I de tidigare bloggarna visade mina kollegor och jag hur du kan övervaka prestanda, hantera och distribuera kluster, köra säkerhetskopior och till och med aktivera automatisk failover för TimescaleDB.
I den här bloggen kommer vi att visa dig hur du skalar din enstaka TimescaleDB-instans till multinodkluster med bara några enkla steg.
Vi kommer att börja med en gemensam installation, en enda nodinstans som körs på CentosOS. Noden är igång och den övervakas och hanteras redan av ClusterControl.
Om du vill lära dig hur du distribuerar eller importerar din TimescaleDB-instans, kolla in bloggen skriven av min kollega Sebastian Insausti, "Hur man enkelt distribuerar TimescaleDB."
Inställningen ser ut som följer...
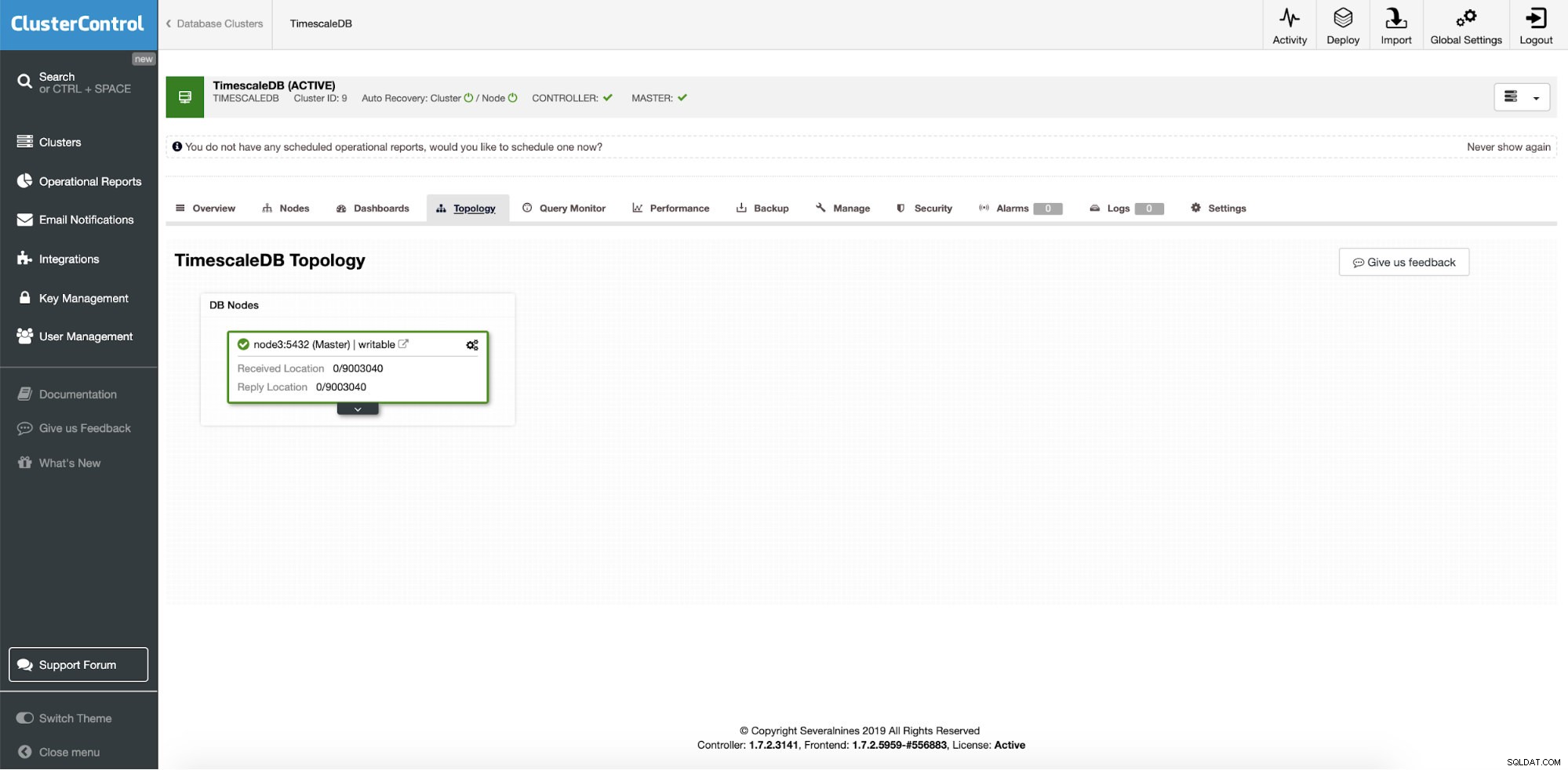 ClusterControl:Single instans TimescaleDB
ClusterControl:Single instans TimescaleDB Så det är en enda produktionsinstans och vi vill konvertera den till kluster utan stillestånd. Vårt huvudsakliga mål är att skala applikationsläsoperationer till andra maskiner med möjlighet att använda dem som iscensättande HA-servrar när du skriver serverkrasch.
