Under den senaste månaden har jag haft kontakt med många kunder som har haft implicita konverteringsproblem på kolumnsidan i samband med deras OLTP-arbetsbelastningar. Vid två tillfällen var den ackumulerade effekten av de implicita konverteringarna på kolumnsidan den underliggande orsaken till det övergripande prestandaproblemet för SQL-servern som granskades, och tyvärr finns det ingen magisk inställning eller konfigurationsalternativ som vi kan justera för att förbättra situationen när så är fallet. Även om vi kan erbjuda förslag för att fixa andra, lägre hängande frukter som kan påverka prestandan totalt sett, är effekten av de implicita konverteringarna på kolumnsidan något som antingen kräver en schemadesignändring för att fixa, eller en kodändring för att förhindra kolumn- sidokonvertering sker helt mot det aktuella databasschemat.
Implicita omvandlingar är resultatet av att databasmotorn jämför värden för olika datatyper under körning av en fråga. En lista över möjliga implicita omvandlingar som kan inträffa inuti databasmotorn finns i ämnet Books Online Data Type Conversion (Databas Engine). Implicita konverteringar sker alltid baserat på datatypens prioritet för de datatyper som jämförs under operationen. Datatypens prioritetsordning finns i Books Online-ämnet Data Type Precedence (Transact-SQL). Jag bloggade nyligen om de implicita omvandlingarna som resulterar i en indexskanning och tillhandahåller diagram som också kan användas för att fastställa de mest problematiska implicita omvandlingarna.
Ställa in testerna
För att visa de prestandakostnader som är förknippade med implicita konverteringar på kolumnsidan som resulterar i en indexskanning, har jag kört en serie olika tester mot databasen AdventureWorks2012 med hjälp av tabellen Sales.SalesOrderDetail för att bygga testtabeller och datamängder. Den vanligaste implicita konverteringen på kolumnsidan som jag ser som konsult sker när kolumntypen är char eller varchar, och applikationskoden skickar en parameter som är nchar eller nvarchar och filtrerar på kolumnen char eller varchar. För att simulera den här typen av scenario skapade jag en kopia av tabellen SalesOrderDetail (som heter SalesOrderDetail_ASCII) och ändrade kolumnen CarrierTrackingNumber från nvarchar till varchar. Dessutom lade jag till ett icke-klustrat index i kolumnen CarrierTrackingNumber till den ursprungliga SalesOrderDetail-tabellen, såväl som den nya SalesOrderDetail_ASCII-tabellen.
USE [AdventureWorks2012]
GO
-- Add CarrierTrackingNumber index to original Sales.SalesOrderDetail table
IF NOT EXISTS
(
SELECT 1 FROM sys.indexes
WHERE [object_id] = OBJECT_ID(N'Sales.SalesOrderDetail')
AND name=N'IX_SalesOrderDetail_CarrierTrackingNumber'
)
BEGIN
CREATE INDEX IX_SalesOrderDetail_CarrierTrackingNumber
ON Sales.SalesOrderDetail (CarrierTrackingNumber);
END
GO
IF OBJECT_ID('Sales.SalesOrderDetail_ASCII') IS NOT NULL
BEGIN
DROP TABLE Sales.SalesOrderDetail_ASCII;
END
GO
CREATE TABLE Sales.SalesOrderDetail_ASCII
(
SalesOrderID int NOT NULL,
SalesOrderDetailID int NOT NULL IDENTITY (1, 1),
CarrierTrackingNumber varchar(25) NULL,
OrderQty smallint NOT NULL,
ProductID int NOT NULL,
SpecialOfferID int NOT NULL,
UnitPrice money NOT NULL,
UnitPriceDiscount money NOT NULL,
LineTotal AS (isnull(([UnitPrice]*((1.0)-[UnitPriceDiscount]))*[OrderQty],(0.0))),
rowguid uniqueidentifier NOT NULL ROWGUIDCOL,
ModifiedDate datetime NOT NULL
);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII ON;
GO
INSERT INTO Sales.SalesOrderDetail_ASCII
(
SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber,
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
