I den här artikeln kommer vi att fokusera på operationell analys i realtid och hur man tillämpar detta tillvägagångssätt på en OLTP-databas. När vi tittar på den traditionella analytiska modellen kan vi se OLTP och analytiska miljöer är separata strukturer. Först och främst måste de traditionella analytiska modellmiljöerna skapa ETL-uppgifter (Extract, Transform and Load). Eftersom vi behöver överföra transaktionsdata till datalagret. Dessa typer av arkitektur har vissa nackdelar. De är kostnad, komplexitet och datalatens. För att eliminera dessa nackdelar behöver vi ett annat tillvägagångssätt.
Operationsanalys i realtid
Microsoft tillkännagav Real-Time Operational Analytics i SQL Server 2016. Möjligheten med den här funktionen är att kombinera transaktionsdatabas och analytisk frågebelastning utan några prestandaproblem. Operationell analys i realtid ger:
- hybridstruktur
- transaktions- och analysfrågor kan köras samtidigt
- orsakar inga prestanda- och latensproblem.
- en enkel implementering.
Denna funktion kan övervinna nackdelarna med den traditionella analytiska miljön. Huvudtemat för denna funktion är att kolumnlagringsindexet upprätthåller en kopia av data utan att påverka transaktionssystemets prestanda. Detta tema låter de analytiska frågorna köras utan att påverka prestandan. Så detta minimerar prestandapåverkan. Den huvudsakliga begränsningen för den här funktionen är att vi inte kan samla in data från olika datakällor.
Icke-klustrad kolumnbutiksindex
SQL Server 2016 introducerar uppdateringsbart "Non-Clustered Column Store Index". Det icke-klustrade kolumnbutiksindexet är ett kolumnbaserat index som ger prestandafördelar för analytiska frågor. Den här funktionen låter oss skapa ett ramverk för operativ analys i realtid. Det betyder att vi kan utföra transaktioner och analytiska frågor samtidigt. Tänk på att vi behöver månatlig total försäljning. I en traditionell modell måste vi utveckla ETL-uppgifter, datamart och datalager. Men i realtidsoperationell analys kan vi göra det utan att kräva något datalager eller några ändringar i OLTP-strukturen. Vi behöver bara skapa lämpliga icke-klustrade kolumnbutiksindex.
Arkitektur för icke-klustrade kolumnlagerindex
Låt oss kort titta på arkitekturen för icke-klustrade kolumnbutiksindex och körmekanism. Det icke-klustrade kolumnlagerindexet innehåller en kopia av en del av eller alla rader och kolumner i den underliggande tabellen. Huvudtemat för icke-klustrade kolumnlagerindex är att behålla en kopia av data och använda denna kopia av data. Så den här mekanismen minimerar påverkan på transaktionsdatabasprestanda. Det icke-klustrade kolumnlagerindexet kan skapa en eller flera kolumner och kan tillämpa ett filter på kolumner.
När vi infogar en ny rad i en tabell som har ett icke-klustrat kolumnlagerindex, skapar SQL Server för det första en "radgrupp". Radgrupp är en logisk struktur som representerar en uppsättning rader. Sedan lagrar SQL Server dessa rader i en tillfällig lagring. Namnet på denna tillfälliga lagring är "deltastore". SQL Server använder detta temporära lagringsområde eftersom denna mekanism förbättrar kompressionsförhållandet och minskar indexfragmenteringen. När antalet rader når 1 048 577 stänger SQL Server tillståndet för radgruppen. SQL Server komprimerar den här radgruppen och ändrar tillståndet till "komprimerat".
Nu kommer vi att skapa en tabell och lägga till det icke-klustrade kolumnlagerindexet.
