I stort sett alla datorrelaterade kolumnerrelaterade prestandaproblem som jag har stött på under åren har haft en (eller flera) av följande grundorsaker:
- Implementeringsbegränsningar
- Brist på kostnadsmodellstöd i frågeoptimeraren
- Utökning av beräknad kolumndefinition innan optimeringen startar
Ett exempel på en implementeringsbegränsning kan inte skapa ett filtrerat index på en beräknad kolumn (även när den består). Det finns inte mycket vi kan göra åt denna problemkategori; vi måste använda lösningar medan vi väntar på att produktförbättringar ska komma.
Avsaknaden av kostnadsmodellstöd för optimerare innebär att SQL Server tilldelar en liten fast kostnad för skalära beräkningar, oavsett komplexitet eller implementering. Som en följd av detta beslutar servern ofta att räkna om ett lagrat beräknat kolumnvärde istället för att läsa det kvarstående eller indexerade värdet direkt. Detta är särskilt smärtsamt när det beräknade uttrycket är dyrt, till exempel när det involverar anrop av en skalär användardefinierad funktion.
Problemen kring definitionsexpansion är lite mer involverade och har breda effekter.
Problemen med beräknad kolumnexpansion
SQL Server expanderar normalt beräknade kolumner till deras underliggande definitioner under bindningsfasen av frågenormalisering. Detta är en mycket tidig fas i frågesammanställningsprocessen, långt innan beslut om planval fattas (inklusive trivial plan).
I teorin kan en tidig expansion möjliggöra optimeringar som annars skulle missas. Till exempel kan optimeraren kunna tillämpa förenklingar givet annan information i frågan och metadata (t.ex. begränsningar). Detta är samma sorts resonemang som leder till att vydefinitioner utökas (såvida inte en NOEXPAND ledtråd används).
Senare i kompileringsprocessen (men fortfarande innan ens en trivial plan har övervägts), ser optimeraren ut att matcha tillbaka uttryck till beständiga eller indexerade beräknade kolumner. Problemet är att optimeringsaktiviteter under tiden kan ha ändrat de utökade uttrycken så att matchning inte längre är möjlig.
När detta inträffar ser den slutliga exekveringsplanen ut som om optimeraren har missat en "uppenbar" möjlighet att använda en beständig eller indexerad beräknad kolumn. Det finns få detaljer i exekveringsplaner som kan hjälpa till att fastställa orsaken, vilket gör detta till ett potentiellt frustrerande problem att felsöka och åtgärda.
Matcha uttryck med beräknade kolumner
Det är värt att vara särskilt tydlig att det finns två separata processer här:
- Tidig expansion av beräknade kolumner; och
- Senare försök att matcha uttryck till beräknade kolumner.
Observera särskilt att alla frågeuttryck kan matchas till en lämplig beräknad kolumn senare, inte bara uttryck som uppstod från expanderande beräknade kolumner.
Matchning av beräknade kolumnuttryck kan möjliggöra planförbättringar även när texten i den ursprungliga frågan inte kan ändras. Om till exempel att skapa en beräknad kolumn för att matcha ett känt frågeuttryck kan optimeraren använda statistik och index som är kopplade till den beräknade kolumnen. Den här funktionen liknar konceptuellt indexerad vymatchning i Enterprise Edition. Beräknad kolumnmatchning är funktionell i alla utgåvor.
Ur praktisk synvinkel har min egen erfarenhet varit att matchning av allmänna frågeuttryck till beräknade kolumner verkligen kan gynna prestanda, effektivitet och stabilitet i genomförandeplanen. Å andra sidan har jag sällan (om någonsin) tyckt att beräknad kolumnexpansion är värt besväret. Det verkar bara aldrig ge några användbara optimeringar.
Användningar av beräknade kolumner
Beräknade kolumner som är ingendera bevarade eller indexerade har giltiga användningsområden. Till exempel kan de stödja automatisk statistik om kolumnen är deterministisk och exakt (inga flyttalselement). De kan också användas för att spara lagringsutrymme (på bekostnad av lite extra körtidsprocessoranvändning). Som ett sista exempel kan de tillhandahålla ett snyggt sätt att säkerställa att en enkel beräkning alltid utförs korrekt, snarare än att explicit skrivas ut i frågor varje gång.
