För alla nya databaser som skapats i SQL Server är standardvärdet för alternativet Automatisk uppdatering av statistik aktiverat . Jag misstänker att de flesta DBA:er lämnar alternativet aktiverat, eftersom det tillåter optimeraren att automatiskt uppdatera statistik när de är ogiltiga, och det rekommenderas i allmänhet att låta det vara aktiverat. Statistiken uppdateras också när index byggs om, och även om det inte är ovanligt att statistik hanteras väl via alternativet för automatisk uppdatering av statistik och genom indexombyggnader, kan en DBA då och då finna det nödvändigt att ställa in ett vanligt jobb för att uppdatera en statistik, eller uppsättning statistik.
Anpassad hantering av statistik involverar ofta kommandot UPDATE STATISTICS, vilket verkar ganska godartat. Den kan köras för all statistik för en tabell eller indexerad vy, eller för en specifik statistik. Standardsamplet kan användas, en specifik samplingshastighet eller antal rader att sampla kan anges, eller så kan du använda samma samplingsvärde som användes tidigare. Om statistiken uppdateras för en tabell eller indexerad vy kan du välja att uppdatera all statistik, endast indexstatistik eller endast kolumnstatistik. Och slutligen kan du inaktivera alternativet för automatisk uppdatering av statistik för en statistik.
För de flesta DBA:er kan den största hänsynen vara när för att köra UPDATE STATISTICS-satsen. Men DBA:er bestämmer också, medvetet eller inte, urvalsstorleken för uppdateringen. Den valda provstorleken kan påverka prestandan för den faktiska uppdateringen, såväl som prestanda för frågor.
Förstå effekterna av provstorlek
Standardprovstorleken för UPDATE STATISTICS kommer från en icke-linjär algoritm, och urvalsstorleken minskar när tabellstorleken blir större, som Joe Sack visade i sitt inlägg, Auto-Update Stats Default Sampling Test. I vissa fall kanske urvalsstorleken inte är tillräckligt stor för att fånga tillräckligt med intressant information, eller rätt information, för statistikhistogrammet, som noterats av Conor Cunningham i hans inlägg om statistikprovsatser. Om standardexemplet inte skapar ett bra histogram, kan DBA:er välja att uppdatera statistik med en högre samplingsfrekvens, upp till en FULLSCAN (genomsökning av alla rader i tabellen eller indexerad vy). Men som Conor nämnde i sitt inlägg kostar det att skanna fler rader, och DBA utmanas med att bestämma sig för om man ska köra en FULLSCAN för att försöka skapa det "bästa" histogrammet som möjligt, eller ta prov på en mindre procentandel för att minimera prestandapåverkan av uppdateringen.
För att försöka förstå vid vilken tidpunkt ett prov tar längre tid än en FULLSCAN, körde jag följande uttalanden mot kopior av SalesOrderDetail-tabellen som förstorades med Jonathan Kehayias skript:
| påstående-ID | UPDATERA STATISTICS-satsen |
|---|---|
| 1 | UPPDATERA STATISTIK [Försäljning].[SalesOrderDetailEnlarged] MED FULLSCAN; |
| 2 | UPPDATERA STATISTIK [Försäljning].[SalesOrderDetailEnlarged]; |
| 3 | UPPDATERA STATISTIK [Försäljning].[SalesOrderDetailEnlarged] MED EXEMPEL 10 PROCENT; |
| 4 | UPPDATERA STATISTIK [Försäljning].[SalesOrderDetailEnlarged] MED EXEMPEL 25 PROCENT; |
| 5 | UPPDATERA STATISTIK [Försäljning].[SalesOrderDetailEnlarged] MED EXEMPEL 50 PROCENT; |
| 6 | UPPDATERA STATISTIK [Försäljning].[SalesOrderDetailEnlarged] MED EXEMPEL 75 PROCENT; |
Jag hade tre exemplar av tabellen SalesOrderDetailEnlarged, med följande egenskaper*:
| Radräkning | Sidantal | MAXDOP | Max minne | Lagring | Maskin |
|---|---|---|---|---|---|
| 23 899 449 | 363 284 | 4 | 8 GB | SSD_1 | Bärbar dator |
| 607 312 902 | 7 757 200 | 16 | 54 GB | SSD_2 | Testserver |
| 607 312 902 | 7 757 200 | 16 | 54 GB | 15K | Testserver |
*Ytterligare information om hårdvaran finns i slutet av det här inlägget.
