Den här artikeln är den andra i en serie om T-SQL-buggar, fallgropar och bästa praxis. Den här gången fokuserar jag på klassiska buggar som involverar delfrågor. Särskilt täcker jag substitutionsfel och logiska problem med tre värden. Flera av de ämnen som jag tar upp i serien föreslogs av andra MVP:er i en diskussion vi hade om ämnet. Tack till Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man och Paul White för era förslag!
Ersättningsfel
För att visa det klassiska ersättningsfelet använder jag ett enkelt scenario för kundorder. Kör följande kod för att skapa en hjälpfunktion som heter GetNums, och för att skapa och fylla i tabellerna Kunder och Beställningar:
SET NOCOUNT ON;
USE tempdb;
GO
DROP TABLE IF EXISTS dbo.Orders;
DROP TABLE IF EXISTS dbo.Customers;
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
CREATE TABLE dbo.Customers
(
custid INT NOT NULL
CONSTRAINT PK_Customers PRIMARY KEY,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100);
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
customerid INT NOT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (customerid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_customerid ON dbo.Orders(customerid); För närvarande har tabellen Kunder 100 kunder med på varandra följande kund-ID:n i intervallet 1 till 100. 98 av dessa kunder har motsvarande order i tabellen Order. Kunder med ID 17 och 59 har inte lagt några beställningar ännu och har därför ingen närvaro i beställningstabellen.
Du är bara ute efter kunder som har lagt beställningar, och du försöker uppnå detta med följande fråga (kalla det Fråga 1):
SET NOCOUNT OFF; SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT custid FROM dbo.Orders);
Du ska få tillbaka 98 kunder, men istället får du alla 100 kunder, inklusive de med ID 17 och 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 17 Cust 17 18 Cust 18 ... 58 Cust 58 59 Cust 59 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (100 rows affected)
Kan du ta reda på vad som är fel?
För att öka förvirringen, granska planen för fråga 1 som visas i figur 1.
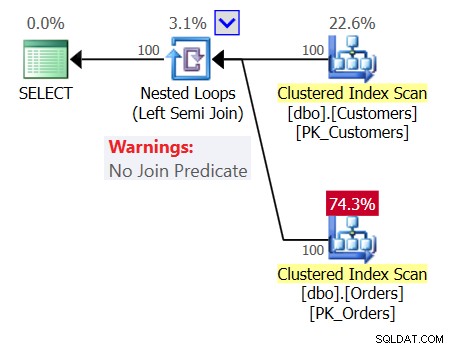 Figur 1:Plan för fråga 1
Figur 1:Plan för fråga 1
Planen visar en Nested Loops (Left Semi Join)-operatör utan join-predikat, vilket betyder att det enda villkoret för att returnera en kund är att ha en icke-tom ordertabell, som om frågan du skrev var följande:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Du förväntade dig förmodligen en plan liknande den som visas i figur 2.
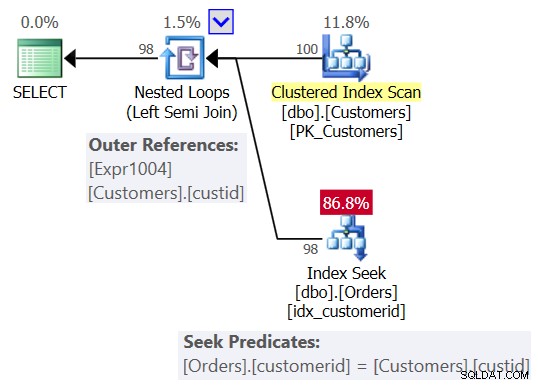 Figur 2:Förväntad plan för fråga 1
Figur 2:Förväntad plan för fråga 1
I den här planen ser du en kapslade loopar (vänster semijoin) operatör, med en skanning av det klustrade indexet på kunder som den yttre ingången och en sökning i indexet på kund-id-kolumnen i beställningarna som den inre ingången. Du ser också en yttre referens (korrelerad parameter) baserad på kundkolumnen i Kunder, och sökpredikatet Orders.customerid =Customers.custid.