Vidhållit Beräknade kolumner lades till produkten specifikt för att tillåta index att bygga på deterministiska men "oprecisa" (flytande komma) kolumner. Enligt min erfarenhet är denna avsedda användning relativt sällsynt. Kanske beror detta helt enkelt på att jag inte stöter på flyttalsdata särskilt mycket.
Bortsett från flyttalsindex, kvarstående kolumner är ganska vanliga. Till viss del kan detta bero på att oerfarna användare antar att en beräknad kolumn alltid måste vara kvar innan den kan indexeras. Mer erfarna användare kan använda beständiga kolumner helt enkelt för att de har upptäckt att prestanda tenderar att bli bättre på det sättet.
Indexerad beräknade kolumner (beständiga eller inte) kan användas för att tillhandahålla beställning och en effektiv åtkomstmetod. Det kan vara användbart att lagra ett beräknat värde i ett index utan att också bevara det i bastabellen. Likaså kan lämpliga beräknade kolumner också inkluderas i index snarare än att vara nyckelkolumner.
Dålig prestanda
En viktig orsak till dålig prestanda är ett enkelt misslyckande med att använda ett indexerat eller beständigt beräknat kolumnvärde som förväntat. Jag har tappat räkningen på antalet frågor jag har haft under åren och frågade varför optimeraren skulle välja en fruktansvärd exekveringsplan när det finns en uppenbart bättre plan med en indexerad eller beständig beräknad kolumn.
Den exakta orsaken varierar i varje fall, men är nästan alltid antingen ett felaktigt kostnadsbaserat beslut (eftersom skalärer tilldelas en låg fast kostnad); eller ett misslyckande med att matcha ett utökat uttryck tillbaka till en beständig beräknad kolumn eller index.
Matchback-misslyckanden är särskilt intressanta för mig, eftersom de ofta involverar komplexa interaktioner med ortogonala motorfunktioner. Lika ofta lämnar misslyckandet med att "matcha tillbaka" ett uttryck (snarare än en kolumn) på en position i det interna frågeträdet som förhindrar en viktig optimeringsregel från att matcha. I båda fallen är resultatet detsamma:en suboptimal genomförandeplan.
Nu tycker jag att det är rättvist att säga att folk generellt indexerar eller behåller en beräknad kolumn med en stark förväntan att det lagrade värdet faktiskt kommer att användas. Det kan komma som en chock att se SQL Server räkna om det underliggande uttrycket varje gång, samtidigt som man ignorerar det avsiktligt tillhandahållna lagrade värdet. Människor är inte alltid särskilt intresserade av de interna interaktionerna och bristerna i kostnadsmodellen som ledde till det oönskade resultatet. Även där det finns lösningar kräver dessa tid, skicklighet och ansträngning för att upptäcka och testa.
Kort sagt:många skulle helt enkelt föredra att SQL Server använder det beständiga eller indexerade värdet. Alltid.
Ett nytt alternativ
Historiskt sett har det inte funnits något sätt att tvinga SQL Server att alltid använda det lagrade värdet (ingen motsvarighet till NOEXPAND tips för visningar). Det finns vissa omständigheter under vilka en planguide kommer att fungera, men det är inte alltid möjligt att generera den önskade planformen i första hand, och inte alla planelement och positioner kan tvingas fram (filter och beräkna skalärer, till exempel).
Det finns fortfarande ingen snygg, fullt dokumenterad lösning, men en nyligen genomförd uppdatering av SQL Server 2016 har gett ett intressant nytt tillvägagångssätt. Den gäller för SQL Server 2016-instanser som korrigerats med minst kumulativ uppdatering 2 för SQL Server 2016 SP1 eller kumulativ uppdatering 4 för SQL Server 2016 RTM.
