Känner du dig överväldigad av hur lång tid det kommer att ta dig att lära dig att bli databasdesigner? Läs om de grundläggande färdigheter och talanger du behöver – det är inte så hemskt!
När du går i gångarna i snabbköpet, varukorgen i ena handen och inköpslistan i den andra, vad tänker du på? Om du är som jag, föreställer du dig hur du kan förbättra organisationen av hyllorna så att din veckoinköp blir mindre tidskrävande. Eller så kanske du känner samma önskan att organisera och strukturera information när en vän visar dig sin stora samling av tidningar. Eller så kanske det slår när du hanterar dina spellistor för att bättre passa dina preferenser. Om du går genom livet och tänker på hur du ska representera verkligheten i termer av enheter, attribut och relationer, då är din kallelse att vara en databasmodellerare.
Kanske är du inte riktigt lika extrem men du är fortfarande attraherad av tanken på att satsa på databasdesign som en karriär. Hur som helst måste du behärska några nya färdigheter. Vissa av dem är rent tekniska; du kan lära dig dessa färdigheter genom att studera eller läsa och fördjupa dem genom arbetslivserfarenhet. Andra färdigheter involverar icke-teknisk kunskap som du kan lära dig genom kurser, bloggartiklar eller genom att observera andra.
Här är en sammanfattning av de grundläggande kunskaper och färdigheter som varje databasdesigner behöver ha.
Hard Skills Databas Designers behöver
Hårda färdigheter är de som förvärvas genom studier och finslipas genom övning. Om du med konkreta bevis kan visa att du behärskar en hård skicklighet, betyder det att du är kapabel att utföra vilken uppgift som helst som involverar det.
När det gäller databaskunskap inkluderar hårda färdigheter grunderna i databasteori och de olika teknikerna som används för att tillämpa teoretiska begrepp för att lösa konkreta problem. Låt oss titta på var och en av de hårda färdigheter som databasdesigners behöver.
Databasteori
Databasteorin är full av abstrakta begrepp som kan vara svåra att förstå om de inte är förknippade med verkliga fakta. Relationsmodellen, domäner, attribut, relationer och relationer, primära och främmande nycklar, entitetsintegritet, referensintegritet och domänbegränsningar är bara några exempel. Om du lägger till ännu mer komplexa frågor (som relationalgebra eller relationskalkyl) kanske du undrar om det inte skulle vara bättre att välja en karriär som sysslar med konkreta saker som trädgårdsarbete eller gourmetmatlagning.
Få inte panik. Grundliga kunskaper om databasteori är viktigt om du planerar att undervisa högskoleklasser eller uppfinna ett nytt sätt att organisera information. Men för att designa databaser behöver du bara behärska de teorikoncept som gäller för att lösa verkliga problem. Den viktigaste – ABC för databasdesign – är relationsmodellen.
Den relationsmodell
Högskoleprofessorer kommer att berätta att relationsmodellen är en dataorganisationsmekanism baserad på mängdteori och predikatslogik. Men det kommer inte göra dig mycket bra i ditt dagliga arbete som databasmodellerare. I praktiken måste du veta att relationsmodellen är ett intuitivt och enkelt sätt att organisera data i form av tabeller – kallas relationer – som är sammansatta av rader (som också kallas tupler). Varje tabell (eller relation) definieras av dess attribut (eller kolumner).