Så varför får du planen i figur 1 och inte den i figur 2? Om du inte har listat ut det ännu, titta noga på definitionerna av båda tabellerna – särskilt kolumnnamnen – och på kolumnnamnen som används i frågan. Du kommer att märka att tabellen Kunder innehåller kund-ID:n i en kolumn som kallas custid, och att tabellen Order innehåller kund-ID:n i en kolumn som heter kund-ID. Koden använder dock custid i både de yttre och inre frågorna. Eftersom referensen till custid i den inre frågan är okvalificerad, måste SQL Server avgöra vilken tabell kolumnen kommer från. Enligt SQL-standarden är det meningen att SQL Server ska leta efter kolumnen i tabellen som efterfrågas i samma omfattning först, men eftersom det inte finns någon kolumn som heter custid i Orders, ska den sedan leta efter den i tabellen i den yttre omfattning, och den här gången finns det en matchning. Så oavsiktligt blir referensen till custid implicit en korrelerad referens, som om du skrev följande fråga:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT Customers.custid FROM dbo.Orders);
Förutsatt att Orders inte är tomma och att det yttre custid-värdet inte är NULL (kan inte vara det i vårt fall eftersom kolumnen är definierad som NOT NULL), får du alltid en matchning eftersom du jämför värdet med sig själv . Så fråga 1 blir motsvarigheten till:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Om den yttre tabellen stödde NULLs i custid-kolumnen, skulle fråga 1 ha motsvarat:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders) AND custid IS NOT NULL;
Nu förstår du varför fråga 1 optimerades med planen i figur 1, och varför du fick tillbaka alla 100 kunder.
För en tid sedan besökte jag en kund som hade en liknande bugg, men tyvärr med ett DELETE-meddelande. Fundera ett ögonblick vad detta betyder. Alla tabellrader raderades och inte bara de som de ursprungligen hade för avsikt att ta bort!
När det gäller bästa praxis som kan hjälpa dig att undvika sådana buggar, finns det två huvudsakliga. Först, så mycket du kan kontrollera det, se till att du använder konsekventa kolumnnamn över tabeller för attribut som representerar samma sak. För det andra, se till att du tabeller kvalificerade kolumnreferenser i underfrågor, inklusive i fristående sådana där detta inte är en vanlig praxis. Naturligtvis kan du använda tabellalias om du hellre inte vill använda fullständiga tabellnamn. Om du tillämpar denna praxis på vår fråga, anta att ditt första försök använde följande kod:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.custid FROM dbo.Orders AS O);
Här tillåter du inte implicit upplösning av kolumnnamn och därför genererar SQL Server följande fel:
Msg 207, Level 16, State 1, Line 108 Invalid column name 'custid'.
Du går och kontrollerar metadata för tabellen Order, inser att du använde fel kolumnnamn och fixar frågan (kalla denna fråga 2), så här:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.customerid FROM dbo.Orders AS O);
Den här gången får du rätt resultat med 98 kunder, exklusive kunderna med ID 17 och 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 18 Cust 18 .. 58 Cust 58 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (98 rows affected)
Du får också den förväntade planen som visas tidigare i figur 2.
Dessutom är det tydligt varför Customers.custid är en yttre referens (korrelerad parameter) i operatören Nested Loops (Left Semi Join) i figur 2. Vad som är mindre uppenbart är varför Expr1004 också visas i planen som en yttre referens. Fellow SQL Server MVP Paul White teoretiserar att det kan vara relaterat till att använda information från den yttre ingångens blad för att antyda lagringsmotorn för att undvika dubbla ansträngningar av läs-framåt-mekanismerna. Du hittar detaljerna här.
Logikproblem med tre värden
En vanlig bugg som involverar underfrågor har att göra med fall där den yttre frågan använder NOT IN-predikatet och underfrågan potentiellt kan returnera NULLs bland sina värden. Anta till exempel att du behöver kunna lagra beställningar i vår ordertabell med en NULL som kund-ID. Ett sådant fall skulle representera en order som inte är associerad med någon kund; till exempel en order som kompenserar för inkonsekvenser mellan faktiska produktantal och antal registrerade i databasen.
