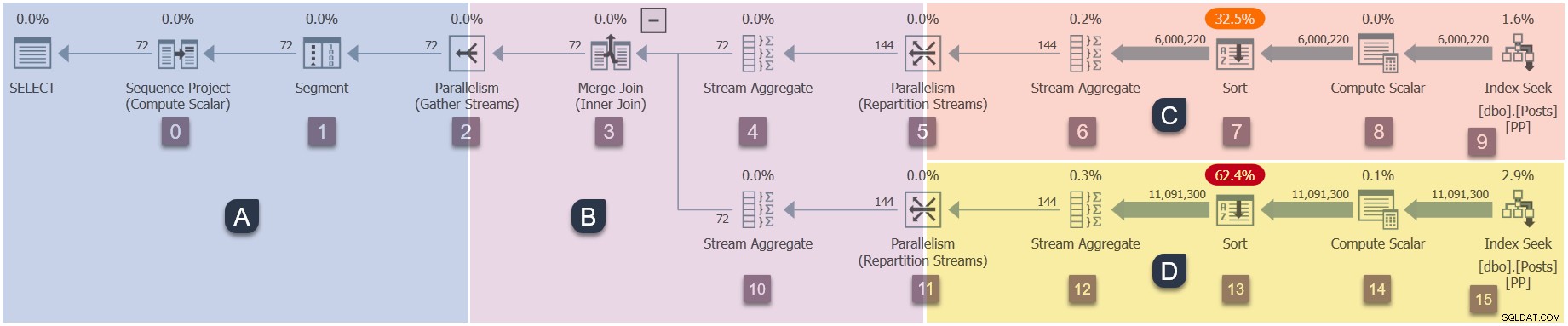
Gren A är associerad med den överordnade uppgiften, som körs på arbetstråden som tillhandahålls av sessionen. Ytterligare parallella arbetare kommer att startas för att köra de ytterligare parallella uppgifterna finns i grenarna B, C och D. Dessa grenar är parallella, så det kommer att finnas ytterligare DOP-uppgifter och arbetare i var och en.
Vår exempelfråga körs vid DOP 2, så gren B kommer att få ytterligare två uppgifter. Detsamma gäller för gren C och gren D, vilket ger totalt sex ytterligare uppgifter. Varje uppgift kommer att köras på sin egen arbetstråd i sin egen körningskontext.
Två schemaläggare (S1 och S2 ) tilldelas den här frågan för att köra ytterligare parallella arbetare. Varje ytterligare arbetare kommer att köras på en av dessa två schemaläggare. Den överordnade arbetaren kan köras på en annan schemaläggare, så vår DOP 2-fråga kan använda maximalt tre processorkärnor när som helst.
För att sammanfatta kommer vår plan så småningom att ha:
- Gren A (förälder)
- Föräldrauppgift.
- Tråd för föräldrar.
- Körningskontext noll.
- Alla enskilda schemaläggare som är tillgängliga för frågan.
- Gren B (ytterligare)
- Två ytterligare uppgifter.
- En extra arbetstråd bunden till varje ny uppgift.
- Två nya körningskontexter, en för varje ny uppgift.
- En arbetstråd körs på schemaläggaren S1 . Den andra körs på schemaläggaren S2 .
- Gren C (ytterligare)
- Två ytterligare uppgifter.
- En extra arbetstråd bunden till varje ny uppgift.
- Två nya körningskontexter, en för varje ny uppgift.
- En arbetstråd körs på schemaläggaren S1 . Den andra körs på schemaläggaren S2 .
- Gren D (ytterligare)
- Två ytterligare uppgifter.
- En extra arbetstråd bunden till varje ny uppgift.
- Två nya körningskontexter, en för varje ny uppgift.
- En arbetstråd körs på schemaläggaren S1 . Den andra körs på schemaläggaren S2 .
Frågan är hur alla dessa extra uppgifter, arbetare och exekveringskontexter skapas och när de börjar köras.
Startsekvens
Den sekvens i vilken ytterligare uppgifter börja köra för just den här planen är:
- Gren A (föräldrauppgift).
- Gren C (ytterligare parallella uppgifter).
- Gren D (ytterligare parallella uppgifter).
- Gren B (ytterligare parallella uppgifter).
Det kanske inte är den startorder du förväntade dig.
