Skalära UDF:er har alltid varit ett tveeggat svärd – de är bra för utvecklare, som får abstrahera tråkig logik istället för att upprepa den över hela sina frågor, men de är hemska för körtidsprestanda i produktionen, eftersom optimeraren inte inte hantera dem snyggt. Vad som i huvudsak händer är att UDF-avrättningarna hålls åtskilda från resten av exekveringsplanen, så att de anropas en gång för varje rad och kan inte optimeras baserat på uppskattat eller faktisk antal rader eller vikas in i resten av planen.
Eftersom vi, trots våra bästa ansträngningar sedan SQL Server 2000, inte effektivt kan stoppa skalära UDF:er från att användas, skulle det inte vara bra att få SQL Server att helt enkelt hantera dem bättre?
SQL Server 2019 introducerar en ny funktion som heter Scalar UDF Inlining. Istället för att hålla isär funktionen så inarbetas den i översiktsplanen. Detta leder till en mycket bättre utförandeplan och i sin tur bättre körtidsprestanda.
Men först, för att bättre illustrera källan till problemet, låt oss börja med ett par enkla tabeller med bara några rader, i en databas som körs på SQL Server 2017 (eller på 2019 men med en lägre kompatibilitetsnivå):
CREATE DATABASE Whatever; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 140; GO USE Whatever; GO CREATE TABLE dbo.Languages ( LanguageID int PRIMARY KEY, Name sysname ); CREATE TABLE dbo.Employees ( EmployeeID int PRIMARY KEY, LanguageID int NOT NULL FOREIGN KEY REFERENCES dbo.Languages(LanguageID) ); INSERT dbo.Languages(LanguageID, Name) VALUES(1033, N'English'), (45555, N'Klingon'); INSERT dbo.Employees(EmployeeID, LanguageID) SELECT [object_id], CASE ABS([object_id]%2) WHEN 1 THEN 1033 ELSE 45555 END FROM sys.all_objects;
Nu har vi en enkel fråga där vi vill visa varje anställd och namnet på deras primära språk. Låt oss säga att den här frågan används på många ställen och/eller på olika sätt, så istället för att bygga in en koppling i frågan, skriver vi en skalär UDF för att abstrahera bort kopplingen:
CREATE FUNCTION dbo.GetLanguage(@id int) RETURNS sysname AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END
Då ser vår faktiska fråga ut ungefär så här:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
Om vi tittar på exekveringsplanen för frågan saknas något konstigt nog:
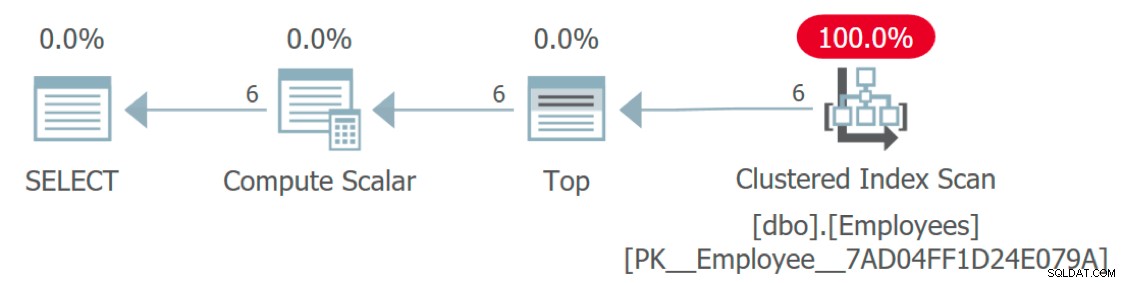 Exekutivplan som visar åtkomst till anställda men inte till språk
Exekutivplan som visar åtkomst till anställda men inte till språk
Hur kommer man åt tabellen Språk? Den här planen ser väldigt effektiv ut eftersom den – precis som själva funktionen – abstraherar bort en del av komplexiteten. Faktum är att den här grafiska planen är identisk med en fråga som bara tilldelar en konstant eller variabel till Language kolumn:
SELECT TOP (6) EmployeeID, Language = N'Sanskrit' FROM dbo.Employees;
Men om du kör en spårning mot den ursprungliga frågan kommer du att se att det faktiskt finns sex anrop till funktionen (ett för varje rad) utöver huvudfrågan, men dessa planer returneras inte av SQL Server.
