Först introducerades i SQL Server 2017 Enterprise Edition, en adaptiv koppling möjliggör en körtidsövergång från en hash-koppling i batchläge till en korrelerad kapslad loop i radläge som indexeras (tillämpa) vid körning. För korthetens skull hänvisar jag till en "korrelerad kapslad loops indexerad koppling" som en apply i resten av den här artikeln. Om du behöver en uppdatering om skillnaden mellan kapslade loopar och applicera, läs min tidigare artikel.
Huruvida en adaptiv koppling övergår från en hash-koppling till att tillämpas vid körning beror på ett värde märkt Adaptive Threshold Rows på Adaptive Join verkställighetsplanoperatör. Den här artikeln visar hur en adaptiv koppling fungerar, inkluderar detaljer om tröskelberäkningen och täcker konsekvenserna av några av de designval som gjorts.
Introduktion
En sak jag vill att du ska ha i åtanke genom hela det här stycket är en adaptiv koppling alltid börjar köras som en hash-join i batchläge. Detta gäller även om exekveringsplanen indikerar att den adaptiva kopplingen förväntas köras som ett radläge.
Precis som vilken hash-join som helst, läser en adaptiv join alla rader som är tillgängliga på sin build-ingång och kopierar nödvändig data till en hashtabell. Batchlägessmaken för hash join lagrar dessa rader i ett optimerat format och partitionerar dem med en eller flera hashfunktioner. När bygginmatningen har förbrukats är hashtabellen helt ifylld och partitionerad, redo för hash-join för att börja kontrollera rader på söksidan för matchningar.
Detta är den punkt där en adaptiv koppling gör att beslutet att fortsätta med hash-kopplingen i batchläge eller att övergå till ett radläge gäller. Om antalet rader i hashtabellen är mindre än tröskeln värde, kopplingen växlar till en applicering; annars fortsätter joinen som en hash-join genom att börja läsa rader från sondens ingång.
Om en övergång till en appliceringskoppling inträffar läser exekveringsplanen inte om raderna som används för att fylla i hashtabellen för att driva appliceringsoperationen. Istället en intern komponent känd som en adaptiv buffertläsare expanderar raderna som redan är lagrade i hashtabellen och gör dem tillgängliga på begäran för appliceringsoperatörens yttre ingång. Det finns en kostnad förknippad med den adaptiva buffertläsaren, men den är mycket lägre än kostnaden för att helt spola tillbaka bygginmatningen.
Välja en Adaptive Join
Frågeoptimering involverar ett eller flera steg av logisk utforskning och fysisk implementering av alternativ. I varje skede, när optimeraren utforskar de fysiska alternativen för en logisk join, kan det överväga att både batch-läge hash join och radläge tillämpar alternativ.
Om ett av dessa fysiska anslutningsalternativ är en del av den billigaste lösningen som finns under det aktuella skedet—och den andra typen av koppling kan leverera samma nödvändiga logiska egenskaper – optimeraren markerar den logiska kopplingsgruppen som potentiellt lämplig för en adaptiv sammanfogning. Om inte, slutar övervägandet av en adaptiv koppling här (och ingen utökad adaptiv koppling aktiveras).
Den normala driften av optimeraren innebär att den billigaste lösningen som hittas endast kommer att innehålla ett av de fysiska anslutningsalternativen – antingen hash eller applicera, beroende på vilket som hade den lägsta uppskattade kostnaden. Nästa sak som optimeraren gör är att bygga och kosta en ny implementering av den typ av join som inte var vald som billigast.
Eftersom den aktuella optimeringsfasen redan har avslutats med en hittad billigaste lösning, utförs en speciell utforsknings- och implementeringsrunda i en grupp för den adaptiva sammanfogningen. Slutligen beräknar optimeraren den anpassade tröskeln .
Om något av föregående arbete misslyckas, aktiveras den utökade händelsen adaptive_join_skipped med en anledning.