)
SELECT
SalesOrderID, SalesOrderDetailID, CONVERT(varchar(25), CarrierTrackingNumber),
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
FROM Sales.SalesOrderDetail WITH (HOLDLOCK TABLOCKX);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII OFF;
GO
ALTER TABLE Sales.SalesOrderDetail_ASCII ADD CONSTRAINT
PK_SalesOrderDetail_ASCII_SalesOrderID_SalesOrderDetailID
PRIMARY KEY CLUSTERED (SalesOrderID, SalesOrderDetailID);
CREATE UNIQUE NONCLUSTERED INDEX AK_SalesOrderDetail_ASCII_rowguid
ON Sales.SalesOrderDetail_ASCII (rowguid);
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_ASCII_ProductID
ON Sales.SalesOrderDetail_ASCII (ProductID);
CREATE INDEX IX_SalesOrderDetail_ASCII_CarrierTrackingNumber
ON Sales.SalesOrderDetail_ASCII (CarrierTrackingNumber);
GO Den nya SalesOrderDetail_ASCII-tabellen har 121 317 rader och är 17,5 MB stor och kommer att användas för att utvärdera omkostnader för en liten tabell. Jag skapade också en tabell som är tio gånger större, med en modifierad version av skriptet Enlarging the AdventureWorks Sample Databases från min blogg, som innehåller 1 334 487 rader och är 190 MB i storlek. Testservern för detta är samma 4 vCPU VM med 4 GB RAM, kör Windows Server 2008 R2 och SQL Server 2012, med Service Pack 1 och Cumulative Update 3, som jag har använt i tidigare artiklar, så tabellerna kommer att passa helt och hållet i minnet , vilket eliminerar disk I/O-overhead från att påverka testerna som körs.
Testarbetsbelastningen genererades med hjälp av en serie PowerShell-skript som väljer listan med CarrierTrackingNumbers från SalesOrderDetail-tabellen som bygger en ArrayList och sedan slumpmässigt väljer ett CarrierTrackingNumber från ArrayList för att fråga SalesOrderDetail_ASCII-tabellen med en varchar-parameter och sedan en nvarchar-parameter, och för att sedan fråga SalesOrderDetail-tabellen med en nvarchar-parameter för att ge en jämförelse för var kolumnen och parametern båda är nvarchar. Vart och ett av de individuella testerna kör uttalandet 10 000 gånger för att tillåta mätning av prestandaöverhead över en ihållande arbetsbelastning.
#No Implicit Conversions
$loop = 10000;
Write-Host "Small table no conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::VarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table no conversion end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table implicit conversions
$loop = 10000;
Write-Host "Small table implicit conversions start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table implicit conversions end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table unicode no implicit conversions
$loop = 10000;
Write-Host "Small table unicode no implicit conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail "
"WHERE CarrierTrackingNumber = @CTNumber;"
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table unicode no implicit conversion end time:"
[DateTime]::Now En andra uppsättning tester kördes mot tabellerna SalesOrderDetailEnlarged_ASCII och SalesOrderDetailEnlarged med samma parametrering som den första uppsättningen tester för att visa omkostnadsskillnaden när storleken på data som lagras i tabellen ökar med tiden. En sista uppsättning tester kördes också mot SalesOrderDetail-tabellen med ProduktID-kolumnen som en filterkolumn med parametertyperna int, bigint och sedan smallint för att ge en jämförelse av overheaden av implicita konverteringar som inte resulterar i en indexskanning för jämförelse.
Obs:Alla skript är bifogade till den här artikeln för att möjliggöra reproduktion av implicita konverteringstester för vidare utvärdering och jämförelse.
