Tänker du på en databasdesign för revisionsloggning? Kom ihåg vad som hände med Hans och Gretel:de tyckte att det var ett bra sätt att spåra deras steg att lämna ett enkelt spår av ströbröd.
När vi designar en datamodell är vi utbildade i att tillämpa filosofin att nu är allt som finns . Om vi till exempel utformar ett schema för att lagra priser för en produktkatalog, kanske vi tror att databasen bara behöver berätta för oss priset på varje produkt för närvarande. Men om vi ville veta om priserna ändrades och, i så fall, när och hur dessa ändringar inträffade, skulle vi hamna i trubbel. Naturligtvis skulle vi kunna designa databasen specifikt för att hålla en kronologisk registrering av ändringar – allmänt känd som en granskningsspår eller granskningslogg.
Revisionsloggning tillåter en databas att ha ett "minne" av tidigare händelser. Om vi fortsätter med prislistexemplet, kommer en korrekt granskningslogg att låta databasen berätta exakt när ett pris uppdaterades, vad priset var innan det uppdaterades, vem som uppdaterade det och varifrån.
Loggningslösningar för databasrevision
Det skulle vara bra om databasen kunde hålla en ögonblicksbild av dess tillstånd för varje förändring som sker i dess data. På så sätt kan du gå tillbaka till vilken tidpunkt som helst och se hur data var i det exakta ögonblicket precis som om du spola tillbaka en film. Men det sättet att generera revisionsloggning är uppenbarligen omöjligt; den resulterande informationsvolymen och den tid det skulle ta att generera loggarna skulle vara för hög.
Revisionsloggningsstrategier baseras på att generera revisionsspår endast för data som kan raderas eller ändras. Alla ändringar i dem måste granskas för att återställa ändringar, söka efter data i historiktabeller eller spåra misstänkt aktivitet.
Det finns flera populära tekniker för revisionsloggning, men ingen av dem tjänar alla syften. De mest effektiva är ofta dyra, resurskrävande eller prestandaförsämrande. Andra är billigare när det gäller resurser men är antingen ofullständiga, besvärliga att underhålla eller kräver en uppoffring av designkvalitet. Vilken strategi du väljer beror på applikationskraven och de prestandagränser, resurser och designprinciper du måste respektera.
Out-of-the-box loggningslösningar
Dessa revisionsloggningslösningar fungerar genom att fånga upp alla kommandon som skickas till databasen och generera en ändringslogg i ett separat arkiv. Sådana program erbjuder flera konfigurations- och rapporteringsalternativ för att spåra användaråtgärder. De kan logga alla åtgärder och frågor som skickas till en databas, även när de kommer från användare med högsta behörighet. Dessa verktyg är optimerade för att minimera prestandapåverkan, men det kostar ofta pengar.
Priset för dedikerade revisionsspårlösningar kan motiveras om du hanterar mycket känslig information (såsom medicinska journaler) där varje ändring av data måste övervakas perfekt och granskas och revisionsspåret måste vara oföränderligt. Men när kraven på revisionsspår inte är lika stränga kan kostnaden för en dedikerad loggningslösning vara överdriven.
De inbyggda övervakningsverktygen som erbjuds av relationsdatabassystem (RDBMS) kan också användas för att generera revisionsspår. Anpassningsalternativ tillåter filtrering av vilka händelser som registreras, för att inte generera onödig information eller överbelasta databasmotorn med loggningsoperationer som inte kommer att användas senare. Loggarna som genereras på detta sätt tillåter detaljerad spårning av de operationer som utförs på tabellerna. De är dock inte användbara för att söka i historiktabeller, eftersom de bara registrerar händelser.
Det mest ekonomiska alternativet för att upprätthålla en revisionsspår är att specifikt utforma din databas för revisionsloggning. Denna teknik är baserad på loggtabeller som fylls i av utlösare eller mekanismer som är specifika för programmet som uppdaterar databasen. Det finns inget allmänt accepterat tillvägagångssätt för design av databas för revisionsloggning, men det finns flera vanliga strategier, som var och en har sina för- och nackdelar.