Den relevanta uppdateringen är dokumenterad i:FIX:Det går inte att bygga om partitionen online för en tabell som innehåller en beräknad partitioneringskolumn i SQL Server 2016
Som så ofta med supportdokumentation säger detta inte exakt vad som har ändrats i motorn för att lösa problemet. Det ser verkligen inte särskilt relevant ut för våra nuvarande bekymmer, att döma av titeln och beskrivningen. Ändå introducerar denna korrigering en ny stödd spårningsflagga 176 , som kontrolleras i en kodmetod som heter FDontExpandPersistedCC . Som metodnamnet antyder förhindrar detta en beständig beräknad kolumn från att expanderas.
Det finns tre viktiga varningar för detta:
- Den beräknade kolumnen måste vara bevarad . Även om den är indexerad måste kolumnen också bevaras.
- Matchning tillbaka från allmänna frågeuttryck till beständiga beräknade kolumner är inaktiverad .
- Dokumentationen beskriver inte spårningsflaggans funktion och föreskriver den inte för någon annan användning. Om du väljer att använda spårningsflagga 176 för att förhindra expansion av beständiga beräknade kolumner, sker det därför på egen risk.
Denna spårningsflagga är effektiv som en start –T alternativ, i både global och sessionsomfattning med DBCC TRACEON , och per fråga med OPTION (QUERYTRACEON) .
Exempel
Detta är en förenklad version av en fråga (baserad på ett verkligt problem) som jag svarade på Database Administrators Stack Exchange för några år sedan. Tabelldefinitionen inkluderar en beständig beräknad kolumn:
SKAPA TABELL dbo.T( ID heltal IDENTITY NOT NULL, A varchar(20) NOT NULL, B varchar(20) NOT NULL, C varchar(20) NOT NULL, D date NULL, Beräknad SOM A + '-' + B + '-' + C PERSISTED, BEGRÄNSNING PK_T_ID PRIMÄRNYCKEL KLUSTERAD (ID),);GOINSERT dbo.T WITH (TABLOCKX) (A, B, C, D)SELECT A =STR(SV.number % 10, 2 ), B =STR(SV.nummer % 20, 2), C =STR(SV.tal % 30, 2), D =DATEADD(DAG, 0 - SV.nummer, SYSUTCDATETIME())FRÅN master.dbo.spt_values AS SVWHERE SV.[typ] =N'P';
Frågan nedan returnerar alla rader från tabellen i en viss ordning, samtidigt som nästa värde i kolumn D returneras i samma ordning:
VÄLJ T1.ID, T1.Computed, T1.D, NextD =( VÄLJ TOP (1) t2.D FRÅN dbo.T AS T2 DÄR T2.Computed =T1.Computed OCH T2.D> T1.D ORDNING AV T2.D ASC )FRÅN dbo.T AS T1ORDER BY T1.Computed, T1.D;
Ett uppenbart täckande index för att stödja den slutliga ordningen och uppslagningarna i underfrågan är:
SKAPA UNIKT INKLUSTERAT INDEX IX_T_Computed_D_IDON dbo.T (Computed, D, ID);
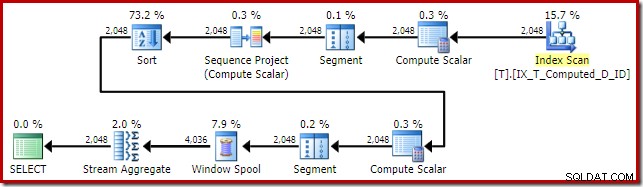
Utförandeplanen som levereras av optimeraren är överraskande och nedslående:
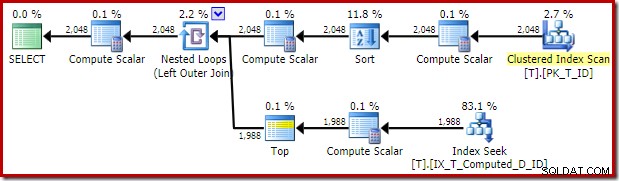
Indexsökningen på insidan av Nested Loops Join verkar vara bra. Clustered Index Scan and Sort på den yttre ingången är dock oväntad. Vi hade hoppats på att få se en beställd skanning av vårt täckande icke-klustrade index istället.