Det kan finnas en betydande försening mellan vart och ett av dessa steg, av skäl som vi kommer att utforska inom kort. Nyckelpunkten i detta skede är att de ytterligare uppgifterna, arbetarna och exekveringskontexterna inte är alla skapas på en gång, och det gör de inte alla börjar köras samtidigt.
SQL Server kunde ha utformats för att starta alla extra parallella bitar på en gång. Det kan vara lätt att förstå, men det skulle inte vara särskilt effektivt i allmänhet. Det skulle maximera antalet ytterligare trådar och andra resurser som används av frågan, och resultera i en hel del onödiga parallella väntan.
Med designen som används av SQL Server kommer parallella planer ofta att använda färre totala arbetstrådar än (DOP multiplicerat med det totala antalet grenar). Detta uppnås genom att inse att vissa grenar kan köras till slut innan någon annan gren behöver starta. Detta kan tillåta återanvändning av trådar inom samma fråga, och generellt minskar resursförbrukningen totalt sett.
Låt oss nu gå över till detaljerna om hur vår parallella plan startar.
Öppningsgren A
Frågesökningen börjar köras med den överordnade uppgiften som anropar Open() på iteratorn vid trädets rot. Detta är början på exekveringssekvensen:
- Gren A (överordnad uppgift).
- Gren C (ytterligare parallella uppgifter).
- Gren D (ytterligare parallella uppgifter).
- Gren B (ytterligare parallella uppgifter).
Vi kör den här frågan med en "faktisk" plan efterfrågad, så rot-iteratorn är inte sekvensprojektoperatorn vid nod 0. Det är snarare den osynliga profileringsiteratorn som registrerar körtidsstatistik i radlägesplaner.
Illustrationen nedan visar frågesökningsiteratorerna i gren A av planen, med positionen för osynliga profileringsiteratorer representerade av "glasögon"-ikonerna.
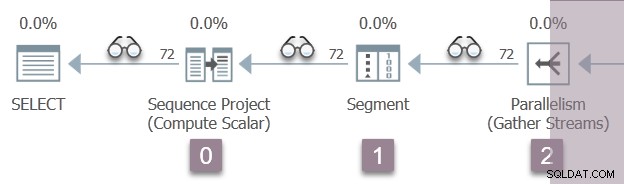
Körningen börjar med ett anrop för att öppna den första profileraren, CQScanProfileNew::Open . Detta ställer in öppningstiden för den underordnade sekvensprojektoperatören via operativsystemets Query Performance Counter API.
Vi kan se detta nummer i sys.dm_exec_query_profiles :
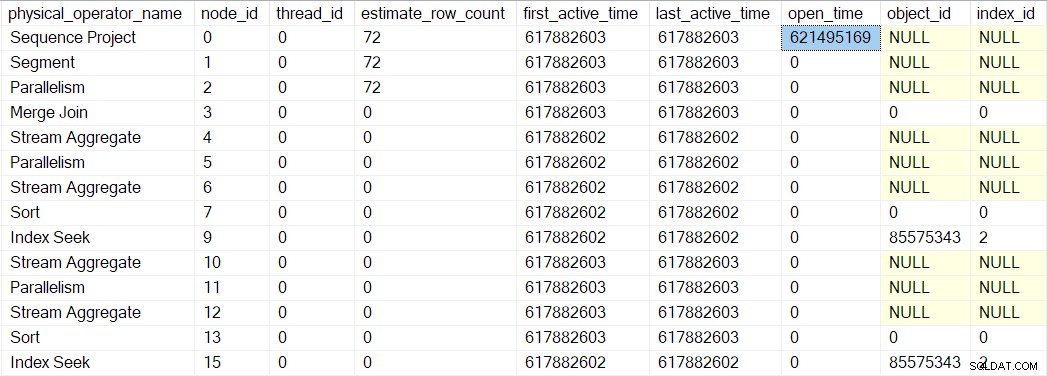
Posterna där kan ha operatörsnamnen listade, men data kommer från profileraren ovanför operatören, inte operatören själv.
Som det händer, ett sekvensprojekt (CQScanSeqProjectNew ) behöver inte göra något arbete när den öppnas , så den har faktiskt inte en Open() metod. Profileraren ovanför sekvensprojektet är anropas, så en öppen tid för sekvensprojektet registreras i DMV.