Testresultat
Under var och en av testkörningarna konfigurerades Performance Monitor att köra en datainsamlaruppsättning som inkluderade Processor\% Processor Time och SQL Server:SQLStatisitics\Batch Requests/sek-räknare för att spåra prestandaoverheaden för vart och ett av testerna. Dessutom har Extended Events konfigurerats för att spåra händelsen rpc_completed för att tillåta spårning av genomsnittlig varaktighet, cpu_time och logiska läsningar för vart och ett av testerna.
Små tabell CarrierTrackingNumber-resultat
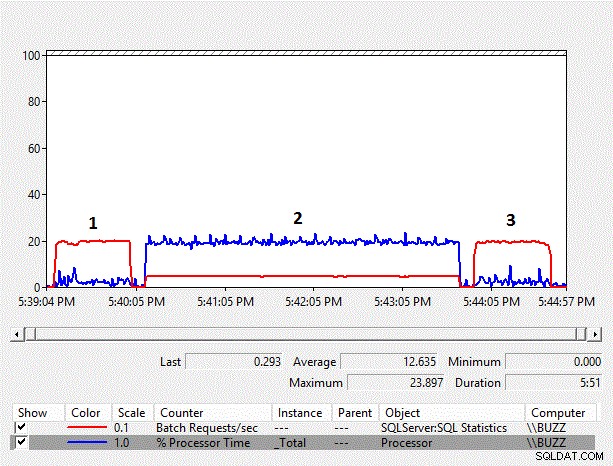
Figur 1 – Resultatövervakningsdiagram över räknare
| TestID | Kolumndatatyp | Parameterdatatyp | Genomsnittlig % processortid | Gen. antal förfrågningar/sek | Längd h:mm:ss |
|---|---|---|---|---|---|
| 1 | Varchar | Varchar | 2.5 | 192.3 | 0:00:51 |
| 2 | Varchar | Nvarchar | 19.4 | 46.7 | 0:03:33 |
| 3 | Nvarchar | Nvarchar | 2.6 | 192.3 | 0:00:51 |
Tabell 2 – Datamedelvärden för resultatövervakning
Från resultaten kan vi se att den implicita konverteringen på kolumnsidan från varchar till nvarchar och den resulterande indexskanningen har en betydande inverkan på arbetsbelastningens prestanda. Den genomsnittliga procentuella processortiden för det implicita konverteringstestet på kolumnsidan (TestID =2) är nästan tio gånger så mycket som de andra testerna där den implicita konverteringen på kolumnsidan, vilket resulterade i en indexskanning, inte inträffade. Dessutom var det genomsnittliga batchbegäran/sek för det implicita konverteringstestet på kolumnsidan strax under 25 % av de andra testerna. Varaktigheten av testerna där implicita omvandlingar inte inträffade tog båda 51 sekunder, även om data lagrades som nvarchar i test nummer 3 med en nvarchar-datatyp, som krävde dubbelt så mycket lagringsutrymme. Detta förväntas eftersom tabellen fortfarande är mindre än buffertpoolen.
| TestID | Gen. cpu_time (µs) | Genomsnittlig varaktighet (µs) | Genomsnittliga logiska_läsningar |
|---|---|---|---|
| 1 | 40.7 | 154.9 | 51.6 |
| 2 | 15 640,8 | 15 760,0 | 385.6 |
| 3 | 45.3 | 169,7 | 52.7 |
Tabell 3 – Genomsnitt för utökade händelser
Data som samlas in av händelsen rpc_completed i Extended Events visar att den genomsnittliga cpu_time, varaktighet och logiska läsningar som är associerade med frågorna som inte utför en implicit konvertering på kolumnsidan är ungefär likvärdiga, där den implicita konverteringen på kolumnsidan medför en betydande CPU overhead, samt en längre genomsnittlig varaktighet med betydligt mer logiska avläsningar.