Vi kan tvinga optimeraren att använda det icke-klustrade indexet med en tabelltips:
VÄLJ T1.ID, T1.Computed, T1.D, NextD =( VÄLJ TOP (1) t2.D FRÅN dbo.T AS T2 DÄR T2.Computed =T1.Computed OCH T2.D> T1.D ORDNING BY T2.D ASC )FRÅN dbo.T AS T1 WITH (INDEX(IX_T_Computed_D_ID)) -- New!ORDER BY T1.Computed, T1.D;
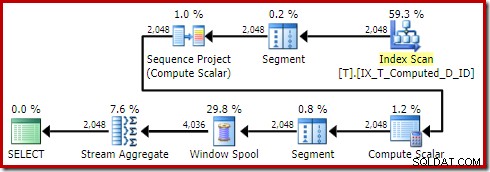
Den resulterande genomförandeplanen är:
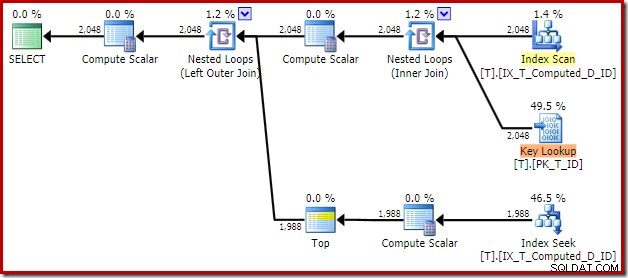
Genom att skanna det icke-klustrade indexet tas sorteringen bort, men en nyckelsökning läggs till! Uppslagningarna i denna nya plan är överraskande, med tanke på att vårt index definitivt täcker alla kolumner som behövs för frågan.
Titta på egenskaperna för Key Lookup-operatorn:
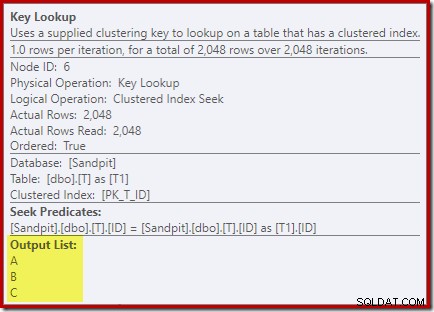
Av någon anledning har optimeraren beslutat att tre kolumner som inte nämns i frågan måste hämtas från bastabellen (eftersom de inte finns i vårt icke-klustrade index av design).
När vi tittar runt i utförandeplanen upptäcker vi att de uppslagna kolumnerna behövs av insidan Index Seek:

Den första delen av detta sökpredikat motsvarar korrelationen T2.Computed = T1.Computed i den ursprungliga frågan. Optimeraren har utökat definitionerna för båda beräknade kolumnerna, men bara lyckats matcha tillbaka till den beständiga och indexerade beräknade kolumnen för det inre sidoaliaset T1 . Lämna T2 referens expanderad har resulterat i att den yttre sidan av kopplingen behöver tillhandahålla bastabellens kolumner (A , B och C ) behövs för att beräkna det uttrycket för varje rad.
Som ibland är det möjligt att skriva om den här frågan så att problemet försvinner (ett alternativ visas i mitt gamla svar på Stack Exchange-frågan). Med SQL Server 2016 kan vi också försöka spåra flagga 176 för att förhindra att de beräknade kolumnerna expanderas:
VÄLJ T1.ID, T1.Computed, T1.D, NextD =( VÄLJ TOP (1) t2.D FRÅN dbo.T AS T2 DÄR T2.Computed =T1.Computed OCH T2.D> T1.D ORDNING AV T2.D ASC )FRÅN dbo.T AS T1ORDER BY T1.Computed, T1.DOPTION (QUERYTRACEON 176); -- Nytt!