Använd följande kod för att återskapa ordertabellen med custid-kolumnen som tillåter NULL, och för tillfället fylla i den med samma exempeldata som tidigare (med order efter kund-ID 1 till 100, exklusive 17 och 59):
DROP TABLE IF EXISTS dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
custid INT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (custid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_custid ON dbo.Orders(custid); Lägg märke till att medan vi håller på så följde jag den bästa praxis som diskuterades i föregående avsnitt för att använda konsekventa kolumnnamn över tabeller för samma attribut, och namngav kolumnen i ordertabellen custid precis som i tabellen Kunder.
Anta att du behöver skriva en fråga som returnerar kunder som inte har lagt beställningar. Du kommer på följande förenklade lösning med NOT IN-predikatet (kalla det fråga 3, första exekvering):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Den här frågan returnerar den förväntade utdata med kunder 17 och 59:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
En inventering görs i företagets lager, och en inkonsekvens hittas mellan den faktiska kvantiteten av en produkt och den mängd som registreras i databasen. Så du lägger till en dummy-kompensationsorder för att ta hänsyn till inkonsekvensen. Eftersom det inte finns någon faktisk kund kopplad till beställningen använder du en NULL som kund-ID. Kör följande kod för att lägga till en sådan orderhuvud:
INSERT INTO dbo.Orders(custid) VALUES(NULL);
Kör fråga 3 för andra gången:
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Den här gången får du ett tomt resultat:
custid companyname ------- ------------ (0 rows affected)
Det är klart att något är fel. Du vet att kunder 17 och 59 inte gjorde några beställningar, och de visas faktiskt i tabellen Kunder men inte i tabellen Beställningar. Ändå hävdar frågeresultatet att det inte finns någon kund som inte har lagt några beställningar. Kan du ta reda på var felet finns och hur man fixar det?
Felet har förstås att göra med NULL i ordertabellen. För att SQL är en NULL en markör för ett saknat värde som kan representera en tillämplig kund. SQL vet inte att NULL för oss representerar en saknad och otillämplig (irrelevant) kund. För alla kunder i tabellen Kunder som finns i tabellen Order hittar IN-predikatet en matchning som ger TRUE och INTE IN-delen gör den till FALSK, därför kasseras kundraden. Än så länge är allt bra. Men för kunder 17 och 59 ger IN-predikatet OKÄNT eftersom alla jämförelser med icke-NULL-värden ger FALSE, och jämförelsen med NULL ger OKÄNT. Kom ihåg att SQL antar att NULL kan representera vilken tillämplig kund som helst, så det logiska värdet UNKNOWN indikerar att det är okänt om det yttre kund-ID:t är lika med det inre NULL-kund-ID:t. FALSK ELLER FALSK ... ELLER OKÄNT är OKÄNT. Då den NOT IN-delen som tillämpas på UNKNOWN ger fortfarande UNKNOWN.
I enklare engelska termer bad du att få returnera kunder som inte lagt beställningar. Så naturligtvis kasserar frågan alla kunder från tabellen Kunder som finns i tabellen Order eftersom det är känt med säkerhet att de har lagt beställningar. När det gäller resten (17 och 59 i vårt fall) förkastar frågan dem sedan till SQL, precis som det är okänt om de har lagt beställningar, det är lika okänt om de inte har lagt beställningar, och filtret behöver säkerhet (TRUE) i för att returnera en rad. Vilken pickle!