Om den adaptiva anslutningsbearbetningen lyckas, en Concat operatören läggs till i den interna planen ovanför hashen och tillämpar alternativ med den adaptiva buffertläsaren och eventuella batch/radlägesadaptrar. Kom ihåg att endast ett av kopplingsalternativen kommer att köras under körning, beroende på antalet rader som faktiskt påträffas jämfört med den adaptiva tröskeln.
Den Concat operatör och individuella hash-/tillämpningsalternativ visas normalt inte i den slutliga genomförandeplanen. Vi presenteras istället för en enda Adaptive Join operatör. Det här är bara ett presentationsbeslut—Concat och joins finns fortfarande i koden som körs av SQL Server-exekveringsmotorn. Du kan hitta mer information om detta i avsnitten Appendix och relaterad läsning i den här artikeln.
Den adaptiva tröskeln
En applicering är generellt sett billigare än en hash-join för ett mindre antal körrader. Hashjoin har en extra startkostnad för att bygga sin hashtabell men en lägre kostnad per rad när den börjar söka efter matchningar.
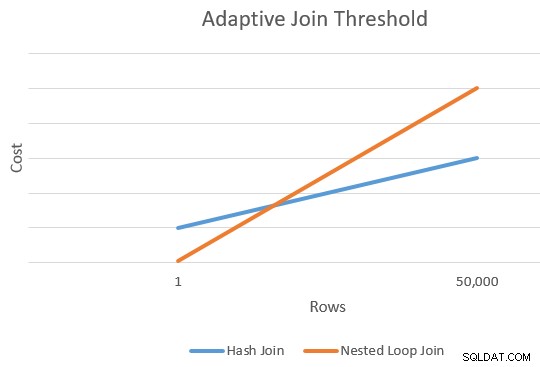
Det finns vanligtvis en punkt där den uppskattade kostnaden för en applicering och en hash-anslutning kommer att vara lika. Den här idén illustrerades fint av Joe Sack i hans artikel Introducing Batch Mode Adaptive Joins:
Beräkna tröskeln
Vid denna tidpunkt har optimeraren en enda uppskattning av antalet rader som går in i bygginmatningen för hash-kopplingen och tillämpar alternativ. Den har också den uppskattade kostnaden för hashen och appliceringsoperatörer som helhet.
Detta ger oss en enda punkt längst till höger på de orangea och blå linjerna i diagrammet ovan. Optimeraren behöver en annan referenspunkt för varje sammanfogningstyp så att den kan "rita linjerna" och hitta skärningspunkten (den ritar inte bokstavligen linjer, men du förstår idén).
För att hitta en andra punkt för linjerna, ber optimeraren de två kopplingarna att producera en ny kostnadsuppskattning baserad på en annan (och hypotetisk) indatakardinalitet. Om den första kardinalitetsuppskattningen var mer än 100 rader, ber den sammanfogningarna att uppskatta nya kostnader för en rad. Om den ursprungliga kardinaliteten var mindre än eller lika med 100 rader, baseras den andra punkten på en indatakardinalitet på 10 000 rader (så det finns ett tillräckligt intervall för att extrapolera).
I vilket fall som helst blir resultatet två olika kostnader och radantal för varje kopplingstyp, vilket gör att linjerna kan "ritas".
Korsningsformeln
Att hitta skärningspunkten mellan två linjer baserat på två punkter för varje linje är ett problem med flera välkända lösningar. SQL Server använder en baserad på determinanter som beskrivs på Wikipedia:
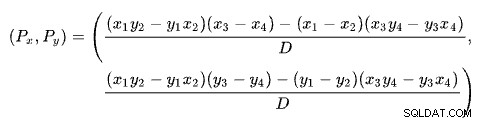
där:
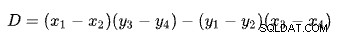
Den första raden definieras av punkterna (x1 , y1 ) och (x2 , y2 ). Den andra raden ges av punkterna (x3 , y3 ) och (x4 , y4 ). Korsningen är vid (Px , Py ).