Designtekniker för databasrevisionsloggning
Radversionering för revisionsinloggning
Ett sätt att underhålla ett granskningsspår för en tabell är att lägga till ett fält som anger versionsnumret för varje post. Insättningar i tabellen sparas med ett initialt versionsnummer. Eventuella ändringar eller raderingar blir faktiskt infogningsoperationer, där nya poster genereras med uppdaterade data och versionsnumret ökas med en. Du kan se ett exempel på denna inloggningsdesign för revision nedan:
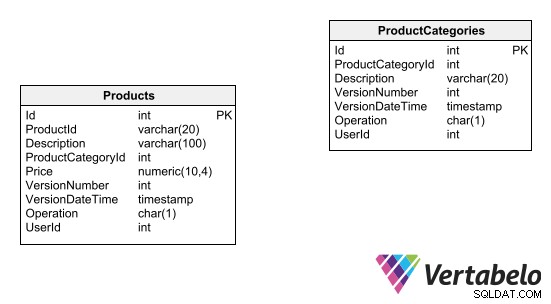
Obs! Tabelldesigner med inbäddad radversionering kan inte länkas med främmande nyckelrelationer.
Utöver versionsnumret bör några extra fält läggas till i tabellen för att fastställa ursprunget och orsaken till varje ändring som görs i en post:
- Datum/tid då ändringen registrerades.
- Användaren och applikationen.
- Åtgärden som utförs (infoga, uppdatera, ta bort), etc. För att granskningsspåret ska vara effektivt måste tabellen endast stödja infogning (uppdateringar och borttagningar ska inte tillåtas). Tabellen kräver också nödvändigtvis en surrogat-primärnyckel, eftersom alla andra kombinationer av fält kommer att bli föremål för upprepning.
För att komma åt den uppdaterade tabelldatan genom frågor måste du skapa en vy som endast returnerar den senaste versionen av varje post. Sedan måste du ersätta namnet på tabellen med namnet på vyn i alla frågor utom de som specifikt är avsedda att se kronologin för poster.
Fördelen med detta versionsalternativ är att det inte kräver att ytterligare tabeller används för att generera revisionsspåret. Dessutom läggs endast ett fåtal fält till i de granskade tabellerna. Men det har en stor nackdel:det kommer att tvinga dig att göra några av de vanligaste databasdesignfelen. Dessa inkluderar att inte använda referensintegritet eller naturliga primärnycklar när det är nödvändigt att göra det, vilket gör det omöjligt att tillämpa de grundläggande principerna för entitetsrelationsdiagramdesign. Du kan besöka dessa användbara resurser om databasdesignfel, så du blir varnad om vilka andra metoder som bör undvikas.
Skuggtabeller
Ett annat revisionsspåralternativ är att generera en skuggtabell för varje tabell som behöver granskas. Skuggtabellerna innehåller samma fält som tabellerna de granskar, plus de specifika granskningsfälten (samma som nämns för radversionstekniken).
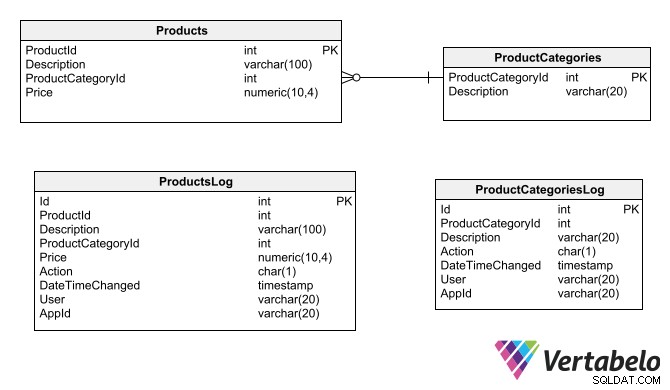
Skuggtabeller replikerar samma fält som tabellerna de granskar, plus de fält som är specifika för granskningsändamål.
För att generera granskningsspår i skuggtabeller är det säkraste alternativet att skapa insättning, uppdatering och radering av triggers, som för varje påverkad post i den ursprungliga tabellen genererar en post i granskningstabellen. Utlösare bör ha tillgång till all revisionsinformation du behöver för att registrera i skuggtabellen. Du måste använda databasmotorns specifika funktionalitet för att få data som aktuellt datum och tid, inloggad användare, applikationsnamn och platsen (nätverksadress eller datornamn) där åtgärden uppstod.
Om det inte är möjligt att använda triggers, bör logiken för att generera granskningsspåren vara en del av applikationsstacken, i ett lager som är idealiskt beläget precis före databeständighetslagret, så att det kan fånga upp alla operationer som är riktade mot databasen.