Så så fort den första NULL kommer in i ordertabellen, från det ögonblicket får du alltid ett tomt resultat tillbaka från NOT IN-frågan. Hur är det med fall där du faktiskt inte har NULLs i data, men kolumnen tillåter NULLs? Som du såg i den första körningen av fråga 3, får du i ett sådant fall rätt resultat. Du kanske tänker att applikationen aldrig kommer att införa NULLs i data, så det finns inget för dig att oroa dig för. Det är en dålig praxis av ett par anledningar. För det första, om en kolumn definieras som att tillåta NULLs, är det ganska säkert att NULLs så småningom kommer att nå dit även om de inte är tänkta; det är bara en tidsfråga. Det kan vara resultatet av import av dålig data, en bugg i applikationen och andra orsaker. För en annan, även om data inte innehåller NULLs, om kolumnen tillåter dessa, måste optimeraren ta hänsyn till möjligheten att NULLs kommer att finnas när den skapar frågeplanen, och i vår NOT IN-fråga medför detta en prestationsstraff . För att visa detta, överväg planen för den första exekveringen av fråga 3 innan du lade till raden med NULL, som visas i figur 3.
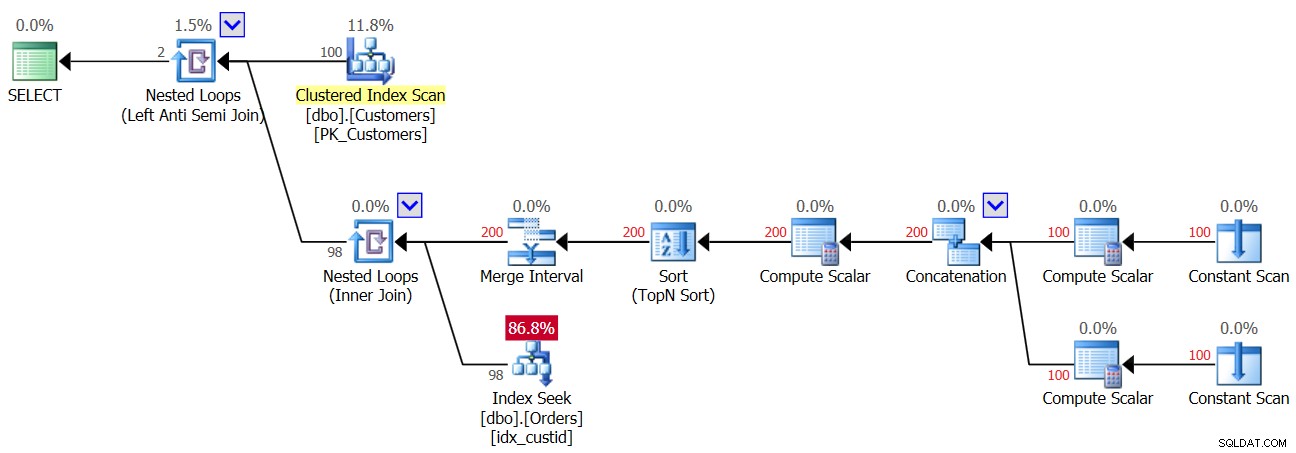 Figur 3:Plan för första exekvering av fråga 3
Figur 3:Plan för första exekvering av fråga 3
Den översta operatören för kapslade slingor hanterar Left Anti Semi Join-logiken. Det handlar i huvudsak om att identifiera icke-matchningar och kortsluta den inre aktiviteten så snart en matchning hittas. Den yttre delen av slingan drar alla 100 kunder från Kundtabellen, därför exekveras den inre delen av slingan 100 gånger.
Den inre delen av den övre slingan kör en operatör för kapslade loopar (Inner Join). Den yttre delen av den nedre slingan skapar två rader per kund – en för ett NULL-fall och en annan för det aktuella kund-ID, i denna ordning. Låt inte operatören Merge Interval förvirra dig. Det används normalt för att slå samman överlappande intervall, t.ex. ett predikat som col1 MELLAN 20 OCH 30 ELLER col1 MELLAN 25 OCH 35 konverteras till col1 MELLAN 20 OCH 35. Denna idé kan generaliseras för att ta bort dubbletter i ett IN-predikat. I vårt fall kan det egentligen inte bli några dubbletter. I förenklade termer, som nämnts, tänk på den yttre delen av slingan som att skapa två rader per kund – den första för ett NULL-fall och den andra för det aktuella kund-ID. Då gör den inre delen av slingan först en sökning i indexet idx_custid på Orders för att leta efter en NULL. Om en NULL hittas, aktiverar den inte den andra sökningen för det aktuella kund-ID (kom ihåg kortslutningen som hanteras av den övre Anti Semi Join-slingan). I ett sådant fall kasseras den yttre kunden. Men om en NULL inte hittas, aktiverar den nedre slingan en andra sökning för att leta efter det aktuella kund-ID i beställningar. Om den hittas kasseras den yttre kunden. Om den inte hittas returneras den yttre kunden. Vad detta betyder är att när NULLs inte finns i order, utför denna plan två sökningar per kund! Detta kan observeras i planen som antalet rader 200 i den yttre ingången av bottenslingan. Följaktligen, här är I/O-statistiken som rapporteras för den första körningen:
Table 'Orders'. Scan count 200, logical reads 603
Planen för den andra exekveringen av fråga 3, efter att en rad med en NULL lagts till i ordertabellen, visas i figur 4.