Vårt schema har antalet rader på x-axeln och den uppskattade kostnaden på y-axeln. Vi är intresserade av antalet rader där linjerna skär varandra. Detta ges av formeln för Px . Om vi ville veta den beräknade kostnaden vid korsningen skulle det vara Py .
För Px rader skulle de uppskattade kostnaderna för applicerings- och hash-join-lösningarna vara lika. Det här är den adaptiva tröskeln vi behöver.
Ett fungerande exempel
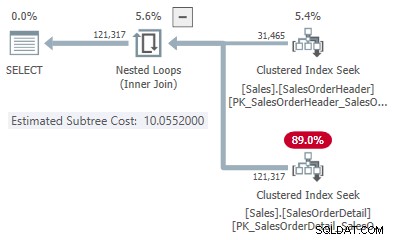
Här är ett exempel med hjälp av Exempeldatabasen AdventureWorks2017 och följande indexeringstrick av Itzik Ben-Gan för att få ovillkorligt övervägande av körning av batchläge:
-- Itziks trick SKAPA ICKE CLUSTERED COLUMNSTORE INDEX BatchModeON Sales.SalesOrderHeader (SalesOrderID)WHERE SalesOrderID =-1AND SalesOrderID =-2; -- Testfråga SELECT SOH.SubTotalFROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123;
Utförandeplanen visar en adaptiv sammanfogning med en tröskel på 1502.07 rader:
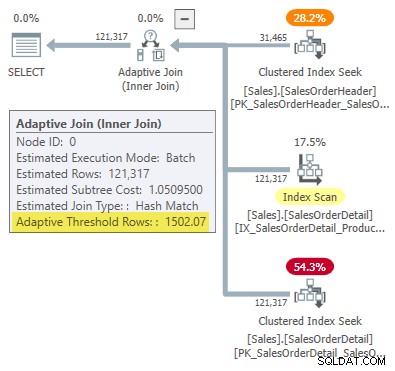
Det uppskattade antalet rader som driver den adaptiva kopplingen är 31 465 .
Anslutningskostnader
I det här förenklade fallet kan vi hitta uppskattade underträdskostnader för hashen och tillämpa kopplingsalternativ med hjälp av tips:
-- HashSELECT SOH.SubTotalFROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123OPTION (HASH JOIN, MAXDOP );

-- ApplySELECT SOH.SubTotalFROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD PÅ SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123OPTION (LOOP JOIN, MAXDOP );
Detta ger oss en poäng på linjen för varje kopplingstyp:
- 31 465 rader
- Hashkostnad 1,05083
- Ansökan kostar 10,0552
Den andra punkten på linjen
Eftersom det uppskattade antalet rader är mer än 100 kommer de andra referenspunkterna från speciella interna uppskattningar baserade på en sammanfogningsinmatningsrad. Tyvärr finns det inget enkelt sätt att få de exakta kostnadssiffrorna för denna interna beräkning (jag kommer att prata mer om detta inom kort).
Tills vidare ska jag bara visa dig kostnadssiffrorna (med den fulla interna precisionen snarare än de sex signifikanta siffrorna som presenteras i utförandeplanerna):
- En rad (intern beräkning)
- Hashkostnad 0,999027422729
- Ange kostnad 0,547927305023
- 31 465 rader
- Hash-kostnad 1,05082787359
- Ansökan kostar 10,0552890166
Som förväntat är appliceringsanslutningen billigare än hashen för en liten indatakardinalitet men mycket dyrare för den förväntade kardinaliteten på 31 465 rader.
