Obs! Det här inlägget publicerades ursprungligen endast i vår e-bok, High Performance Techniques for SQL Server, Volym 3. Du kan ta reda på om våra e-böcker här.
Ett krav som jag ser ibland är att få en förfrågan returnerad med beställningar grupperade efter kund, som visar den maximala summan som förfaller för en beställning hittills (ett "löpande max"). Så föreställ dig dessa exempelrader:
| Försäljningsorder-ID | Kund-ID | Beställningsdatum | TotalDue |
|---|---|---|---|
| 12 | 2 | 2014-01-01 | 37,55 |
| 23 | 1 | 2014-01-02 | 45,29 |
| 31 | 2 | 2014-01-03 | 24.56 |
| 32 | 2 | 2014-01-04 | 89,84 |
| 37 | 1 | 2014-01-05 | 32.56 |
| 44 | 2 | 2014-01-06 | 45,54 |
| 55 | 1 | 2014-01-07 | 99,24 |
| 62 | 2 | 2014-01-08 | 12.55 |
Några rader med exempeldata
De önskade resultaten från de angivna kraven är som följer – i klartext, sortera varje kunds beställningar efter datum och lista varje beställning. Om det är det högsta TotalDue-värdet för alla beställningar fram till det datumet, skriv ut den beställningens totalsumma, annars skriv ut det högsta TotalDue-värdet från alla tidigare beställningar:
| Försäljningsorder-ID | Kund-ID | Beställningsdatum | TotalDue | MaxTotalDue |
|---|---|---|---|---|
| 12 | 1 | 2014-01-02 | 45,29 | 45,29 |
| 23 | 1 | 2014-01-05 | 32.56 | 45,29 |
| 31 | 1 | 2014-01-07 | 99,24 | 99,24 |
| 32 | 2 | 2014-01-01 | 37,55 | 37,55 |
| 37 | 2 | 2014-01-03 | 24.56 | 37,55 |
| 44 | 2 | 2014-01-04 | 89,84 | 89,84 |
| 55 | 2 | 2014-01-06 | 45,54 | 89,84 |
| 62 | 2 | 2014-01-08 | 12.55 | 89,84 |
Exempel på önskade resultat
Många människor skulle instinktivt vilja använda en markör eller while-loop för att åstadkomma detta, men det finns flera tillvägagångssätt som inte involverar dessa konstruktioner.
Korrelerad underfråga
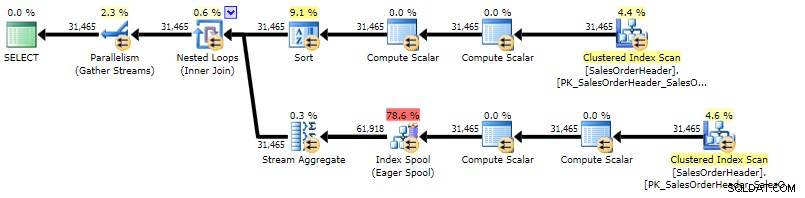
Detta tillvägagångssätt verkar vara det enklaste och mest okomplicerade tillvägagångssättet till problemet, men det har bevisats gång på gång att det inte skalas, eftersom läsningarna växer exponentiellt när tabellen blir större:
SELECT /* Correlated Subquery */ SalesOrderID, CustomerID, OrderDate, TotalDue,
MaxTotalDue = (SELECT MAX(TotalDue)
FROM Sales.SalesOrderHeader
WHERE CustomerID = h.CustomerID
AND SalesOrderID <= h.SalesOrderID)
FROM Sales.SalesOrderHeader AS h
ORDER BY CustomerID, SalesOrderID; Här är planen mot AdventureWorks2014, med SQL Sentry Plan Explorer:
 Utförandeplan för korrelerad underfråga (klicka för att förstora)
Utförandeplan för korrelerad underfråga (klicka för att förstora)
Självrefererande KORSA TILLÄMPNING
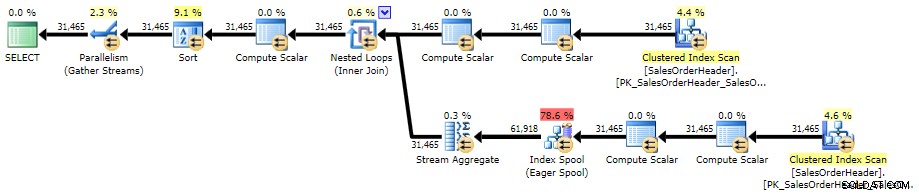
Detta tillvägagångssätt är nästan identiskt med Correlated Subquery-metoden, när det gäller syntax, planform och prestanda i skala.