Alla kopior av tabellen hade följande statistik, och ingen av de tre indexstatistiken hade inkluderat kolumner:
| Statistik | Typ | Kolumner i nyckel |
|---|---|---|
| PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID | Index | SalesOrderID, SalesOrderDetailID |
| AK_SalesOrderDetailEnlarged_rowguid | Index | rowguid |
| IX_SalesOrderDetailEnlarged_ProductID | Index | Produkt-ID |
| user_CarrierTrackingNumber | Kolumn | CarrierTrackingNumber |
Jag körde ovanstående UPDATE STATISTICS-satser fyra gånger vardera mot SalesOrderDetailEnlarged-tabellen på min bärbara dator och två gånger mot SalesOrderDetailEnlarged-tabellerna på TestServer. Påståenden kördes i slumpmässig ordning varje gång, och procedurcache och buffertcache rensades före varje uppdateringssats. Varaktigheten och tempdb-användningen för varje uppsättning uttalanden (genomsnitt) visas i diagrammen nedan:
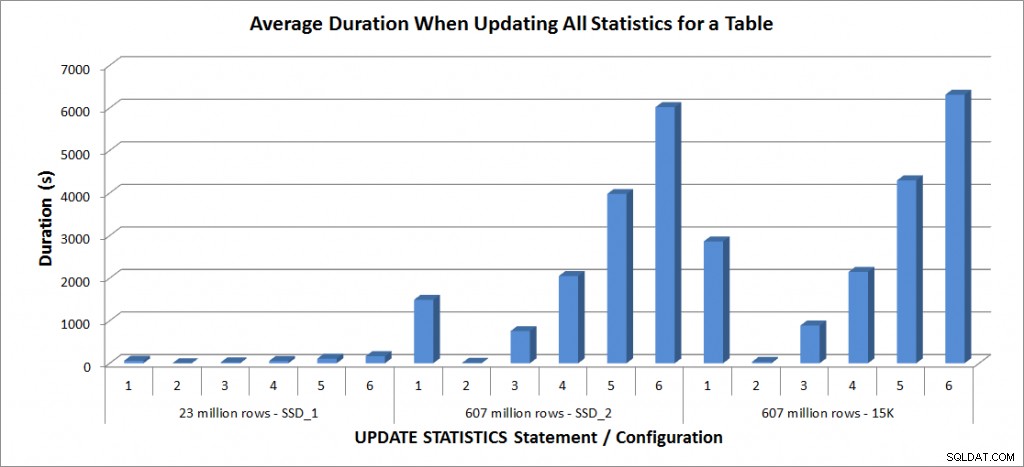
Genomsnittlig varaktighet – Uppdatera all statistik för SalesOrderDetailEnlarged
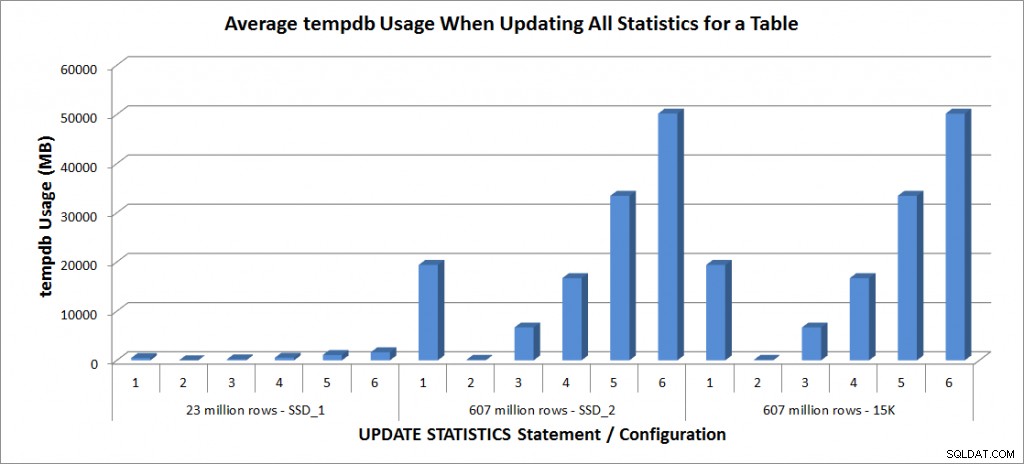
tempdb-användning – Uppdatera all statistik för SalesOrderDetailEnlarged
Varaktigheterna för tabellen med 23 miljoner rader var alla mindre än tre minuter och beskrivs mer i detalj i nästa avsnitt. För tabellen på SSD_2-diskarna tog FULLSCAN-satsen 1492 sekunder (nästan 25 minuter) och uppdateringen med 25 % prov tog 2051 sekunder (över 34 minuter). Däremot, på 15K-diskarna, tog FULLSCAN-satsen 2864 sekunder (över 47 minuter) och uppdateringen med ett 25%-exempel tog 2147 sekunder (nästan 36 minuter) – mindre än tiden för FULLSCAN. Uppdateringen med ett urval på 50 % tog dock 4296 sekunder (över 71 minuter).
Tempdb-användningen är mycket mer konsekvent, visar en stadig ökning när urvalsstorleken ökar, och använder mer tempdb-utrymme än en FULLSCAN någonstans mellan 25 % och 50 %. Vad som är anmärkningsvärt här är att UPDATE STATISTICS gör använd tempdb, vilket är viktigt att komma ihåg när du dimensionerar tempdb för en SQL Server-miljö. Tempdb-användning nämns i UPDATE STATISTICS BOL-posten:
UPDATE STATISTICS kan använda tempdb för att sortera urvalet av rader för byggnadsstatistik.”