Fler noder bör också minska stilleståndstiden för programunderhåll. Som korrigering tillämpas i rullande omstartsläge - en nod korrigerad åt gången medan andra noder betjänar databasanslutningar.
Det sista kravet är att skapa en enda adress för vårt nya kluster så att våra nya noder blir synliga för applikationen från ett ställe.

Vi kan sammanfatta vår handlingsplan i två stora steg:
- Lägga till en replikläsning
- Installera och konfigurera Haproxy
Lägga till en replikläsning
Om vi går till klusteråtgärder och väljer "Lägg till replikeringsslav", kan vi antingen skapa en ny replik från början eller lägga till en befintlig TimescaleDB-databas som en replik.
 ClusterControl:Lägg till replikeringsslav
ClusterControl:Lägg till replikeringsslav 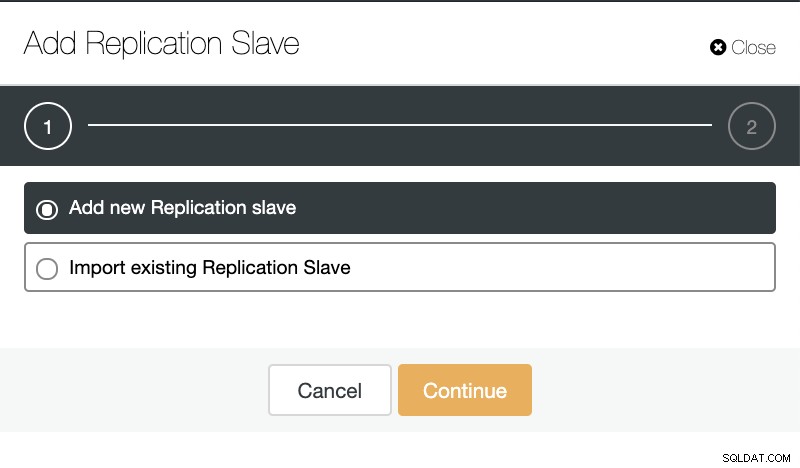 ClusterControl:Lägg till ny replikeringsslav, importera befintlig replikeringsslav
ClusterControl:Lägg till ny replikeringsslav, importera befintlig replikeringsslav Som du kan se i bilden nedan behöver vi bara välja vår masterserver, ange IP-adressen för vår nya slavserver och databasporten.