Profilarens Open metoden anropar inte Open på sekvensprojektet (eftersom det inte har någon). Istället kallar den Open på profileraren för nästa iterator i följd. Det här är segmentet iterator vid nod 1. Det ställer in öppettiden för segmentet, precis som den tidigare profileraren gjorde för sekvensprojektet:
En segmentiterator gör har saker att göra när den öppnas, så nästa samtal är att CQScanSegmentNew::Open . När segmentet har gjort vad det behöver, anropar det profileraren för nästa iterator i sekvens - konsumenten sidan av samla strömmar utbyte vid nod 2:
Nästa anrop i frågesökningsträdet i öppningsprocessen är CQScanExchangeNew::Open , vilket är där saker och ting börjar bli mer intressanta.
Öppna samlingsströmbörsen
Be konsumentsidan av börsen att öppna:
- Öppnar en lokal (parallellt kapslad) transaktion (
CXTransLocal::Open). Varje process behöver en innehållande transaktion, och ytterligare parallella uppgifter är inget undantag. De kan inte dela den överordnade (bas) transaktionen direkt, så kapslade transaktioner används. När en parallell uppgift behöver komma åt bastransaktionen synkroniseras den på en spärr och kan stöta påNESTING_TRANSACTION_READONLYellerNESTING_TRANSACTION_FULLväntar. - Registrerar den aktuella arbetstråden med utbytesporten (
CXPort::Register). - Synkroniserar med andra trådar på konsumentsidan av börsen (
sqlmin!CXTransLocal::Synchronize). Det finns inga andra trådar på konsumentsidan av samlingsströmmar, så det här är i princip en no-op vid det här tillfället.
Bearbetning av "tidiga faser"
Den överordnade uppgiften har nu nått kanten av gren A. Nästa steg är särskilt till parallella planer för radläge:Den överordnade uppgiften fortsätter att köras genom att anropa CQScanExchangeNew::EarlyPhases på samla strömmar utbytes iterator vid nod 2. Detta är en ytterligare iteratormetod utöver den vanliga Open , GetRow och Close metoder som många av er kommer att känna till. EarlyPhases anropas endast i radläges parallella planer.
Jag vill vara tydlig med något vid det här laget:Producentsidan av utbytet för samla strömmar vid nod 2 har inte har skapats ännu, och nej ytterligare parallella uppgifter har skapats. Vi kör fortfarande kod för den överordnade uppgiften och använder den enda tråden som körs just nu.
Inte alla iteratorer implementerar EarlyPhases , eftersom inte alla av dem har något speciellt att göra vid denna tidpunkt i radläges parallella planer. Detta är analogt med att sekvensprojektet inte implementerar Open metoden eftersom den inte har något att göra vid den tiden. De viktigaste iteratorerna med EarlyPhases metoder är:
CQScanConcatNew(sammansättning).CQScanMergeJoinNew(sammanfoga gå med).CQScanSwitchNew(växla).CQScanExchangeNew(parallellism).CQScanNew(raduppsättningsåtkomst, t.ex. genomsökningar och sökningar).CQScanProfileNew(osynliga profilerare).CQScanLightProfileNew(osynliga lätta profiler).
Branch B tidiga faser
föräldrauppgiften fortsätter genom att anropa EarlyPhases på underordnade operatörer bortom utbytet för samla strömmar vid nod 2. En uppgift som rör sig över en grengräns kan tyckas ovanlig, men kom ihåg att exekveringskontext noll innehåller hela serieplanen, med utbyten inkluderade. Tidig fasbehandling handlar om att initiera parallellism, så det räknas inte som exekvering i sig .
För att hjälpa dig hålla reda på, visar bilden nedan iteratorerna i gren B av planen:
Kom ihåg att vi fortfarande är i exekveringskontext noll, så jag hänvisar bara till detta som gren B för bekvämlighets skull. Vi har inte börjat någon parallell körning ännu.
Sekvensen av tidig faskodsanrop i gren B är:
CQScanProfileNew::EarlyPhasesför profileraren ovanför nod 3.CQScanMergeJoinNew::EarlyPhasesvid nod 3 merge join .CQScanProfileNew::EarlyPhasesför profileraren ovanför nod 4. strömaggregatet för nod 4 i sig har ingen tidiga fasmetod.CQScanProfileNew::EarlyPhasespå profileraren ovanför nod 5.CQScanExchangeNew::EarlyPhasesför ompartitionsströmmarna utbyte vid nod 5.