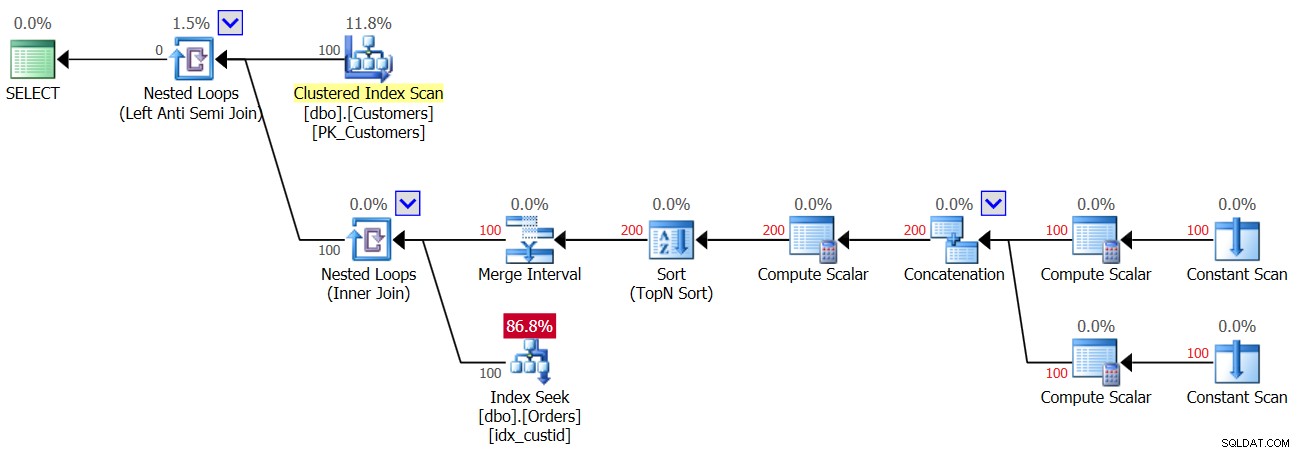 Figur 4:Plan för andra exekvering av fråga 3
Figur 4:Plan för andra exekvering av fråga 3
Eftersom en NULL finns i tabellen, för alla kunder, hittar den första exekveringen av Index Seek-operatören en matchning, och därför kasseras alla kunder. Så jaja, vi gör bara en sökning per kund och inte två, så den här gången får du 100 sökningar och inte 200; men samtidigt betyder det att du får tillbaka ett tomt resultat!