Skärningsberäkningen
Att koppla in dessa kardinalitets- och kostnadssiffror i linjeskärningsformeln ger dig följande:
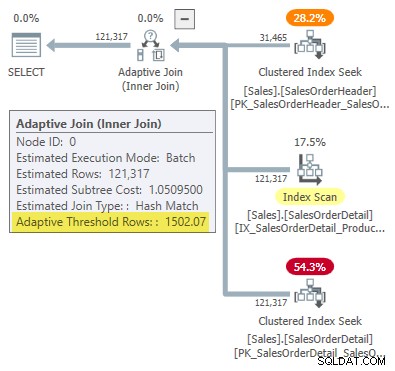
-- Hashpoäng (x =kardinalitet; y =kostnad) DEKLARE @x1 float =1, @y1 float =0,999027422729, @x2 float =31465, @y2 float =1,05082787359; -- Tillämpa poäng (x =kardinalitet; y =kostnad) DECLARE @x3 float =1, @y3 float =0,547927305023, @x4 float =31465, @y4 float =10,0552890166; -- Formel:VÄLJ tröskel =( (@x1 * @y2 - @y1 * @x2) * (@x3 - @x4) - (@x1 - @x2) * (@x3 * @y4 - @y3 * @x4) ) ) / ( (@x1 - @x2) * (@y3 - @y4) - (@y1 - @y2) * (@x3 - @x4) ); -- Returnerar 1502.06521571273
Avrundat till sex signifikanta siffror matchar detta resultat 1502.07 rader som visas i den adaptiva sammanfogningsplanen:
Defekt eller design?
Kom ihåg att SQL Server behöver fyra punkter för att "rita" radantalet mot kostnadslinjerna för att hitta den adaptiva anslutningströskeln. I det aktuella fallet innebär detta att man hittar kostnadsuppskattningar för kardinaliteterna med en rad och 31 465 rader för både applicerings- och hash-join-implementeringar.
Optimeraren anropar en rutin som heter sqllang!CuNewJoinEstimate för att beräkna dessa fyra kostnader för en adaptiv sammanfogning. Tyvärr finns det inga spårflaggor eller utökade händelser för att ge en praktisk översikt över denna aktivitet. De normala spårningsflaggor som används för att undersöka optimerarens beteende och visningskostnader fungerar inte här (se bilagan om du är intresserad av mer information).
Det enda sättet att få en rad kostnadsuppskattningar är att bifoga en debugger och ställa in en brytpunkt efter det fjärde anropet till CuNewJoinEstimate i koden för sqllang!CardSolveForSwitch . Jag använde WinDbg för att få den här anropsstacken på SQL Server 2019 CU12:

Vid denna punkt i koden lagras flyttalskostnader med dubbel precision på fyra minnesplatser som pekas på av adresser vid rsp+b0 , rsp+d0 , rsp+30 och rsp+28 (där rsp är ett CPU-register och offset är hexadecimalt):

Operatörens underträdskostnadsnummer som visas matchar de som används i den adaptiva sammanfogningströskelberäkningsformeln.
Om dessa kostnadsuppskattningar på en rad
Du kanske har märkt att de uppskattade underträdskostnaderna för sammanfogningar på en rad verkar ganska höga för det arbete som är involverat i att sammanfoga en rad:
- En rad
- Hashkostnad 0,999027422729
- Ange kostnad 0,547927305023
Om du försöker skapa enrads exekveringsplaner för hash-join och tillämpa exempel, kommer du att se mycket lägre uppskattade underträdskostnader vid sammanfogningen än de som visas ovan. På samma sätt kommer att köra den ursprungliga frågan med ett radmål på en (eller antalet sammanfogade utdatarader som förväntas för en inmatning av en rad) också producera en beräknad kostnad sätt lägre än vad som visas.
Anledningen är CuNewJoinEstimate rutin uppskattar enrads fall på ett sätt som jag tror att de flesta människor inte skulle tycka är intuitiva.
Den slutliga kostnaden består av tre huvudkomponenter:
- Kostnaden för byggindataunderträdet
- Den lokala kostnaden för anslutningen
- Sondens indatasubträdskostnad
Punkterna 2 och 3 beror på typen av sammanfogning. För en hash-koppling står de för kostnaden för att läsa alla rader från sondens indata, matcha dem (eller inte) med den ena raden i hashtabellen och skicka resultaten vidare till nästa operatör. För en ansökan täcker kostnaderna en sökning på den lägre ingången till sammanfogningen, den interna kostnaden för själva sammanfogningen och att returnera de matchade raderna till den överordnade operatören.