Och effekten dokumenteras i Linchi Sheas inlägg, Performance impact:tempdb and update statistics. Det är dock inte något som alltid nämns under tempdb storleksdiskussioner. Om du har stora tabeller och utför uppdateringar med FULLSCAN eller höga sampelvärden, var medveten om tempdb-användningen.
Prestanda av selektiva uppdateringar
Jag bestämde mig sedan för att testa UPDATE STATISTICS-satserna för den andra statistiken på bordet, men begränsade mina tester till kopian av tabellen med 23 miljoner rader. Ovanstående sex varianter av UPDATE STATISTICS-satsen upprepades fyra gånger vardera för följande individuella statistik och jämfördes sedan med uppdateringen för hela tabellen:
- PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID
- IX_SalesOrderDetailEnlarged_ProductID
- user_CarrierTrackingNumber
Alla tester kördes med ovannämnda konfiguration på min bärbara dator, och resultaten finns i diagrammet nedan:
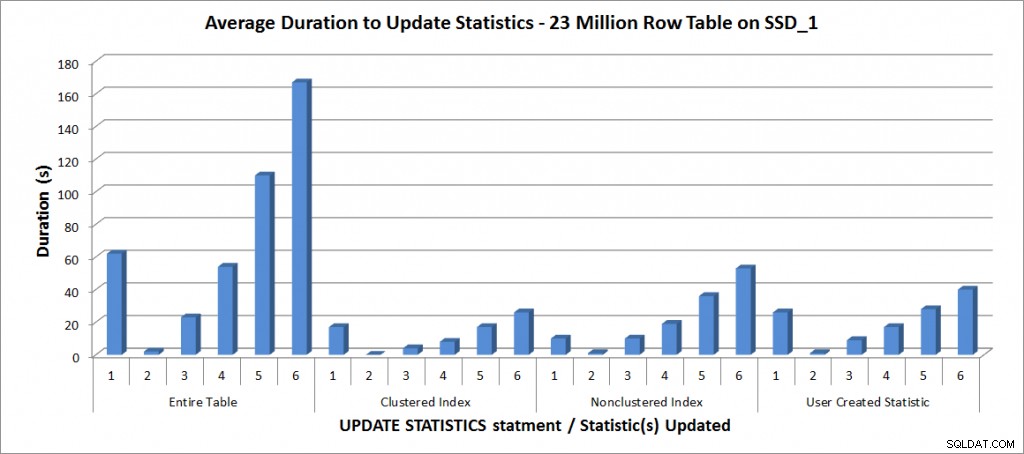
Genomsnittlig varaktighet för UPPDATERA STATISTIK – All statistik vs. valda em>
Som väntat tog uppdateringarna av en enskild statistik kortare tid än vid uppdatering av all statistik för tabellen. Värdet vid vilket den samplade uppdateringen tog längre tid än en FULLSCAN varierade:
| UPDATE-sats | FULLSCAN-längd (s) | Första UPPDATERING som tog längre tid |
|---|---|---|
| Hela tabellen | 62 | 50 % – 110 sekunder |
| Klustrat index | 17 | 75 % – 26 sekunder |
| Icke-klustrade index | 10 | 25 % – 19 sekunder |
| Användarskapad statistik | 26 | 50 % – 28 sekunder |
Slutsats
Baserat på dessa data och FULLSCAN-data från de 607 miljoner radtabellerna finns det ingen specifik vändpunkt där en samplade uppdatering tar längre tid än en FULLSCAN; den punkten beror på tabellens storlek och tillgängliga resurser. Men uppgifterna är fortfarande värdefulla eftersom de visar att det finns en punkt där ett samplat värde kan ta längre tid att fånga än en FULLSCAN. Det handlar återigen om att känna till dina data. Detta är avgörande för att inte bara förstå om en tabell behöver anpassad hantering av statistik, utan också för att förstå den idealiska urvalsstorleken för att skapa ett användbart histogram och även optimera resursanvändningen.
Specifikationer
Laptopspecifikationer:Dell M6500, 1 Intel i7 (2,13GHz 4 kärnor och HT är aktiverad så 8 logiska kärnor), 32 GB minne, Windows 7, SQL Server 2012 SP1 (11.0.3128.0 x64), databasfiler lagrade på en 265 GB Samsung SSD PM810Testserverspecifikationer:Dell R720, 2 Intel E5-2670 (2,6GHz 8 kärnor och HT är aktiverad så 16 logiska kärnor per sockel), 64 GB minne, Windows 2012, SQL Server 2012 SP1 (11.0.3339.0 x64), databasfiler för en tabell finns på två 640 GB Fusion-io Duo MLC-kort, databasfiler för det andra bordet finns på nio 15K RPM-diskar i en RAID5-array