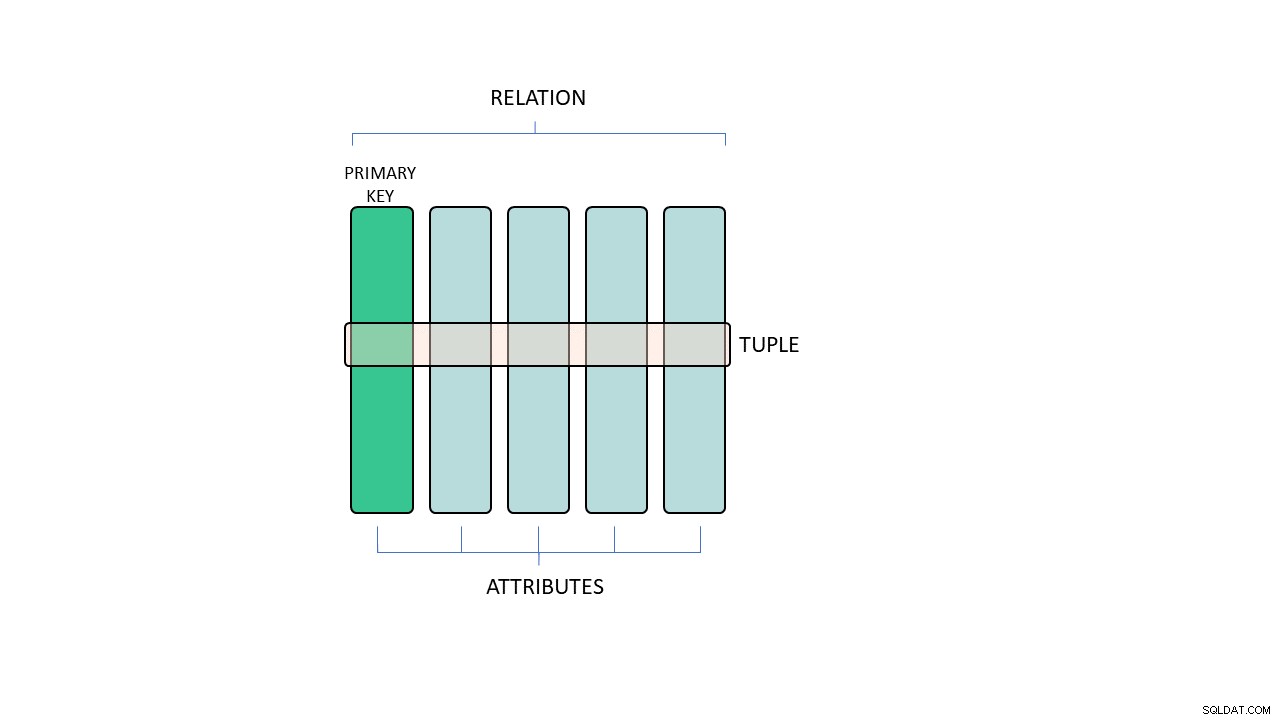
Grundläggande begrepp för relationsmodellen.
Alla relationer bör ha ett eller flera utestående attribut som representerar en unik identifierare för varje tupel. I databasslang är det nyckeln till tabellen. Icke-nyckelattribut är nyckelberoende i den meningen att varje nyckelvärde bestämmer ett enda möjligt värde för varje attribut.
Föreställ dig en tabell med fordonsinformation där nyckeln är registreringsskylten. Registreringsskylten bestämmer attributen för varje fordon (som tillverkare, modell, ägare, etc.), eftersom reglerna för domänen förhindrar att två olika fordon delar samma registreringsskylt.
Relationsdatabaser
Relationella databashanteringssystem (RDBMS) implementerar relationsmodellen och respekterar dess principer. De erbjuder sätt att hämta information genom frågor och uppdatera information genom transaktioner. För att informationen i en relationsdatabas ska återspegla verkliga fakta och situationer kan du definiera villkor eller begränsningar som är specifika för den domän som databasen gäller. Till exempel, i en tabell som lagrar information om skolelever, kan en begränsning införas så att födelsedatum inte tillåter framtida datum eller datum som ligger för långt tillbaka i tiden.
Organisationen av tabeller i en databas kallas vanligtvis för databasschemat. Förutom tabeller beskriver schemat begränsningar som involverar tabellpar som kallas relationer. En relation kopplar samman två tabeller genom att införa begränsningen att värdena i fältet i en av tabellerna motsvarar värden i den andra tabellens primärnyckel.
Databasscheman representeras vanligtvis av entity-relationship diagram (ERD), ett vanligt verktyg för alla databasdesigners.