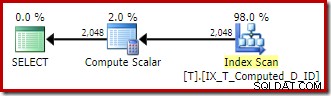
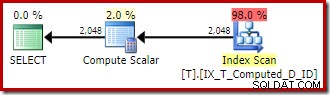
Utförandeplanen är nu mycket förbättrad:
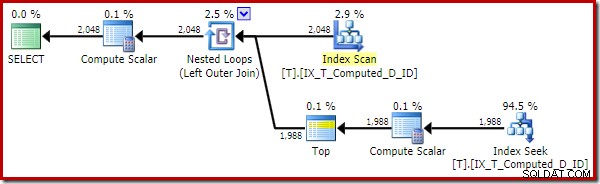
Denna exekveringsplan innehåller endast referenser till de beräknade kolumnerna. Compute Scalars gör inget användbart och skulle rensas upp om optimeraren var lite snyggare i huset.
Det viktiga är att det optimala indexet nu används på rätt sätt, och sortering och nyckelsökning har eliminerats. Allt genom att förhindra SQL Server från att göra något som vi aldrig skulle ha förväntat oss att den skulle göra från början (expanderar en beständig och indexerad beräknad kolumn).
Använda LEAD
Den ursprungliga Stack Exchange-frågan var inriktad på SQL Server 2008, där LEAD är inte tillgänglig. Låt oss försöka uttrycka kravet på SQL Server 2016 med den nyare syntaxen:
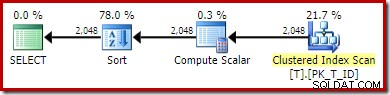
VÄLJ T1.ID, T1.Computed, T1.D, NextD =LEAD(T1.D) OVER ( PARTITION BY T1.Computed ORDER BY T1.D)FROM dbo.T AS T1ORDER BY T1.Computed;SQL Server 2016-exekveringsplanen är:
Denna planform är ganska typisk för en enkel radlägesfönsterfunktion. Det enda oväntade objektet är sorteringsoperatorn i mitten. Om datamängden var stor skulle denna sortering kunna ha stor inverkan på prestanda och minnesanvändning.
Problemet är återigen den beräknade kolumnexpansionen. I det här fallet sitter ett av de utökade uttrycken i en position som förhindrar normal optimeringslogik från att förenkla sorteringen.
Försöker exakt samma fråga med spårningsflagga 176:
VÄLJ T1.ID, T1.Computed, T1.D, NextD =LEAD(T1.D) OVER ( PARTITION BY T1.Computed ORDER BY T1.D)FRÅN dbo.T AS T1ORDER BY T1.ComputedOPTION (QUERYTRACEON 176 );Tar fram planen:
Sorten har försvunnit som den ska. Observera också i förbigående att denna fråga kvalificerade sig för en trivial plan, vilket helt och hållet undviker kostnadsbaserad optimering.
Inaktiverad matchning av allmänna uttryck
En av förbehållen som nämndes tidigare var att spårningsflagga 176 också inaktiverar matchning från uttryck i källfrågan till beständiga beräknade kolumner.
För att illustrera, överväg följande version av exempelfrågan.
LEADberäkningen har tagits bort, och referenserna till den beräknade kolumnen iSELECTochORDER BYsatser har ersatts med de underliggande uttrycken. Kör det först utan spårflagga 176:VÄLJ T1.ID, beräknat =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1.B + '-' + T1.C;Uttrycken matchas till den beständiga beräknade kolumnen, och exekveringsplanen är en enkel beställd genomsökning av det icke-klustrade indexet:
Compute Scalar där är återigen bara överblivet arkitektoniskt skräp.
Prova nu samma fråga med spårningsflagga 176 aktiverad:
VÄLJ T1.ID, beräknat =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1.B + '-' + T1.COPTION (QUERYTRACEON 176); -- Nytt!Den nya genomförandeplanen är:
Nonclustered Index Scan har ersatts med en Clustered Index Scan. Compute Scalar utvärderar uttrycket och sorteringsordningarna efter resultatet. Berövas förmågan att matcha uttryck med beständiga beräknade kolumner, kan optimeraren inte använda det bevarade värdet eller det icke-klustrade indexet.
Observera att begränsningen för uttrycksmatchning endast gäller för bevarade beräknade kolumner när spårningsflaggan 176 är aktiv. Om vi gör den beräknade kolumnen indexerad men inte beständig, fungerar uttrycksmatchning korrekt.