Inget av detta är ovanligt eller överraskande.
Kostnadsöverraskningen
Överraskningen kommer på byggsidan av sammanfogningen (punkt 1 i listan). Man kan förvänta sig att optimeraren gör några snygga beräkningar för att skala den redan beräknade subträdkostnaden för 31 465 rader ner till en genomsnittlig rad, eller något liknande.
Faktum är att både hash- och appliceringsuppskattningar för sammanfogning på en rad använder helt enkelt hela underträdskostnaden för originalet kardinalitetsuppskattning på 31 465 rader. I vårt pågående exempel är detta "underträd" 0,54456 kostnad för batchläges klustrade indexsökning i rubriktabellen:
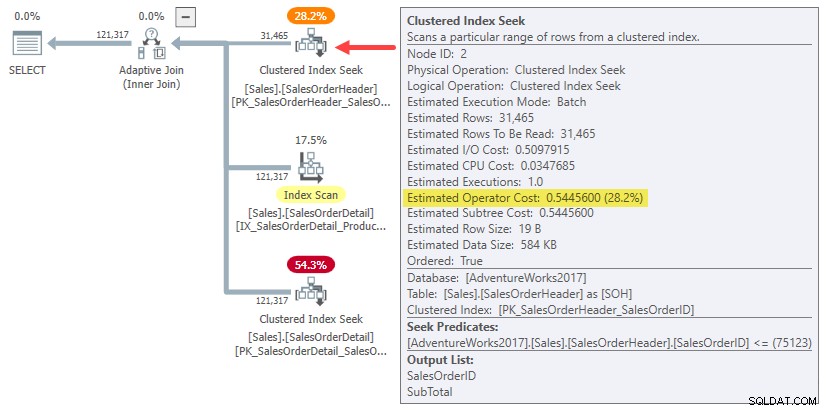
För att vara tydlig:de beräknade kostnaderna på byggsidan för alternativen med en rad sammanfogning använder en insatskostnad som beräknas för 31 465 rader. Det borde verka lite konstigt.
Som en påminnelse, kostnaderna för en rad beräknade av CuNewJoinEstimate var följande:
- En rad
- Hashkostnad 0,999027422729
- Ange kostnad 0,547927305023
Du kan se att den totala appliceringskostnaden (~0,54793) domineras av 0,54456 kostnad för byggsidan av underträdet, med ett litet extra belopp för den enda inre sökningen, bearbetning av det lilla antalet resulterande rader inom kopplingen och vidarebefordrar dem till den överordnade operatören.
Den uppskattade en-rads hash join-kostnaden är högre eftersom sondsidan av planen består av en fullständig indexskanning, där alla resulterande rader måste passera genom joinen. Den totala kostnaden för en rad hash-join är lite lägre än den ursprungliga kostnaden på 1,05095 för exemplet med 31 465 rader eftersom det nu bara finns en rad i hashtabellen.
Konsekvenser
Man skulle förvänta sig att en uppskattning av en rad sammanfogning delvis skulle baseras på kostnaden för att leverera en rad till ingången för drivande sammanfogning. Som vi har sett är detta inte fallet för en adaptiv sammanfogning:både applicerings- och hash-alternativ är belastade med den fulla beräknade kostnaden för 31 465 rader. Resten av kopplingen kostar ungefär som man kan förvänta sig för en enradsbyggd input.
Detta intuitivt konstiga arrangemang är varför det är svårt (kanske omöjligt) att visa en utförandeplan som speglar de beräknade kostnaderna. Vi skulle behöva konstruera en plan som levererar 31 465 rader till den övre sammanfogningsinmatningen men kostar själva sammanfogningen och dess inre input som om bara en rad fanns. En svår fråga.
Effekten av allt detta är att höja punkten längst till vänster på vårt skärande linjediagram uppför y-axeln. Detta påverkar linjens lutning och därmed skärningspunkten.