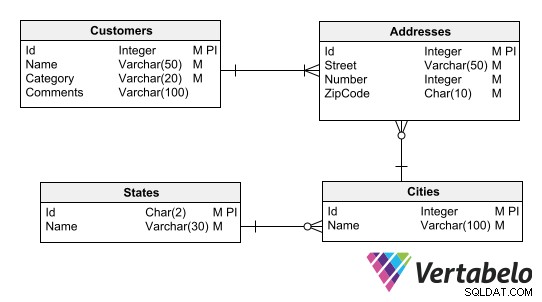
En ERD som representerar en kunddatamodell.
Anomalier och normalisering
Alla begrepp vi har diskuterat hittills är ganska tydliga, eller hur? Nu kan vi prata om de anomalier som uppstår i databaser på grund av bristfällig eller otillräcklig design (dvs databasen återspeglar inte tillräckligt den verklighet den försöker representera).
Avvikelser uppstår när en infogning, uppdatering eller borttagning genererar inkonsekvenser i data. Anta till exempel att du har en tabell för att lagra försäljningsdata. För varje försäljning (dvs. i varje post i tabellen) registreras kundernas namn och adress. Avvikelsen är som följer:
- Om kundens adress ändras i en av försäljningarna, och
- Samma kund har annan försäljning,
- De andra försäljningarna kommer att ha en föråldrad adress.
För att undvika anomalier kan du använda en designteknik som kallas databasnormalisering. Detta innebär att sönderdela tabeller och kolumner (dvs. dela upp dem i mindre delar) för att undvika designfel som:
- Kolumner som innehåller mer än en information (t.ex. en varas ID-nummer och dess namn).
- Lagra samma information mer än en gång i samma tabell.
- Fält som är beroende av andra icke-nyckelfält.
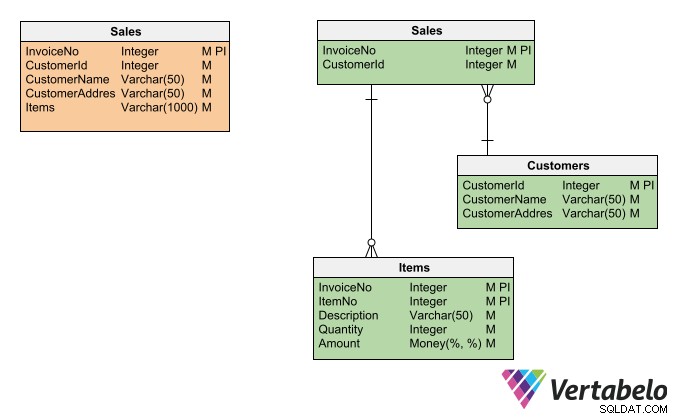
Icke-normaliserad tabell (vänster) kontra normaliserat schema (höger).
Datalager och denormalisering
Vissa databaser används för att söka efter stora mängder information istället för onlinetransaktionsbehandling (OLTP). Dessa databaser kallas datalager.
Informationen i ett datalager kommer inte från användargränssnitt (t.ex. inmatad direkt från ett e-handelsbeställningssystem). Den kommer från batchprocesser som samlar in information från olika källor, bearbetar den, rengör den och lagrar den i tabeller. Av denna anledning kan vi anta att datalager inte utsätts för samma anomalier som konventionella databaser.
På grund av det behöver datalager inte upprätthålla samma normaliseringsvillkor som en OLTP-databas. Å andra sidan är det viktigare att optimera frågeeffektiviteten i datalager. Det är därför denormalisering tillämpas i ett datalager; den här tekniken använder ett visst mått av redundans för att förenkla frågor och undvika rörigare scheman med ett för stort antal tabeller.