Den här typen av loggtabell bör endast tillåta postinsättning; om de tillåter ändring eller radering, skulle revisionsspåret inte längre fylla sin funktion. Tabellerna måste också använda primära surrogatnycklar, eftersom beroenden och relationerna för de ursprungliga tabellerna inte kan tillämpas på dem.
Om tabellen som du har skapat en revisionsspår för har tabeller som den beror på, bör dessa också ha motsvarande skuggtabeller. Detta för att revisionsspåret inte ska bli föräldralöst om ändringar görs i de andra tabellerna.
Skuggtabeller är bekväma på grund av deras enkelhet och för att de inte påverkar datamodellens integritet; revisionsspåren finns kvar i separata tabeller och är lätta att fråga. Nackdelen är att schemat inte är flexibelt:varje förändring av huvudbordets struktur måste återspeglas i motsvarande skuggtabell, vilket gör det svårt att underhålla modellen. Dessutom, om granskningsloggning behöver tillämpas på ett stort antal tabeller, kommer antalet skuggtabeller också att vara högt, vilket gör schemaunderhållet ännu svårare.
Allmänna tabeller för granskningsloggning
Ett tredje alternativ är att skapa generiska tabeller för granskningsloggar. Sådana tabeller tillåter loggning av alla andra tabeller i schemat. Endast två tabeller krävs för denna teknik:
En rubriktabell som registrerar:
- Datum och tid för ändringen.
- Namnet på tabellen.
- Nyckeln för den berörda raden.
- Användardata.
- Typen av åtgärd som utförs.
En detaljtabell som registrerar:
- Namnen på varje påverkat fält.
- Fältvärdena före ändringen.
- Fältvärdena efter ändringen. (Du kan utelämna detta vid behov, eftersom det kan erhållas genom att läsa följande post i revisionsspåret eller motsvarande post i den granskade tabellen.)
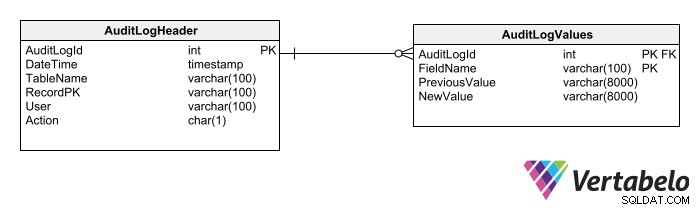
Användningen av generiska granskningsloggtabeller sätter gränser för vilka typer av data som kan granskas.
Fördelen med denna revisionsloggningsstrategi är att den inte kräver några andra tabeller än de två som nämns ovan. Dessutom lagras poster i den endast för de fält som påverkas av en operation. Detta innebär att det inte finns något behov av att replikera en hel rad i en tabell när endast ett fält ändras. Dessutom låter den här tekniken dig föra en logg över så många tabeller du vill – utan att belamra schemat med ett stort antal ytterligare tabeller.
Nackdelen är att fälten som lagrar värdena måste vara av en enda typ – och tillräckligt breda för att lagra även de största av fälten i de tabeller som du vill generera en revisionslogg för. Det är vanligast att använda fält av typen VARCHAR som accepterar ett stort antal tecken.
Om du till exempel behöver generera en granskningslogg för en tabell som har ett VARCHAR-fält på 8 000 tecken, måste fältet som lagrar värdena i granskningstabellen också ha 8 000 tecken. Detta gäller även om du bara lagrar ett heltal i det fältet. Å andra sidan, om din tabell har fält med komplexa datatyper, såsom bilder, binär data, BLOB, etc., måste du serialisera deras innehåll så att de kan lagras i loggtabellernas VARCHAR-fält.
Välj design för din databasgranskningslogg med omtanke
Vi har sett flera alternativ för att generera revisionsloggning, men inget av dem är riktigt optimalt. Du måste anta en loggningsstrategi som inte väsentligt påverkar prestandan för din databas, inte får den att växa överdrivet och kan uppfylla dina spårbarhetskrav. Om du bara vill lagra loggar för ett fåtal tabeller kan skuggtabeller vara det bekvämaste alternativet. Om du vill ha flexibiliteten att logga vilken tabell som helst, kan generiska loggningstabeller vara bäst.
Har du upptäckt ett annat sätt att föra en revisionslogg för dina databaser? Dela det i kommentarsfältet nedan – dina andra databasdesigners kommer att vara mycket tacksamma!