SLIPPA TABELL OM FINNS Analysis_TableTestCREATE TABLE Analysis_TableTest(ID INT PRIMARY KEY IDENTITY(1,1),Continent_Name VARCHAR(20),Country_Name VARCHAR(20),City_Name VARCHAR(20),Sales_Amnt_GOINT,Prefit>SKAPA ICKE CLUSTERED COLUMNSTORE INDEX [NonClusteredColumnStoreIndex] PÅ [dbo].[Analysis_TableTest]( [Country_Name], [City_Name] , Sales_Amnt) MED (DROP_EXISTING =OFF, COMPRESSION]_DELON [FÖRDRÖJNING]I det här steget kommer vi att infoga flera rader och titta på egenskaperna för det icke-klustrade kolumnlagerindexet.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200',' 24')INSERT INTO Analysis_TableTest VALUES('Europe','Frankrike','Paris','190','23')INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180',' 19')INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')GODen här frågan visar tillstånden för radgruppen, det totala antalet radstorlekar och andra värden.
SELECT i.object_id, object_name(i.object_id) AS TableName, i.name AS IndexName, i.index_id, i.type_desc, CSRowGroups.*, 100*(total_rows - ISNULL(deleted_rows,0))/total_rows AS PercentFull FRÅN sys.indexes AS i JOIN sys.column_store_row_groups AS CSRowGroups ON i.object_id =CSRowGroups.object_id AND i.index_id =CSRowGroups.index_id BESTÄLLNING EFTER object_name(i.object_id), i.pre-group_id,
Bilden ovan visar deltastore-tillståndet och det totala antalet rader som inte är komprimerade. Nu kommer vi att fylla i mer data i tabellen och när antalet rader når 1 048 577 kommer SQL Server att stänga den första radgruppen och öppna en ny radgrupp.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200',' 24')INSERT INTO Analysis_TableTest VALUES('Europe','Frankrike','Paris','190','23')INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180',' 19')INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')GO 2000000
SQL Server kommer att komprimera denna radgrupp och skapa en ny radgrupp. Alternativet "COMPRESSION_DELAY" låter oss styra hur länge radgruppen väntar i stängd status.
När vi kör kommandona för index underhåll (omorganisera, bygga om) tas de borttagna raderna bort fysiskt och indexet defragmenteras.
När vi uppdaterar (radera + infoga) några rader i den här tabellen, markeras de raderade raderna som "raderade" och nya uppdaterade rader infogas i deltalagret.
Analytisk frågeprestandabenchmark
I den här rubriken kommer vi att fylla i data till Analysis_TableTest-tabellen. Jag la in 4 miljoner poster. (Du måste testa detta steg och nästa steg i din testmiljö. Prestandaproblem kan uppstå och även kommandot DBCC DROPCLEANBUFFERS kan skada prestandan. Detta kommando tar bort all buffertdata från buffertpoolen.)