SELECT /* CROSS APPLY */ h.SalesOrderID, h.CustomerID, h.OrderDate, h.TotalDue, x.MaxTotalDue
FROM Sales.SalesOrderHeader AS h
CROSS APPLY
(
SELECT MaxTotalDue = MAX(TotalDue)
FROM Sales.SalesOrderHeader AS i
WHERE i.CustomerID = h.CustomerID
AND i.SalesOrderID <= h.SalesOrderID
) AS x
ORDER BY h.CustomerID, h.SalesOrderID; Planen är ganska lik den korrelerade underfrågeplanen, den enda skillnaden är platsen för en sort:
 Exekutivplan för CROSS APPLY (klicka för att förstora)
Exekutivplan för CROSS APPLY (klicka för att förstora)
Rekursiv CTE
Bakom kulisserna använder detta loopar, men tills vi faktiskt kör det kan vi liksom låtsas att det inte gör det (även om det lätt är den mest komplicerade kodbiten jag någonsin skulle vilja skriva för att lösa just det här problemet):
;WITH /* Recursive CTE */ cte AS
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue
FROM
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue = TotalDue,
rn = ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID)
FROM Sales.SalesOrderHeader
) AS x
WHERE rn = 1
UNION ALL
SELECT r.SalesOrderID, r.CustomerID, r.OrderDate, r.TotalDue,
MaxTotalDue = CASE
WHEN r.TotalDue > cte.MaxTotalDue THEN r.TotalDue
ELSE cte.MaxTotalDue
END
FROM cte
CROSS APPLY
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue,
rn = ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID)
FROM Sales.SalesOrderHeader AS h
WHERE h.CustomerID = cte.CustomerID
AND h.SalesOrderID > cte.SalesOrderID
) AS r
WHERE r.rn = 1
)
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue
FROM cte
ORDER BY CustomerID, SalesOrderID
OPTION (MAXRECURSION 0); Du kan direkt se att planen är mer komplex än de två föregående, vilket inte är förvånande med tanke på den mer komplexa frågan:
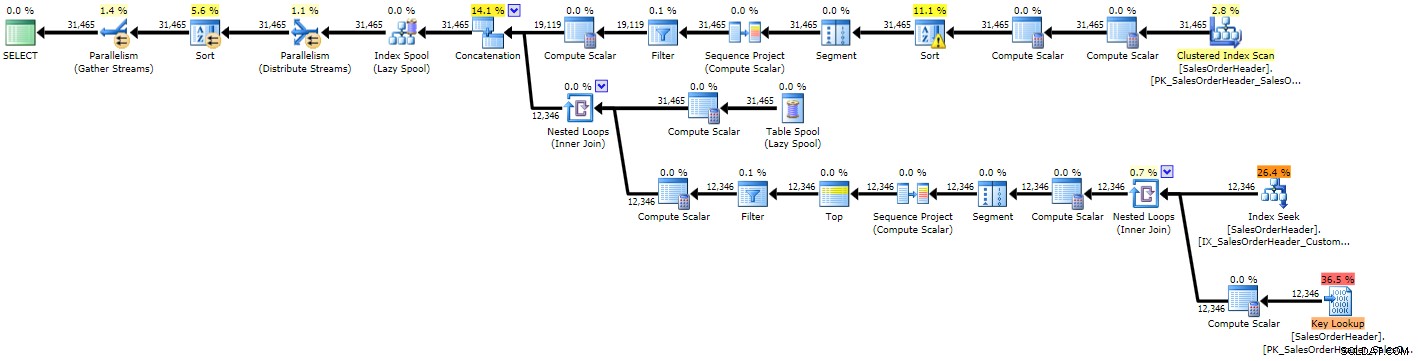 Utförandeplan för rekursiv CTE (klicka för att förstora)
Utförandeplan för rekursiv CTE (klicka för att förstora)
På grund av några dåliga uppskattningar ser vi en indexsökning med en åtföljande nyckelsökning som förmodligen både borde ha ersatts av en enda skanning, och vi får också en sorteringsoperation som i slutändan måste spillas ut till tempdb (du kan se detta i verktygstipset om du håller muspekaren över sorteringsoperatorn med varningsikonen):

MAX() ÖVER (RADER OBEGRÄNSADE)
Detta är en lösning endast tillgänglig i SQL Server 2012 och högre, eftersom den använder nyintroducerade tillägg till fönsterfunktioner.
SELECT /* MAX() OVER() */ SalesOrderID, CustomerID, OrderDate, TotalDue,
MaxTotalDue = MAX(TotalDue) OVER
(
PARTITION BY CustomerID ORDER BY SalesOrderID
ROWS UNBOUNDED PRECEDING
)
FROM Sales.SalesOrderHeader
ORDER BY CustomerID, SalesOrderID; Planen visar exakt varför den skalar bättre än alla andra; den har bara en klustrad indexskanningsoperation, i motsats till två (eller det dåliga valet av en skanning och en sökning + uppslag i fallet med den rekursiva CTE):
 Exekutivplan för MAX() OVER() (klicka för att förstora)
Exekutivplan för MAX() OVER() (klicka för att förstora)
Prestandajämförelse
Planerna får oss verkligen att tro att den nya MAX() OVER() kapacitet i SQL Server 2012 är en riktig vinnare, men vad sägs om påtagliga körtidsmått? Så här jämfördes avrättningarna:

De två första frågorna var nästan identiska; medan i detta fall CROSS APPLY var bättre vad gäller den totala varaktigheten med en liten marginal, den korrelerade underfrågan slår den ibland lite istället. Den rekursiva CTE är avsevärt långsammare varje gång, och du kan se de faktorer som bidrar till det – nämligen de dåliga uppskattningarna, den enorma mängden avläsningar, nyckelsökningen och den extra sorteringsoperationen. Och som jag har visat tidigare med löpande summor är SQL Server 2012-lösningen bättre i nästan alla aspekter.
Slutsats
Om du använder SQL Server 2012 eller senare vill du definitivt bekanta dig med alla tillägg till fönsterfunktionerna som först introducerades i SQL Server 2005 – de kan ge dig några ganska allvarliga prestandahöjningar när du återvänder till kod som fortfarande körs " det gamla sättet." Om du vill lära dig mer om några av dessa nya funktioner rekommenderar jag starkt Itzik Ben-Gans bok, Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions.
Om du inte är på SQL Server 2012 ännu, åtminstone i detta test, kan du välja mellan CROSS APPLY och den korrelerade underfrågan. Som alltid bör du testa olika metoder mot dina data på din hårdvara.