En annan praktisk effekt är att den beräknade tröskeln för adaptiv sammanfogning nu beror på den ursprungliga kardinalitetsuppskattningen vid hash-buildingången, som noterades av Joe Obbish i sitt blogginlägg från 2017. Om vi till exempel ändrar WHERE klausul i testfrågan till SOH.SalesOrderID <= 55000 , den adaptiva tröskeln minskar från 1502.07 till 1259.8 utan att ändra frågeplanens hash. Samma plan, annan tröskel.
Detta beror på att, som vi har sett, den interna kostnadsuppskattningen på en rad beror på insatskostnaden för tillverkning för den ursprungliga kardinalitetsuppskattningen. Detta innebär att olika initiala uppskattningar på byggsidan ger en annan "boost" på y-axeln till uppskattningen på en rad. I sin tur kommer linjen att ha en annan lutning och en annan skärningspunkt.
Intuition skulle föreslå att enradsuppskattningen för samma sammanfogning alltid ska ge samma värde oavsett den andra kardinalitetsuppskattningen på linjen (förutsatt att exakt samma sammanfogning med samma egenskaper och radstorlekar har ett nära linjärt samband mellan körning rader och kostnad). Detta är inte fallet för en adaptiv koppling.
Genom design?
Jag kan med viss tillförsikt berätta för dig vad SQL Server gör vid beräkning av den adaptiva kopplingströskeln. Jag har ingen speciell insikt om varför det gör det på det här sättet.
Ändå finns det några skäl att tro att detta arrangemang är avsiktligt och kom till efter vederbörlig övervägande och feedback från tester. Resten av detta avsnitt täcker några av mina tankar om denna aspekt.
En adaptiv koppling är inte ett rakt val mellan en normal applicerings- och batch-hash-koppling. En adaptiv koppling börjar alltid med att fylla hashtabellen helt. Först när detta arbete är slutfört fattas beslutet om att byta till en tillämpningsimplementering eller inte.
Vid det här laget har vi redan ådragit oss potentiellt betydande kostnader genom att fylla i och partitionera hash-join i minnet. Detta kanske inte spelar så stor roll för fallet med en rad, men det blir allt viktigare när kardinaliteten ökar. Den oväntade "boosten" kan vara ett sätt att införliva dessa realiteter i beräkningen samtidigt som man behåller en rimlig beräkningskostnad.
SQL Server-kostnadsmodellen har länge varit lite partisk mot kapslade slingor, förmodligen med en viss motivering. Till och med det ideala indexerade appliceringsfallet kan vara långsamt i praktiken om den data som behövs inte redan finns i minnet och I/O-undersystemet inte blinkar, särskilt med ett något slumpmässigt åtkomstmönster. Begränsade mängder minne och trög I/O kommer till exempel inte att vara helt främmande för användare av lägre molnbaserade databasmotorer.
Det är möjligt att praktiska tester i sådana miljöer avslöjade att en intuitivt kostnadsbelagd adaptiv koppling var för snabb för att övergå till en applicering. Teori är ibland bara bra i teorin.
Ändå är den nuvarande situationen inte idealisk; cachelagring av en plan baserad på en ovanligt låg kardinalitetsuppskattning kommer att producera en adaptiv koppling som är mycket mer ovillig att byta till en applicering än vad det skulle ha varit med en större initial uppskattning. Detta är en variation av parameterkänslighetsproblemet, men det kommer att vara ett nytt övervägande av denna typ för många av oss.
Nu är det också möjligt att använda den fullständiga ingångskostnaden för underträdet för punkten längst till vänster av de skärande kostnadslinjerna är helt enkelt ett okorrigerat fel eller förbiseende. Min känsla är att den nuvarande implementeringen förmodligen är en avsiktlig praktisk kompromiss, men du skulle behöva någon med tillgång till designdokumenten och källkoden för att veta säkert.
Sammanfattning
En adaptiv koppling gör att SQL Server kan övergå från en hashkoppling i batchläge till en applicering efter att hashtabellen har fyllts i helt. Den fattar detta beslut genom att jämföra antalet rader i hashtabellen med en förberäknad adaptiv tröskel.
