I mitt tidigare inlägg i den här serien visade jag att inte alla frågescenarier kan dra nytta av In-Memory OLTP-tekniker. Faktum är att användning av Hekaton i vissa användningsfall faktiskt kan ha en skadlig effekt på prestandan (klicka för att förstora):

Prestandaövervakningsprofil under körning av lagrad procedur
Däremot kan jag ha stackat kortleken mot Hekaton i det scenariot, på två sätt:
- Den minnesoptimerade tabelltypen jag skapade hade en bucket count på 256, men jag skickade in upp till 2 000 värden att jämföra. I ett nyare blogginlägg från SQL Server-teamet förklarade de att överdimensionering av bucket-antalet är bättre än att underdimensionera det – något som jag visste i allmänhet, men inte insåg också hade betydande effekter på tabellvariabler:Keep kom ihåg att för ett hashindex bör bucket_count vara ungefär 1-2X antalet förväntade unika indexnycklar. Överdimensionering är vanligtvis bättre än underdimensionering:om du ibland bara infogar 2 värden i variablerna, men ibland infogar upp till 1000 värden, är det vanligtvis bättre att ange
BUCKET_COUNT=1000.De diskuterar inte uttryckligen den faktiska orsaken till detta, och jag är säker på att det finns massor av tekniska detaljer som vi skulle kunna fördjupa oss i, men den föreskrivande vägledningen verkar vara för stor.
- Den primära nyckeln var ett hashindex på två kolumner, medan parametern med tabellvärde bara försökte matcha värden i en av dessa kolumner. Detta innebar helt enkelt att hashindexet inte kunde användas. Tony Rogerson förklarar detta lite mer detaljerat i ett nyligen publicerat blogginlägg:Hashen genereras över alla kolumner som finns i indexet, du måste också ange alla kolumner i hashindexet på ditt likhetskontrolluttryck annars kan indexet inte användas .
Jag visade det inte tidigare, men lägg märke till att planen mot den minnesoptimerade tabellen med hashindexet med två kolumner faktiskt gör en tabellsökning snarare än den indexsökning som du kan förvänta dig mot det icke-klustrade hashindexet (eftersom den ledande kolumnen var
SalesOrderID):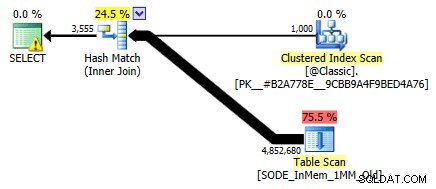
Frågeplan som involverar en tabell i minnet med två kolumner hashindexFör att vara mer specifik, i ett hashindex, betyder den inledande kolumnen inte en kulle av bönor i sig; hashen matchas fortfarande över alla kolumner, så det fungerar inte alls som ett traditionellt B-trädindex (med ett traditionellt index kan ett predikat som endast involverar den inledande kolumnen fortfarande vara mycket användbart för att eliminera rader).
Vad ska jag göra?
Tja, först skapade jag ett sekundärt hashindex på endast SalesOrderID kolumn. Ett exempel på ett sådant bord, med en miljon hinkar:
SKAPA TABELL [dbo].[SODE_InMem_1MM]( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] [nvarchar](25) SAMMANSTÄLL SQL_Latin1_General_QtyLL], [smallas NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceRabatt] [money] NOT NULL, [LineTotal] [numeric](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL PRIMÄRNYCKEL INKLUSTERAD HASH ( [SalesOrderID], [SalesOrderDetailID] ) MED (BUCKET_COUNT =1048576), /* Jag har lagt till denna sekundära index:*/ INDEX x ONCLUSTERED HASH ( [SalesOrderID] ) WITH (BUCKET_COUNT =1048576) /* Jag använde samma bucket count för att minimera testpermutationer */ ) WITH (MEMORY_OPTIMIZED =PÅ, DURABILITY>_D SCHATA_DURABILITY);Kom ihåg att våra tabelltyper är inställda på detta sätt:
CREATE TYPE dbo.ClassicTVP AS TABLE( Item INT PRIMARY KEY); CREATE TYPE dbo.InMemoryTVP AS TABLE( Item INT NOT NULL PRIMARY KEY ONCLUSTED HASH WITH (BUCKET_COUNT =256)) WITH (MEMORY_OPTIMIZED =ON);När jag väl fyllt i de nya tabellerna med data och skapat en ny lagrad procedur för att referera till de nya tabellerna, visar planen vi får korrekt en indexsökning mot hashindexet med en kolumn:
Förbättrad plan med hashindex med en kolumnMen vad skulle det egentligen betyda för prestandan? Jag körde samma uppsättning tester igen – frågor mot den här tabellen med bucket counts på 16K, 131K och 1MM; använder både klassiska TVP och in-memory TVP med 100, 1 000 och 2 000 värden; och i fallet med TVP i minnet, med användning av både en traditionell lagrad procedur och en inbyggt kompilerad lagrad procedur. Så här gick prestanda för 10 000 iterationer per kombination:
Prestandaprofil för 10 000 iterationer mot ett hashindex med en kolumn, med en TVP med 256 hinkarDu kanske tycker, hej, att prestationsprofilen inte ser så bra ut; tvärtom, det är mycket bättre än mitt tidigare test förra månaden. Det visar bara att bucket count för tabellen kan ha en enorm inverkan på SQL Servers förmåga att effektivt använda hashindex. I det här fallet är det helt klart inte optimalt att använda en bucket count på 16K för något av dessa fall, och det blir exponentiellt värre när antalet värden i TVP ökar.