Observera att vi endast bearbetar den yttre (övre) ingången till sammanfogningen i detta skede. Detta är bara den normala iterativa sekvensen för exekvering av radläge. Det är inte speciellt för parallella planer.
Branch C tidiga faser
Tidig fasbehandling fortsätter med iteratorerna i gren C:

Sekvensen av samtal här är:
CQScanProfileNew::EarlyPhasesför profileraren ovanför nod 6.CQScanProfileNew::EarlyPhasesför profileraren ovanför nod 7.CQScanProfileNew::EarlyPhasespå profileraren ovanför nod 9.CQScanNew::EarlyPhasesför indexsökningen vid nod 9.
Det finns inga EarlyPhases metod på strömmen aggregerar eller sorterar. Arbetet som utförs av compute scalar vid nod 8 är uppskjutet (till sorteringen), så den visas inte i frågesökningsträdet och har ingen associerad profilerare.
Om profileringstider
Överordnad uppgift tidig fasbearbetning började vid samlingsströmutbytet vid nod 2. Det gick ner i frågesökningsträdet, efter den yttre (övre) ingången till sammanfogningen, hela vägen ner till indexsökningen vid nod 9. Längs vägen har den överordnade uppgiften anropat EarlyPhases metod på varje iterator som stöder det.
Ingen av aktiviteten i de tidiga faserna har hittills uppdaterats när som helst i profilerings-DMV. Specifikt har ingen av iteratorerna som berörs av bearbetning i tidiga faser haft sin "öppna tid" inställd. Detta är vettigt, eftersom bearbetning i tidig fas bara ställer in parallell exekvering – dessa operatörer kommer att öppnas för exekvering senare.
Indexsökningen vid nod 9 är en lövnod – den har inga barn. Den överordnade uppgiften börjar nu återvända från den kapslade EarlyPhases samtal, stigande sökfrågan skannar trädet tillbaka mot samla strömmar utbyte.
Var och en av profilerna anropar Query Performance Counter API vid inträde till deras EarlyPhases metoden, och de kallar den igen på vägen ut. Skillnaden mellan de två siffrorna representerar förfluten tid för iteratorn och alla dess barn (eftersom metodanropen är kapslade).
Efter att profileraren för indexsökningen återvänder, visar profilerarens DMV förfluten tid och CPU-tid för indexsökningen endast, samt en uppdaterad senast aktiva tid. Observera också att denna information registreras mot förälderuppgiften (det enda alternativet just nu):
Ingen av de tidigare iteratorerna som berörs av anropen i de tidiga faserna har förflutna tider eller uppdaterade senaste aktiva tider. Dessa siffror uppdateras bara när vi går upp i trädet.
Efter nästa profilerares tidiga faser anropsretur, sorteringen tiderna är uppdaterade:
Nästa retur tar oss upp förbi profileraren för strömningsaggregatet vid nod 6:
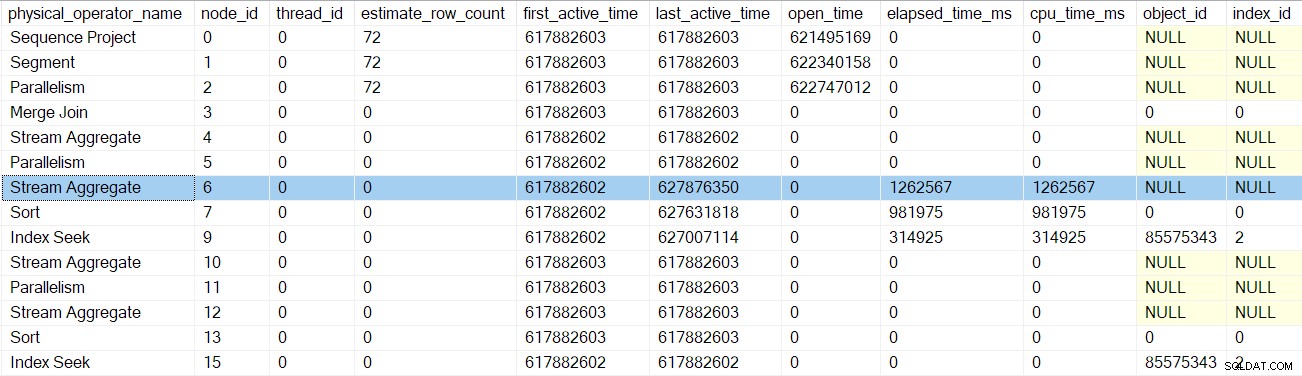
Att återvända från denna profiler tar oss tillbaka till EarlyPhases anropa ompartitionsströmmarna utbyte vid nod 5 . Kom ihåg att det inte var här sekvensen av anrop i tidiga faser började – det var utbytet för samla strömmar vid nod 2.