Här är I/O-statistiken som rapporteras för den andra körningen:
Table 'Orders'. Scan count 100, logical reads 300
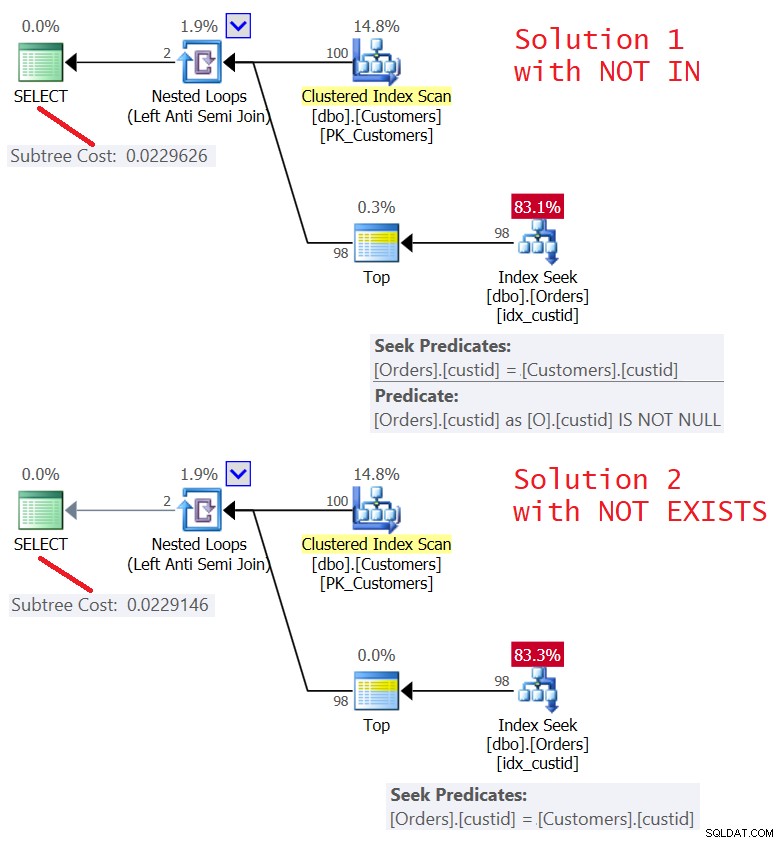
En lösning på denna uppgift när NULL-värden är möjliga bland de returnerade värdena i underfrågan är att helt enkelt filtrera bort dem, som så (kalla det lösning 1/fråga 4):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O WHERE O.custid IS NOT NULL);
Denna kod genererar den förväntade utdata:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Nackdelen med denna lösning är att du måste komma ihåg att lägga till filtret. Jag föredrar en lösning som använder NOT EXISTS-predikatet, där underfrågan har en explicit korrelation som jämför beställningens kund-ID med kundens kund-ID, som så (kalla det Lösning 2/Fråga 5):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE NOT EXISTS (SELECT * FROM dbo.Orders AS O WHERE O.custid = C.custid);
Kom ihåg att en jämlikhetsbaserad jämförelse mellan en NULL och vad som helst ger OKÄNT, och OKÄNT kasseras av ett WHERE-filter. Så om NULL finns i order, elimineras de av den inre frågans filter utan att du behöver lägga till explicit NULL-behandling, och därför behöver du inte oroa dig för om NULL finns eller inte finns i data.
Den här frågan genererar den förväntade utdata:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Planerna för båda lösningarna visas i figur 5.
 Figur 5:Planer för fråga 4 (lösning 1) och fråga 5 (lösning 2) )
Figur 5:Planer för fråga 4 (lösning 1) och fråga 5 (lösning 2) )
Som ni kan se är planerna nästan identiska. De är också ganska effektiva, med en Left Semi Join-optimering med en kortslutning. Båda utför endast 100 sökningar i indexet idx_custid på order, och med Top-operatorn, applicerar en kortslutning efter att en rad har berörts i bladet.
I/O-statistiken för båda frågorna är densamma:
Table 'Orders'. Scan count 100, logical reads 348
En sak att tänka på är dock om det finns någon chans för den yttre tabellen att ha NULLs i den korrelerade kolumnen (custid i vårt fall). Mycket osannolikt att vara relevant i ett scenario som kundorder, men kan vara relevant i andra scenarier. Om så verkligen är fallet, hanterar båda lösningarna en yttre NULL felaktigt.
För att demonstrera detta, släpp och återskapa Kundtabellen med en NULL som ett av kund-ID:n genom att köra följande kod:
DROP TABLE IF EXISTS dbo.Customers;
GO
CREATE TABLE dbo.Customers
(
custid INT NULL
CONSTRAINT UNQ_Customers_custid UNIQUE CLUSTERED,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT CAST(NULL AS INT) AS custid, 'Cust NULL' AS companyname
UNION ALL
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100); Lösning 1 kommer inte att returnera en yttre NULL, oavsett om en inre NULL finns eller inte.