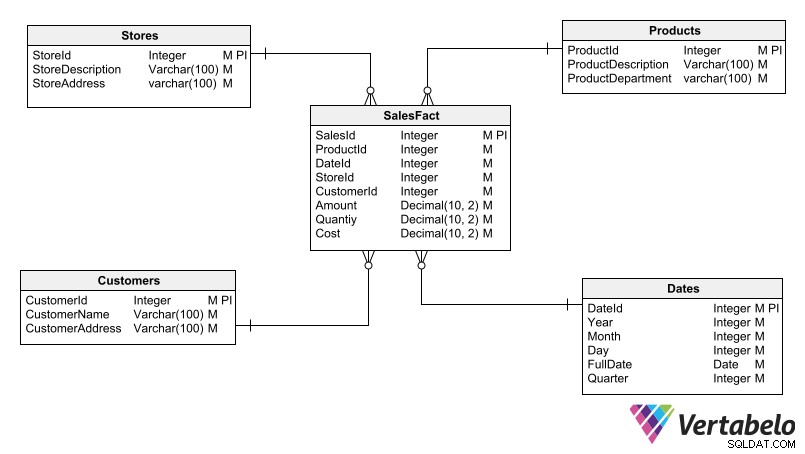
Ett typiskt datalagerschema.
Big Data
Liksom datalager hänvisar konceptet Big Data till arkiv som rymmer stora mängder data. Det finns dock en viktig skillnad mellan de två begreppen. Ett datalager är designat för ett specifikt syfte och syftar till att generera rapporter vars beteende och format är känt i förväg.
Big Data, å andra sidan, syftar till att samla in stora mängder data som genereras i hög hastighet från olika källor – t.ex. information från sociala medier, mikrotransaktioner eller smarta sensorer. Denna enorma mängd information kan användas för utforskning och analys eller för att träna maskininlärningsmodeller.
I Big Data-databasdesign prioriteras lagringsutrymmesekonomi och datapartitionering (bland annat) för att möjliggöra parallellitet och datainsamling i realtid. Dessutom används icke-relationella eller NoSQL-databassystem, som erbjuder bättre alternativ för att hantera ostrukturerad information.
Teknologier som NoSQL och själva konceptet Big Data är relativt nytt jämfört med relationsdatabaser som redan är mer än 40 år gamla. Det är därför du som databasdesigner måste vara uppmärksam på nya utvecklingar inom detta område. Tänk på att Big Data också är big business. Många företag vill ta en ledande position inom det och utvecklar nya verktyg och teknologier för att göra det.
Databasadministration
När en databas väl är igång måste någon ta hand om den dagliga hanteringen. Det innebär att göra rutinuppgifter så att databasen aldrig blir en flaskhals för de applikationer som använder den. Administrationsuppgifter inkluderar att underhålla säkerhetskopior, övervaka förbrukningen av lagringsutrymme, upptäcka krascher mellan processer och åtgärda dataproblem som förhindrar applikationers normala drift.
Den som har databaskompetensen att sköta dessa uppgifter är databasadministratören, eller DBA – när det finns. I mycket små organisationer – eller i utvecklingsmiljöer där driften av databaserna inte är kritisk för verksamheten – kan ansvaret för databasunderhållet falla på databasmodelleraren. Därför bör du ha viss kunskap som gör att du kan ta över från DBA i vissa situationer. Du bör dock under inga omständigheter acceptera ansvaret för att administrera en databas i en produktionsmiljö som stöder affärs- eller verksamhetskritiska applikationer .
Administrationsuppgifterna varierar mycket beroende på databassystemet och den infrastruktur som det är monterat på. Till exempel är uppgifterna för att hantera Microsoft SQL Server-databaser mycket olika från dem att hantera MySQL- eller Oracle-databaser. Och att hantera en server som du kör lokalt på din bärbara dator skiljer sig mycket från att hantera en som körs i molnet.
Jag rekommenderar inte att du ägnar mycket ansträngning åt att lära dig hur man hanterar en viss databasserver, eftersom du kommer att hantera väldigt olika databaser och miljöer under hela din karriär. Det hjälper dig inte att specialisera dig på bara en.