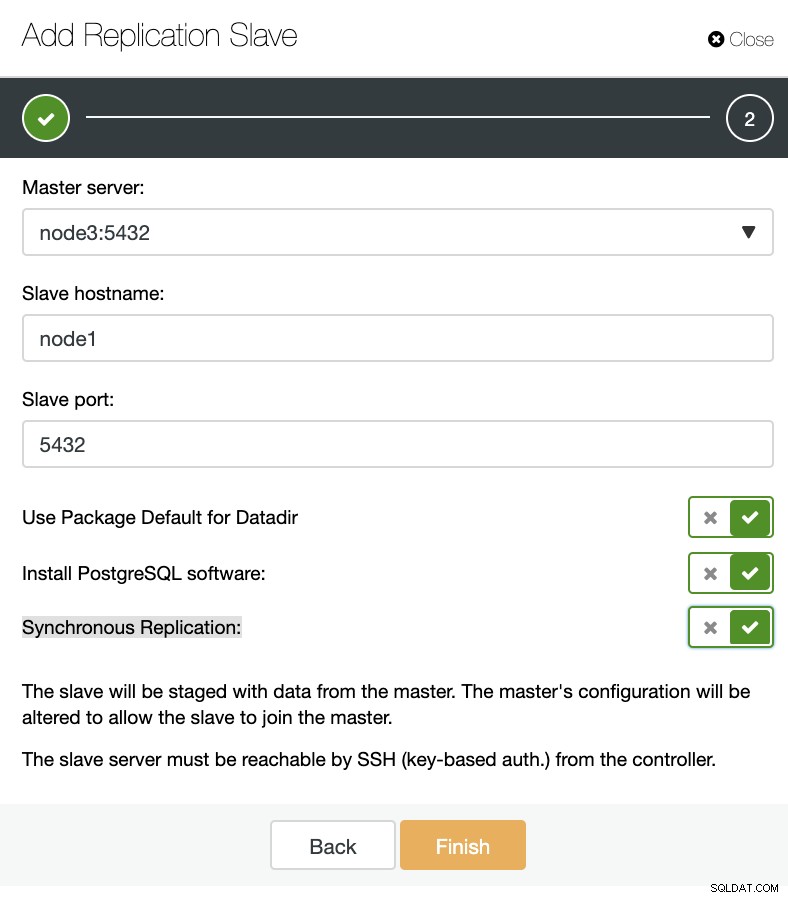 ClusterControl:Lägg till replikeringsslav
ClusterControl:Lägg till replikeringsslav Sedan kan vi välja om vi vill att ClusterControl ska installera programvaran åt oss och om replikeringsslaven ska vara Synchronous eller Asynchronous. När du importerar befintlig slavserver kan du använda importalternativet enligt följande:
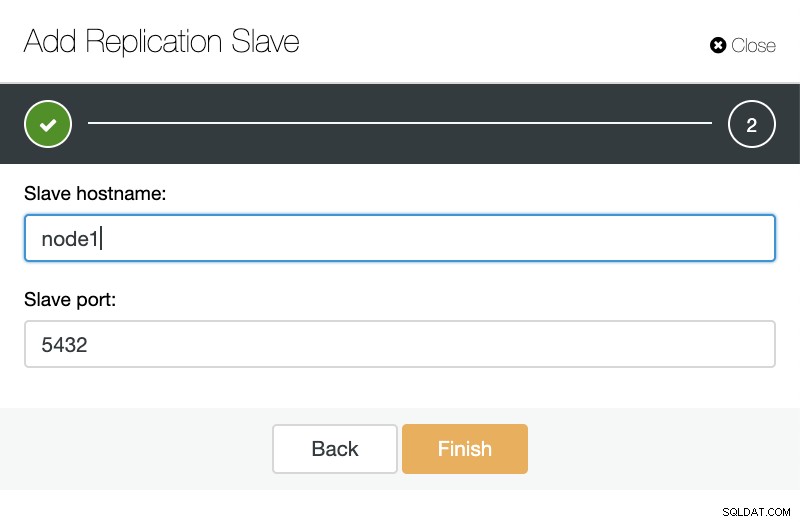 ClusterControl:Importera replikeringsslav för TimescaleDB
ClusterControl:Importera replikeringsslav för TimescaleDB Båda sätten kan vi lägga till så många repliker som vi vill. I vårt exempel kommer vi att lägga till två noder. CusterControl skapar ett internt jobb och tar hand om alla nödvändiga steg med en ingen åt gången.
 ClusterControl:lägg till läsreplika
ClusterControl:lägg till läsreplika Lägga till en lastbalanserare till TimescaleDB
Vid det här laget distribueras vår data över flera noder eller datacenter om du väljer att lägga till replikeringsslavnoder på en annan plats. Klustret skalas ut med ytterligare två läsrepliknoder.