För att ta bort det beständiga attributet måste vi först ta bort det icke-klustrade indexet. När ändringen är gjord kan vi lägga indexet rakt tillbaka (eftersom uttrycket är deterministiskt och exakt):
DROP INDEX IX_T_Computed_D_ID ON dbo.T;GOALTER TABLE dbo.TALTER COLUMN ComputedDROP PERSISTED;GOCREATE UNIQUE ICLUSTERED INDEX IX_T_Computed_D_IDON dbo.T (Computed, D, ID);Optimeraren har nu inga problem med att matcha frågeuttrycket med den beräknade kolumnen när spårningsflagga 176 är aktiv:
-- Beräknad kolumn kvarstår inte längre-- men fortfarande indexerad. TF 176 aktiv.VÄLJ T1.ID, Beräknad =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDNING AV T1.A + '-' + T1. B + '-' + T1.COPTION (QUERYTRACEON 176);Exekveringsplanen återgår till den optimala icke-klustrade indexsökningen utan sortering:
För att sammanfatta:Spårningsflaggan 176 förhindrar ihållande beräknad kolumnexpansion. Som en bieffekt förhindrar den också matchning av frågeuttryck endast med beständiga beräknade kolumner.
Schemametadata laddas bara en gång, under bindningsfasen. Spårningsflaggan 176 förhindrar expansion så att den beräknade kolumndefinitionen inte laddas vid den tidpunkten. Senare matchning av uttryck till kolumn kan inte fungera utan den beräknade kolumndefinitionen att matcha mot.
Den initiala metadataladdningen tar in alla kolumner, inte bara de som refereras till i frågan (den optimeringen utförs senare). Detta gör alla beräknade kolumner tillgängliga för matchning, vilket i allmänhet är bra. Tyvärr, om en av de laddade beräknade kolumnerna innehåller en skalär användardefinierad funktion, inaktiverar dess närvaro parallellism för hela frågan även när den problematiska kolumnen inte används. Spårningsflagga 176 kan också hjälpa till med detta, om kolumnen i fråga kvarstår. Genom att inte ladda definitionen finns aldrig en skalär användardefinierad funktion, så parallellism är inte inaktiverad.
Sluta tankar
Det förefaller mig som att SQL Server-världen är en bättre plats om optimeraren behandlade kvarstående eller indexerade beräknade kolumner mer som vanliga kolumner. I nästan alla fall skulle detta bättre matcha utvecklarnas förväntningar än det nuvarande arrangemanget. Att expandera beräknade kolumner till deras underliggande uttryck och senare försöka matcha tillbaka dem är inte så framgångsrikt i praktiken som teorin kan antyda.
Tills SQL Server ger specifikt stöd för att förhindra ihållande eller indexerad datorkolumnexpansion, är den nya spårningsflaggan 176 ett frestande alternativ för SQL Server 2016-användare, även om det är ofullkomligt. Det är lite olyckligt att det inaktiverar matchning av generella uttryck som en bieffekt. Det är också synd att den beräknade kolumnen måste finnas kvar när den indexeras. Det finns då risk att använda en spårningsflagga för annat än dess dokumenterade syfte att överväga.
Det är rimligt att säga att majoriteten av problemen med beräknade kolumnfrågor i slutändan kan lösas på andra sätt, givet tillräckligt med tid, ansträngning och expertis. Å andra sidan verkar spårflaggan 176 ofta fungera som magi. Valet är, som de säger, ditt.
För att avsluta, här är några intressanta beräknade kolumnproblem som drar nytta av spårningsflagga 176:
- Det beräknade kolumnindexet används inte
- PRESISTED beräknad kolumn används inte i partitionering av fönsterfunktioner
- Ihållande beräknad kolumn orsakar skanning
- Beräknat kolumnindex används inte med MAX datatyper
- Allvarliga prestandaproblem med ihållande beräknade kolumner och sammanfogningar
- Varför "beräknar SQL Server skalär" när jag VÄLJER en beständig beräknad kolumn?
- Baskolumner används istället för beständiga beräknade kolumn för motor
- Computed Column med UDF inaktiverar parallellism för frågor på *andra* kolumner