Samtidighets- och transaktionshantering
Samtidig åtkomst till en databas kan orsaka problem i applikationer när flera användare försöker komma åt samma resurs samtidigt. Vi kanske tror att som designers är detta inte vår sak och att det är DBA:s ansvar att hantera dessa problem. Vi kanske också tror att det är programmerarnas fel att skapa applikationer som tillåter dem.
Men designers kan göra sitt för att minimera potentiella samtidighetsproblem genom att utforma system som undviker dem.
Många samtidighetsproblem uppstår när långa och komplexa transaktioner utförs på en databas; medan transaktionen bearbetas blockeras de inblandade tabellerna för andra processer som behöver dem för att läsa eller skriva information. För att undvika denna typ av problem är det bästa du kan göra att se till att dina mönster överensstämmer åtminstone upp till den tredje normala formen. Sedan blir det programmerarens ansvar att tänka igenom transaktionerna korrekt för att undvika dödlägen.
Men du kan också använda strategier som undviker samtidighet, som att partitionera scheman eller gruppera tabeller efter den funktion som var och en fyller.
Låt oss föreställa oss en databas för en e-handelsplats. Du kan placera basdatatabellerna för produkter, lager och priser i ett schema och beställningar och försäljning i ett annat, tillsammans med vyer eller skrivskyddade repliker av tabellerna från det första schemat. Detta hjälper till att undvika fel vid exekvering av transaktioner som uppdaterar basdata.
Databasdesignverktyg
Om du förstår relationsmodellen, entitetsrelationsdiagram och normaliseringstekniker kan du designa databaser utan något annat verktyg än penna och papper. Din prestanda kommer dock att förbättras avsevärt om du använder ett intelligent verktyg, särskilt ett som kan automatisera vissa designuppgifter som att flytta eller ändra objekt i ett diagram, upptäcka designfel, generera SQL-skript för att skapa eller uppdatera en databas och vända- utveckla en befintlig databasdesign.
Att bemästra ett specialiserat verktyg som Vertabelo-plattformen gör att du kan arbeta mycket snabbare. Och det gör att du kan sticka ut från andra designers som inte har den här hjälpen.
SQL och programmering
Vi skulle alla vilja kunna leverera en databasdesign, säga stolt "Mitt arbete här är gjort" och åka iväg på en välförtjänt semester. Men vanligtvis inträffar den idealiska situationen aldrig. När du är klar med din design måste applikationsprogrammerarna använda den och de måste ha dig i närheten för att hjälpa dem.
Ett sätt du bör fortsätta att hjälpa till i ett utvecklingsprojekt är att skriva vyer, triggers, lagrade procedurer och annat i SQL (Structured Query Language) för att lösa särskilda applikationsbehov. Ett annat sätt är att övervaka de programmeringsuppgifter som utförs med något som kallas Object-Relational Mapping (ORM).
ORM:er är avsedda att abstrahera dataåtkomst från en viss RDBMS. Den goda sidan av detta är att programmerare inte behöver oroa sig för detaljerna i databasen de kommer att använda – med andra ord, de behöver inte bry sig om RDBMS är MySQL, Oracle, IBM DB2, MS SQL Server , eller något annat.
Nackdelen med ORM är att databasdesignobjekten – tabeller, attribut och relationer – definieras i koden för ett högnivåprogrammeringsspråk som Java, Python, R eller C#. Med andra ord, de är där vi databasdesigners inte kan se dem.
Lösningen på detta problem ligger i Agila utvecklingsmetoder och deras samarbetsfilosofi. Dessa främjar designers och programmerare som arbetar tillsammans under ett projekts gång, så du vill behålla en god relation med programmerarna. Du bör vara villig att sitta bredvid dem, titta på programmeringskoden och gemensamt skriva definitionerna av dataobjekten.
Soft Skills Databas Designers borde ha
Utöver den teoretiska och tekniska kunskapen som är specifik för databasdesign, bör en designer helst ha andra färdigheter som kallas "mjuka färdigheter". Dessa färdigheter – som att vara en bra kommunikatör och förstå företagets vision för slutprodukten – påverkar indirekt framgången för ditt arbete. De jag nämner nedan är bara några exempel, men det finns många fler mjuka färdigheter som uppskattas mycket av potentiella arbetsgivare.