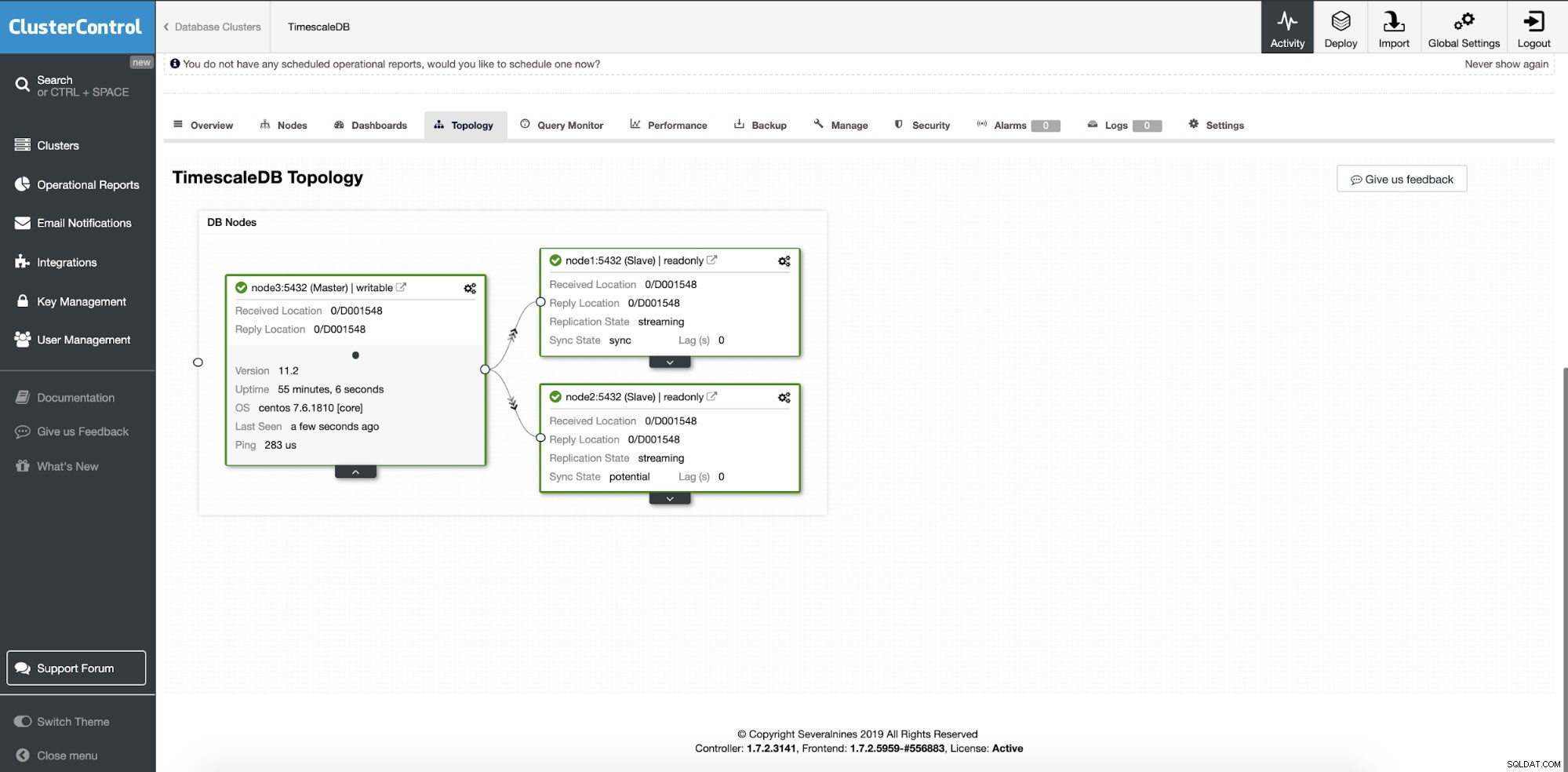 ClusterControl:Två noder har lagts till
ClusterControl:Två noder har lagts till Frågan är hur vet applikationen vilken databasnod den ska komma åt? Vi kommer att använda HAProxy och olika portar för skriv- och läsoperationer.
Från TimescaleDB-klustret väljer snabbmenyn att lägga till lastbalanserare.