Tröskeln beräknas genom att förutsäga var applicerings- och hashanslutningskostnaderna är lika. För att hitta den här punkten producerar SQL Server en andra intern kostnadsuppskattning för en annan indatakardinalitet – normalt en rad.
Överraskande nog inkluderar den uppskattade kostnaden för enradsuppskattningen den fullständiga kostnaden för underträdet på byggsidan för den ursprungliga kardinalitetsuppskattningen (inte skalad till en rad). Detta innebär att tröskelvärdet beror på den ursprungliga kardinalitetsuppskattningen vid byggingången.
Följaktligen kan en adaptiv koppling ha ett oväntat lågt tröskelvärde, vilket innebär att den adaptiva kopplingen är mycket mindre sannolikt att övergå från en hash-join. Det är oklart om detta beteende är designat.
Relaterad läsning
- Vi presenterar Batch Mode Adaptive Joins av Joe Sack
- Förstå Adaptive Joins i produktdokumentationen
- Adaptive Join Internals av Dima Pilugin
- Hur fungerar Batch Mode Adaptive Joins? på Databas Administrators Stack Exchange av Erik Darling
- An Adaptive Join Regression av Joe Obbish
- Om du vill ha adaptiva kopplingar behöver du bredare index och är större bättre? av Erik Darling
- Parameter Sniffing:Adaptive Joins av Brent Ozar
- Intelligent frågebehandling av frågor och svar av Joe Sack
Bilaga
Det här avsnittet täcker ett par adaptiva sammanfogningsaspekter som var svåra att ta med i huvudtexten på ett naturligt sätt.
Den utökade adaptiva planen
Du kan prova att titta på en visuell representation av den interna planen med hjälp av odokumenterad spårningsflagga 9415, som tillhandahålls av Dima Pilugin i hans utmärkta adaptiva sammanfogningsinterna artikel länkad ovan. Med denna flagga aktiv blir den adaptiva kopplingsplanen för vårt körexempel följande:
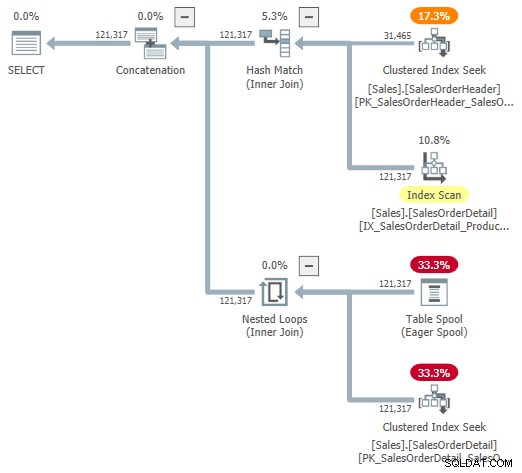
Detta är en användbar representation för att underlätta förståelsen, men den är inte helt korrekt, fullständig eller konsekvent. Till exempel existerar inte tabellrullen – den är en standardrepresentation för den adaptiva buffertläsaren läser rader direkt från hashtabellen för batchläge.
Operatörens egenskaper och kardinalitetsuppskattningar är också lite överallt. Utdata från den adaptiva buffertläsaren ("spool") bör vara 31 465 rader, inte 121 317. Underträdskostnaden för ansökan är felaktigt begränsad av moderoperatörskostnaden. Detta är normalt för showplan, men det är ingen mening i ett adaptivt sammanfogningssammanhang.
Det finns också andra inkonsekvenser - för många för att kunna listas - men det kan hända med odokumenterade spårningsflaggor. Den utökade planen som visas ovan är inte avsedd att användas av slutanvändare, så det kanske inte är helt förvånande. Budskapet här är att inte förlita sig för mycket på siffrorna och egenskaperna som visas i denna odokumenterade form.
Jag bör också i förbigående nämna att den färdiga standardoperatören för adaptiv anslutningsplan inte är helt utan sina egna konsekvensproblem. Dessa härrör i stort sett uteslutande från de dolda detaljerna.