Du kan också verifiera detta genom att kontrollera sys.dm_exec_function_stats , men det här är ingen garanti :
SELECT [function] = OBJECT_NAME([object_id]), execution_count FROM sys.dm_exec_function_stats WHERE object_name(object_id) IS NOT NULL;
function execution_count ----------- --------------- GetLanguage 6
SentryOne Plan Explorer kommer att visa påståendena om du genererar en faktisk plan inifrån produkten, men vi kan bara få dem från spårning, och det finns fortfarande inga planer samlade eller visade för de individuella funktionsanropen:
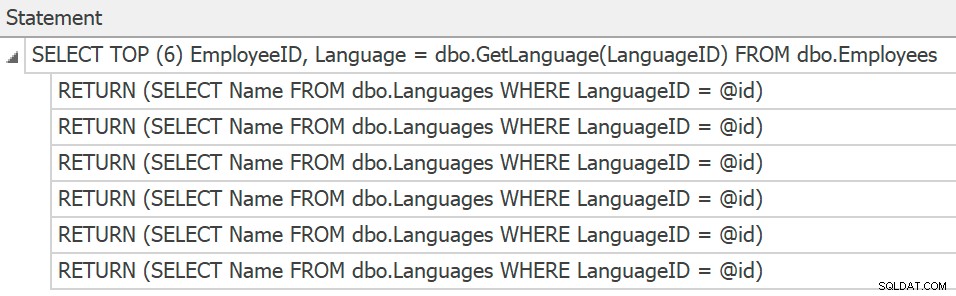 Spåra uttalanden för individuella skalära UDF-anrop
Spåra uttalanden för individuella skalära UDF-anrop
Allt detta gör dem mycket svåra att felsöka, eftersom du måste gå på jakt efter dem, även när du redan vet att de är där. Det kan också göra en rejäl röra av prestandaanalys om du jämför två planer baserat på saker som uppskattade kostnader, eftersom de relevanta operatörerna inte bara gömmer sig från det fysiska diagrammet, kostnaderna är inte heller inkluderade någonstans i planen.
Snabbspolning framåt till SQL Server 2019
Efter alla dessa år av problematiskt beteende och oklara grundorsaker har de gjort det så att vissa funktioner kan optimeras i den övergripande genomförandeplanen. Scalar UDF Inlining gör objekten de kommer åt synliga för felsökning *och* gör att de kan vikas in i exekveringsplanens strategi. Nu tillåter kardinalitetsuppskattningar (baserade på statistik) anslutningsstrategier som helt enkelt inte var möjliga när funktionen anropades en gång för varje rad.
Vi kan använda samma exempel som ovan, antingen skapa samma uppsättning objekt på en SQL Server 2019-databas, eller skrubba plancachen och upp kompatibilitetsnivån till 150:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 150; GO
Nu när vi kör vår sexradsfråga igen:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
Vi får en plan som inkluderar tabellen Språk och kostnaderna för att komma åt den:
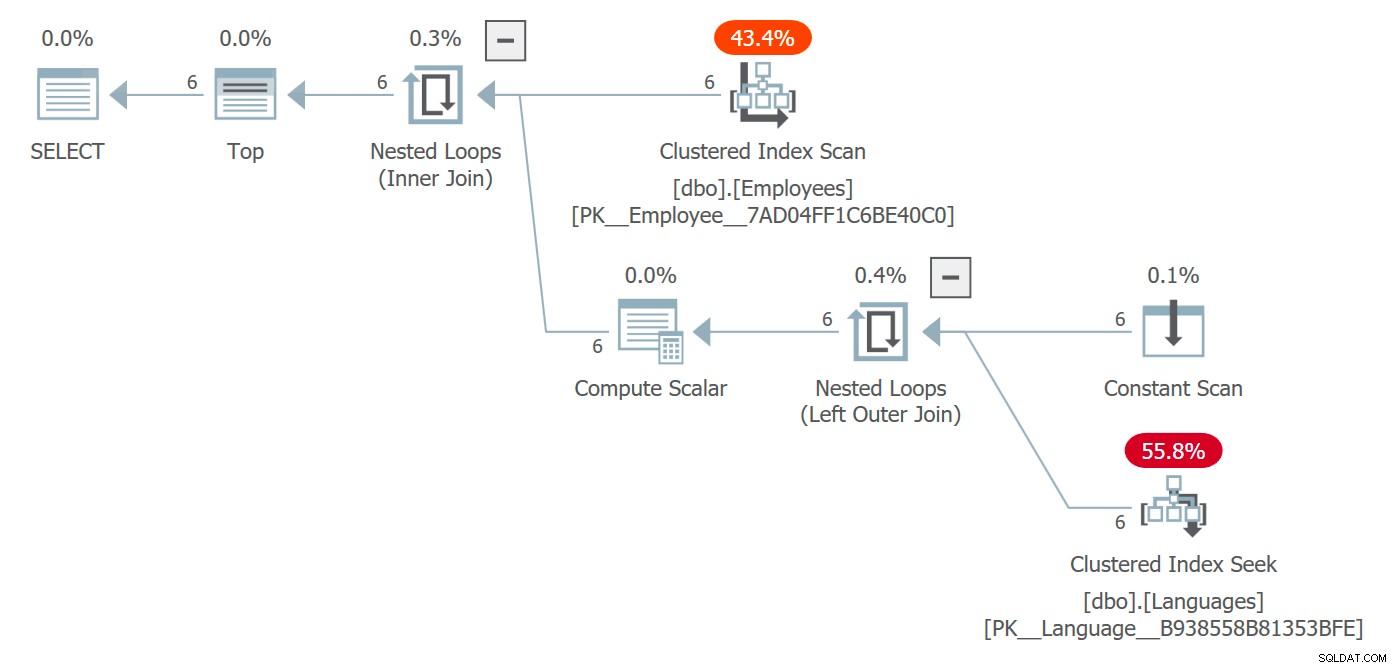 Plan som inkluderar åtkomst till objekt som hänvisas till i skalär UDF
Plan som inkluderar åtkomst till objekt som hänvisas till i skalär UDF
Här valde optimeraren en kapslad loop-koppling, men under andra omständigheter kunde den ha valt en annan sammanfogningsstrategi, övervägt parallellitet och varit i princip fri att helt ändra planformen. Du kommer sannolikt inte att se detta i en fråga som returnerar 6 rader och inte är ett prestandaproblem på något sätt, men i större skala kan det.