Lösning 2 kommer att returnera en yttre NULL oavsett om en inre NULL finns eller inte.
Om du vill hantera NULLs som du hanterar icke-NULL-värden, d.v.s. returnera NULL om det finns i kunder men inte i order, och inte returnera det om det finns i båda, måste du ändra lösningens logik för att använda en distinkthet -baserad jämförelse istället för en jämställdhetsbaserad jämförelse. Detta kan uppnås genom att kombinera EXISTS-predikatet och EXCEPT set-operatorn, på samma sätt (kalla den här lösningen 3/fråga 6):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Eftersom det för närvarande finns NULL i både kunder och beställningar, returnerar denna fråga korrekt inte NULL. Här är frågeutgången:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Kör följande kod för att ta bort raden med NULL från ordertabellen och kör lösning 3 igen:
DELETE FROM dbo.Orders WHERE custid IS NULL; SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Denna gång, eftersom en NULL finns i kunder men inte i beställningar, inkluderar resultatet NULL:
custid companyname ------- ------------ NULL Cust NULL 17 Cust 17 59 Cust 59 (3 rows affected)
Planen för denna lösning visas i figur 6:
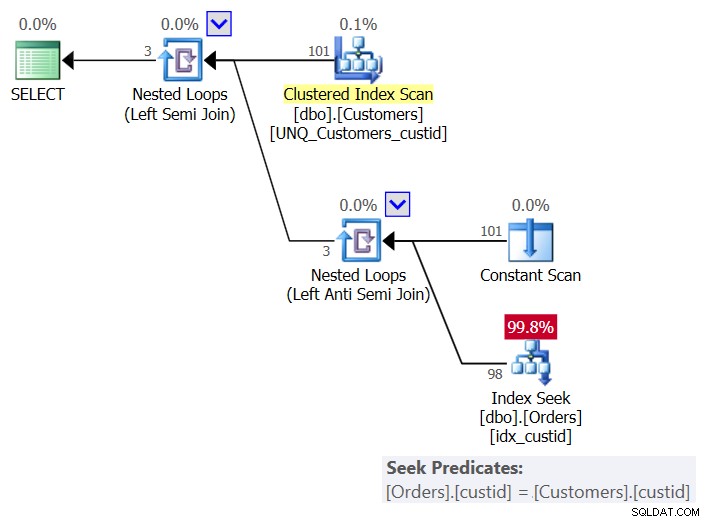 Figur 6:Plan för fråga 6 (lösning 3)
Figur 6:Plan för fråga 6 (lösning 3)
Per kund använder planen en Constant Scan-operatör för att skapa en rad med den aktuella kunden, och tillämpar en enda sökning i indexet idx_custid på Orders för att kontrollera om kunden finns i Orders. Du slutar med en sökning per kund. Eftersom vi för närvarande har 101 kunder i tabellen får vi 101 sökningar.
Här är I/O-statistiken för den här frågan:
Table 'Orders'. Scan count 101, logical reads 415
Slutsats
Den här månaden tog jag upp delfråga-relaterade buggar, fallgropar och bästa praxis. Jag täckte ersättningsfel och logiska problem med tre värden. Kom ihåg att använda konsekventa kolumnnamn över tabeller och att alltid tabellkvalificera kolumner i underfrågor, även när de är fristående. Kom också ihåg att genomdriva en NOT NULL-begränsning när kolumnen inte ska tillåta NULL, och att alltid ta hänsyn till NULL när de är möjliga i din data. Se till att du inkluderar NULLs i din exempeldata när de är tillåtna så att du lättare kan fånga buggar i din kod när du testar den. Var försiktig med NOT IN-predikatet när det kombineras med underfrågor. Om NULL är möjliga i den inre frågans resultat, är predikatet INTE FINNS vanligtvis det föredragna alternativet.