Kom ihåg att TVP:ns bucket count var 256. Så vad skulle hända om jag ökade det, enligt Microsofts riktlinjer? Jag skapade en andra bordstyp med en mer lämplig hinkstorlek. Eftersom jag testade 100, 1 000 och 2 000 värden använde jag nästa potens av 2 för bucket count (2 048):
SKAPA TYP dbo.InMemoryTVP SOM TABELL( Item INT NOT NULL PRIMÄRNYCKEL INKLUSTERAD HASH MED (BUCKET_COUNT =2048)) MED (MEMORY_OPTIMIZED =PÅ);Jag skapade stödprocedurer för detta och körde samma batteri av tester igen. Här är prestationsprofilerna sida vid sida:
Prestanda profiljämförelse med 256- och 2 048-bucket TVPs em>Ändringen i bucket count för tabelltypen fick inte den inverkan jag hade förväntat mig, med tanke på Microsofts uttalande om storlek. Det hade verkligen inte så mycket positiv effekt alls; i vissa scenarier var det faktiskt lite värre. Men överlag är prestationsprofilerna, i alla avseenden, desamma.
Vad som dock hade en enorm effekt var att skapa *rätt* hashindex för att stödja frågemönstret. Jag var tacksam för att jag kunde visa att – trots mina tidigare tester som indikerade något annat – en minnestabell och en minnes-TVP kunde slå det gamla skolans sätt att åstadkomma samma sak. Låt oss bara ta det mest extrema fallet från mitt tidigare exempel, när tabellen bara hade ett hashindex med två kolumner:
Prestandaprofil för 10 iterationer mot ett hashindex med två kolumnerRaden längst till höger visar varaktigheten av endast 10 iterationer av den ursprungliga lagrade proceduren som matchar ett olämpligt hashindex – frågetider som sträcker sig från 735 till 1 601 millisekunder. Men nu, med rätt hash-index på plats, körs samma frågor i mycket mindre intervall – från 0,076 millisekunder till 51,55 millisekunder. Om vi utelämnar det värsta fallet (16K bucket counts) är avvikelsen ännu mer uttalad. I alla fall är detta minst dubbelt så effektivt (åtminstone i termer av varaktighet) som båda metoderna, utan en naivt kompilerad lagrad procedur, mot samma minnesoptimerade tabell; och hundratals gånger bättre än någon av metoderna mot vår gamla minnesoptimerade tabell med det enda hashindexet med två kolumner.
Slutsats
Jag hoppas att jag har visat att mycket försiktighet måste iakttas när man implementerar minnesoptimerade tabeller av vilken typ som helst, och att det i många fall kanske inte ger den största prestandavinsten att använda en minnesoptimerad TVP på egen hand. Du kommer att vilja överväga att använda inbyggt kompilerade lagrade procedurer för att få mest valuta för pengarna, och i bästa skala kommer du verkligen att vilja vara uppmärksam på bucket count för hashindexen i dina minnesoptimerade tabeller (men kanske inte så mycket uppmärksamhet åt dina minnesoptimerade tabelltyper).
För ytterligare läsning om In-Memory OLTP-teknik i allmänhet, kanske du vill kolla in dessa resurser:




- SQL Server Team Blog (Tag:Hekaton och Tag:In-Memory OLTP – är inte kodnamn kul?)
- Bob Beauchemins blogg
- Klaus Aschenbrenners blogg