Till exempel kommer de visade adaptiva sammanfogningsegenskaperna från en blandning av de underliggande Concat , Hash Join och Ansök operatörer. Du kan se en adaptiv sammanfogningsrapportering som körs i batchläge för kapslade loopar (vilket är omöjligt), och den förflutna tiden som visas kopieras faktiskt från den dolda Concat , inte den specifika join som kördes vid körning.
De vanliga misstänkta
Vi kan få lite användbar information från de typer av odokumenterade spårningsflaggor som normalt används för att titta på optimeringsutdata. Till exempel:
VÄLJ SOH.SubTotalFROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123OPTION ( QUERYTRACEON 3604, QUERY QUERYON, 86207CEON, 86207 QUERY ON);Utdata (mycket redigerad för läsbarhet):
*** Utdataträd:***
PhyOp_ExecutionModeAdapter(BatchToRow) Card=121317 Kostnad=1,05095
- PhyOp_Concat (batch) Card=121317 Kostnad=1,05325
- PhyOp_HashJoinx_jtInner (batch) Card=121317 Kostnad=1,05083
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Cost=0,54456
- PhyOp_Filter(batch) Card=121317 Kostnad=0,397185
- PhyOp_Range Sales.SalesOrderDetail Card=121317 Cost=0,338953
- PhyOp_ExecutionModeAdapter(RowToBatch) Card=121317 Kostnad=10,0798
- PhyOp_Apply Card=121317 Cost=10,0553
- PhyOp_ExecutionModeAdapter(BatchTRow) Card=31465 Cost=0,544623
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Cost=0,54456 [** 3 **]
- PhyOp_Filter Card=3,85562 Cost=9,00356
- PhyOp_Range Sales.SalesOrderDetail Card=3,85562 Cost=8,94533
- PhyOp_ExecutionModeAdapter(BatchTRow) Card=31465 Cost=0,544623
- PhyOp_Apply Card=121317 Cost=10,0553
Detta ger en viss inblick i de uppskattade kostnaderna för fullkardinalitetsfallet med hash och tillämpa alternativ utan att skriva separata frågor och använda tips. Som nämnts i huvudtexten är dessa spårningsflaggor inte effektiva inom CuNewJoinEstimate , så vi kan inte direkt se de upprepade beräkningarna för fallet med 31 465 rader eller någon av detaljerna för enradsuppskattningarna på detta sätt.
Slå samman Join och Row Mode Hash Join
Adaptiva anslutningar erbjuder endast en övergång från batch-läge hash-join till radläge gäller. För skälen till varför radläges-hashjoin inte stöds, se Intelligent Query Processing Q&A i avsnittet Relaterad läsning. Kort sagt, det är tänkt att radlägeshash-kopplingar skulle vara för benägna att prestandaregressioner.
Att byta till ett radlägessammanfogning skulle vara ett annat alternativ, men optimeraren överväger för närvarande inte detta. Som jag förstår det är det osannolikt att det kommer att utökas i den här riktningen i framtiden.
Några av övervägandena är desamma som de är för radläges hash join. Dessutom tenderar merge join-planer att vara mindre lätta att utbyta med hash join, även om vi begränsar oss till indexerad merge join (ingen explicit sortering).
Det finns också en mycket större skillnad mellan hash och applicera än det är mellan hash och merge. Både hash och merge lämpar sig för större ingångar, och app lämpar sig bättre för en mindre köringång. Merge-join är inte lika lätt att parallellisera som hash-join och skalas inte lika bra med ökande trådantal.
Med tanke på motivationen för adaptiva kopplingar är att hantera bättre avsevärt varierande inmatningsstorlekar – och endast hash join stöder batchlägesbearbetning – valet av batchhash kontra radtillämpning är det mer naturliga. Slutligen, att ha tre adaptiva sammanfogningsval skulle avsevärt komplicera tröskelberäkningen för potentiellt liten vinst.