Planen återspeglar att funktionen inte anropas per rad – medan sökningen faktiskt körs sex gånger kan du se att själva funktionen inte längre visas i sys.dm_exec_function_stats . En nackdel som du kan ta bort är att om du använder denna DMV för att avgöra om en funktion används aktivt (som vi ofta gör för procedurer och index), kommer den inte längre att vara tillförlitlig.
Varningar
Inte alla skalära funktioner är inlineable och även när en funktion *är* inlineable, kommer den inte nödvändigtvis att infogas i varje scenario. Detta har ofta att göra med antingen funktionens komplexitet, komplexiteten hos den inblandade frågan eller kombinationen av båda. Du kan kontrollera om en funktion är inlinebar i sys.sql_modules katalogvy:
SELECT OBJECT_NAME([object_id]), definition, is_inlineable FROM sys.sql_modules;
Och om du, av någon anledning, inte vill att en viss funktion (eller någon funktion i en databas) ska infogas, behöver du inte förlita dig på databasens kompatibilitetsnivå för att kontrollera det beteendet. Jag har aldrig gillat den där lösa kopplingen, som liknar att byta rum för att se ett annat tv-program istället för att bara byta kanal. Du kan styra detta på modulnivå med alternativet INLINE:
ALTER FUNCTION dbo.GetLanguage(@id int) RETURNS sysname WITH INLINE = OFF AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END GO
Och du kan kontrollera detta på databasnivå, men separat från kompatibilitetsnivå:
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF;
Även om du måste ha ett ganska bra användningsområde för att svänga den hammaren, IMHO.
Slutsats
Nu, jag föreslår inte att du kan gå och abstrahera varje del av logik till en skalär UDF, och anta att nu kommer SQL Server bara att ta hand om alla fall. Om du har en databas med mycket skalär UDF-användning, bör du ladda ner den senaste SQL Server 2019 CTP, återställa en säkerhetskopia av din databas där och kontrollera DMV för att se hur många av dessa funktioner som kommer att vara inlineable när det är dags. Det kan vara en viktig punkt nästa gång du argumenterar för en uppgradering, eftersom du i princip kommer att få tillbaka all den prestanda och bortkastad felsökningstid.
Under tiden, om du lider av skalär UDF-prestanda och du inte kommer att uppgradera till SQL Server 2019 någon gång snart, kan det finnas andra sätt att lindra problemet/problemen.
Obs! Jag skrev och ställde den här artikeln i kö innan jag insåg att jag redan hade lagt upp en annan artikel någon annanstans.