Nu kommer vi att köra följande analytiska fråga och undersöka prestandavärdena.
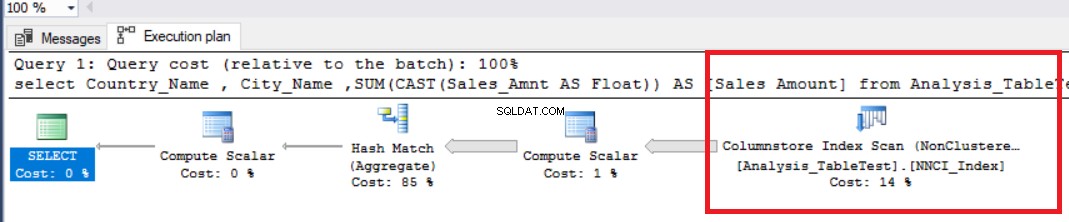
SET STATISTICS TID ONSET STATISTICS IO ONDBCC DROPCLEANBUFFERSvälj Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Försäljningsbelopp]från Analysis_TableTest group byCountry_Name ,City_Name
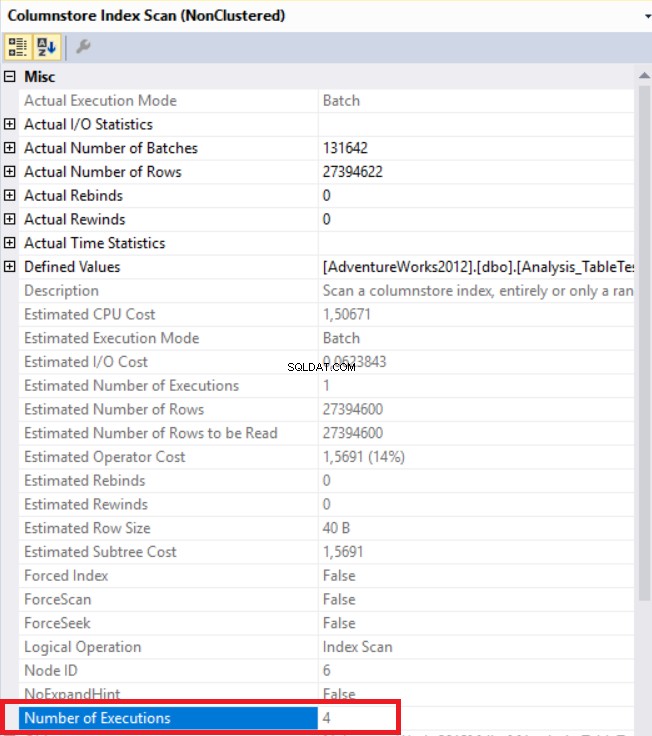
I bilden ovan kan vi se den icke-klustrade kolumnbutiksindexskanningsoperatorn. Tabellen nedan visar CPU- och körtider. Denna fråga förbrukar 1,765 millisekunder i CPU och slutfördes på 0,791 millisekunder. CPU-tiden är längre än den förflutna tiden eftersom exekveringsplanen använder parallella processorer och distribuerar uppgifter till 4 processorer. Vi kan se det i "Columnstore Index Scan" operatörsegenskaper. Värdet "Antal avrättningar" indikerar detta.
Nu kommer vi att lägga till en ledtråd till frågan för att minska antalet processorer. Vi kommer inte att se någon parallellismoperator.
SET STATISTICS TIME ONSET STATISTICS IO ONDBCC DROPCLEANBUFFERSvälj Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Försäljningsbelopp]från Analysis_TableTest group byCountry_Name ,City_NameOPTION (MAXDOP 1)
Tabellen nedan definierar körtider. I det här diagrammet kan vi se att den förflutna tiden är längre än CPU-tiden eftersom SQL Server endast använde en processor.
Nu kommer vi att inaktivera det icke-klustrade kolumnlagringsindexet och köra samma fråga.
ÄNDRA INDEX [NNCI_Index] PÅ [dbo].[Analysis_TableTest] DISABLEGOSET STATISTICS TIME ONSET STATISTICS IO ONDBCC DROPCLEANBUFFERSvälj Country_Name , City_Name ,SUM(CAST(Sales_Amnt_Amnt) AS [Sales_Amnt_Name) AS [Flöta_Namn_MAXTOP Analysgrupp_Max. 1)
Tabellen ovan visar oss det icke-klustrade kolumnbutiksindexet ger otrolig prestanda i analytiska frågor. Den kolumnbutiksindexerade frågan är ungefär fem gånger bättre än den andra.
Slutsats
Operationell analys i realtid ger otrolig flexibilitet eftersom vi kan köra analytiska frågor i OLTP-system utan datalatens. Samtidigt påverkar dessa analytiska frågor inte OLTP-databasens prestanda. Den här funktionen ger oss möjlighet att hantera transaktionsdata och analytiska frågor i samma miljö.
Referenser
Kolumnlagerindex – vägledning för dataladdning
Kom igång med Column Store för operationsanalys i realtid
Driftanalys i realtid
Ytterligare läsning:
SQL Server Index bakåtsökning:Förståelse, justering
Använda index i SQL Server-minnesoptimerade tabeller