Affärsvision
När du designar en databas representerar du verkligheten i ett företag i termer av inbördes relaterade dataobjekt. Vi har sett att designen måste uppfylla standardiseringsvillkor och att den måste undvika inkonsekvenser, anomalier och samtidighetsproblem. Men lika viktigt – eller kanske ännu viktigare – är att designen är i linje med affärsvisionen för den som betalar din lön.
Genom att förstå affärsvisionen kan du bättre förstå vikten av varje krav och vägleda dina beslut så att dina konstruktioner är bättre anpassade till organisationens mål.
Här är ett enkelt exempel på hur förståelse av affärsvisionen kommer att forma ditt arbete. Du kanske tycker att användningen av en surrogatnyckel i ett bord stör din design och lägger till ett onödigt och irriterande element. Men genom att utelämna surrogatnyckeln kan du sakta ner frågorna i den tabellen eftersom en nyckel av INTEGER-typ kan ge överlägsen prestanda. Om affärsvisionen är att tillhandahålla snabba frågor, är surrogatnyckeln rätt väg att gå.
Kommunikationsförmåga
Det räcker inte att göra fantastiska mönster. Du måste också kunna förklara varför din design fungerar. Sättet att göra detta är att veta hur man presenterar det, både diskursivt (talat eller skriftligt) och visuellt.
Gör en lista över styrkorna i din design så att de sticker ut. Tänk på de beslut du tog för att skapa den och skriv ner skälen till dessa beslut. Var beredd att försvara dina beslut och din design för dem som inte förstår det eller som vill ändra det, vilket gör det ofullkomligt eller felaktigt.
Men du måste också vara villig att acceptera konstruktiv kritik och överväga synpunkter som skiljer sig från dina egna. Ibland kan en programmerare upptäcka ett problem som du inte såg och ge dig goda råd. Avvisa inte dina kollegor eftersom de tror att de inte har databaskunskaper.
Mellanmänskliga färdigheter
Jag har kommenterat ovan om fördelarna med att ha en bra relation med programmerare. Oavsett hur avancerad du är inom ditt expertområde är det viktigt att du upprätthåller en attityd av sällskap med alla teammedlemmar, oavsett om det är en testare som upptäckt en defekt som tvingar dig att tänka om en del av din design eller en projektledare som behöver dig att utföra en uppgift till ett visst datum. Kort sagt, du måste vara en lagspelare . Ingen vill ha primadonnor i sitt lag som känner sig oersättliga och vill påtvinga sina regler.
Det kan hända att du inte är den enda databasdesignern i ett utvecklingsteam. Kanske måste du leda en undergrupp av dina kollegor. För att göra det måste du visa ledarskapsförmåga och agera som projektledare och se till att teamet av databasdesigners uppfyller sina mål och förblir motiverade.
Hur man lär sig färdigheter i databasdesign
Du kan förvärva de färdigheter du behöver för att vara en databasdesigner från universitetsexamina, kurser, böcker och specialiserade artiklar. Fördelen med universitetskurser är att de ger dig all den kunskap du behöver och stödjer den kunskapen med en erkänd examen. Nackdelen är att de kräver en stor investering av tid och pengar.
Om du föredrar att lära dig på egen hand genom att läsa böcker och artiklar, kommer du att spara tid och pengar – men du behöver en guide som leder dig genom de väsentliga ämnena och för att utvärdera dina kunskaper. Och du måste visa dina kunskaper på ett praktiskt sätt, eftersom du inte har en examen för att backa upp det.
I alla fall, oavsett om du lär dig genom att gå kurser eller läsa, kommer den kunskapen bara att fungera som en grund. Du kommer att lära dig mest genom att skapa modeller, möta verkliga problem och observera dina kollegors och arbetskamraters handlingar.