Branch C parallella uppgifter i kö
Bortsett från att uppdatera profileringsdata, verkade samtalen i de tidigare tidiga faserna inte göra särskilt mycket. Allt förändras med ompartitionsströmmarna utbyte vid nod 5.
Jag kommer att beskriva Branch C ganska detaljerat för att introducera ett antal viktiga begrepp, som kommer att gälla även för de andra parallella grenarna. Att täcka detta en gång nu innebär att senare grendiskussioner kan bli mer kortfattade.
Efter att ha slutfört kapslad tidig fasbearbetning för sitt underträd (ned till indexsökningen vid nod 9), kan utbytet påbörja sitt eget tidiga fasarbete. Detta börjar på samma sätt som att öppna samla strömmar utbyter vid nod 2:
CXTransLocal::Open(öppnar den lokala parallella deltransaktionen).CXPort::Register(registrerar med utbytesporten).
Nästa steg är annorlunda eftersom gren C innehåller en fullständig blockering iterator (sorten vid nod 7). Den tidiga fasbehandlingen vid nod 5 ompartitionsströmmarna gör följande:
- Anropar
CQScanExchangeNew::StartAllProducers. Det här är första gången vi har stött på något som hänvisar till producentsidan av utbytet. Node 5 är den första börsen i denna plan som skapar sin producentsida. - Erhåller ett mutex så ingen annan tråd kan köa uppgifter samtidigt.
- Startar parallella kapslade transaktioner för producentuppgifterna (
CXPort::StartNestedTransactionsochReadOnlyXactImp::BeginParallelNestedXact). - Registrerar deltransaktionerna med det överordnade frågeskanningsobjektet (
CQueryScan::AddSubXact). - Skapar producentbeskrivningar (
CQScanExchangeNew::PxproddescCreate). - Skapar nya producerande körningskontexter (
CExecContext) härledd från exekveringskontext noll. - Uppdaterar den länkade kartan över planiteratorer.
- Ställer in DOP för den nya kontexten (
CQueryExecContext::SetDop) så att alla uppgifter vet vad den övergripande DOP-inställningen är. - Initierar parametercachen (
CQueryExecContext::InitParamCache). - Länkar de parallellt kapslade transaktionerna till bastransaktionen (
CExecContext::SetBaseXact). - Köar de nya underprocesserna för exekvering (
SubprocessMgr::EnqueueMultipleSubprocesses). - Skapar nya parallella uppgifter uppgifter via
sqldk!SOS_Node::EnqueueMultipleTasksDirect.
Föräldrauppgiftens anropsstack (för er som gillar dessa saker) runt denna tidpunkt är:
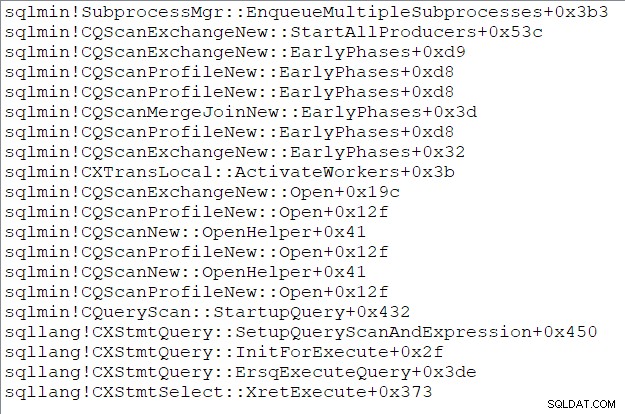
Slutet av del tre
Vi har nu skapat producentsidan av ompartitionsströmmarna utbyter vid nod 5, skapade ytterligare parallella uppgifter för att köra Branch C, och länkade tillbaka allt till förälder strukturer efter behov. Gren C är den första gren för att starta eventuella parallella uppgifter. Den sista delen av den här serien kommer att titta på gren C-öppningen i detalj och påbörja de återstående parallella uppgifterna.