Förstorad tabell CarrierTrackingNumber-resultat
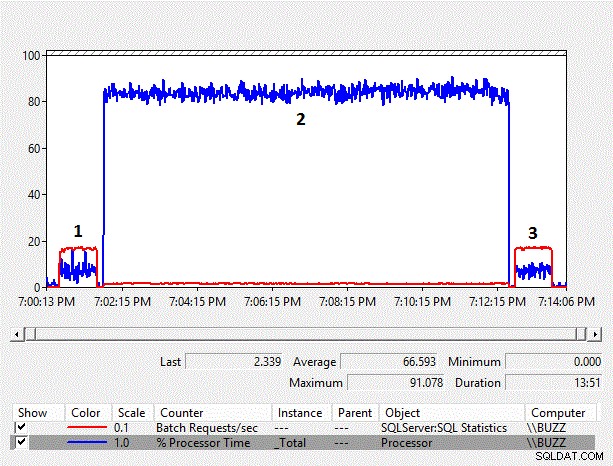
Figur 4 – Resultatövervakningsdiagram över räknare
| TestID | Kolumndatatyp | Parameterdatatyp | Genomsnittlig % processortid | Gen. antal förfrågningar/sek | Längd h:mm:ss |
|---|---|---|---|---|---|
| 1 | Varchar | Varchar | 7.2 | 164.0 | 0:01:00 |
| 2 | Varchar | Nvarchar | 83.8 | 15.4 | 0:10:49 |
| 3 | Nvarchar | Nvarchar | 7.0 | 166.7 | 0:01:00 |
Tabell 5 – Datamedelvärden för Performance Monitor
När storleken på data ökar, ökar också prestandaoverheaden för den implicita konverteringen på kolumnsidan. Den genomsnittliga procentuella processortiden för det implicita konverteringstestet på kolumnsidan (TestID =2) är återigen nästan tio gånger så mycket som de andra testerna där den implicita konverteringen på kolumnsidan som resulterade i en indexskanning inte inträffade. Dessutom var det genomsnittliga batchbegäran/sek för det implicita konverteringstestet på kolumnsidan strax under 10 % av de andra testerna. Varaktigheten av testerna där implicita omvandlingar inte inträffade tog båda en minut, medan det implicita konverteringstestet på kolumnsidan krävde nära elva minuter att utföra.
| TestID | Gen. cpu_time (µs) | Genomsnittlig varaktighet (µs) | Genomsnittliga logiska_läsningar |
|---|---|---|---|
| 1 | 728.5 | 1 036,5 | 569.6 |
| 2 | 214 174,6 | 59 519.1 | 4 358,2 |
| 3 | 821.5 | 1 032,4 | 553.5 |
Tabell 6 – Genomsnitt för utökade händelser
Resultaten för utökade händelser börjar verkligen visa de prestandakostnader som orsakas av de implicita konverteringarna på kolumnsidan för arbetsbelastningen. Den genomsnittliga cpu_time per exekvering hoppar till över 214ms och är över 200 gånger cpu_time för de satser som inte har de implicita konverteringarna på kolumnsidan. Varaktigheten är också nästan 60 gånger så lång som de påståenden som inte har de implicita konverteringarna på kolumnsidan.
Sammanfattning
När storleken på data fortsätter att öka, kommer omkostnaderna förknippade med implicita konverteringar på kolumnsidan som resulterar i en indexsökning för arbetsbelastningen också att fortsätta att växa, och det viktiga att komma ihåg är att någon gång, ingen mängd hårdvara kommer att kunna hantera prestanda overhead. Implicita konverteringar är lätta att förhindra när en bra databasschemadesign finns och utvecklare följer bra applikationskodningstekniker. I situationer där applikationskodningsmetoderna resulterar i parametrisering som utnyttjar nvarchar-parameterisering, är det bättre att matcha databasschemats design med frågeparameteriseringen än att använda varchar-kolumner i databasdesignen och ådra sig prestandaoverhead från den implicita konverteringen på kolumnsidan.
Ladda ner demoskripten:Implicit_Conversion_Tests.zip (5 KB)