Nu måste vi ange platsen för servern där Haproxy ska installeras, vilken policy vi vill använda för databasanslutningar och vilka noder som ingår i Haproxy-konfigurationen.
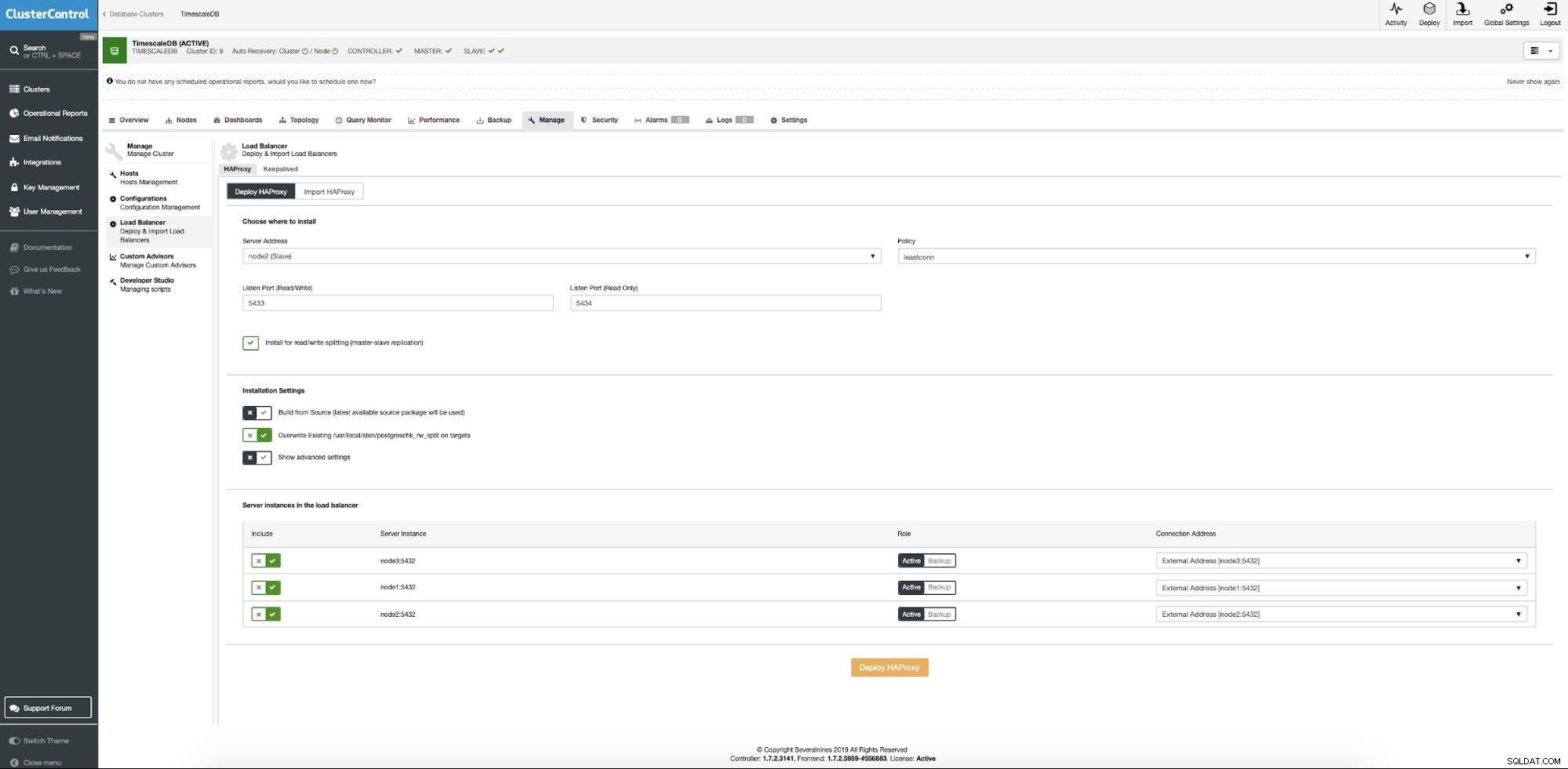
När allt är klart, tryck på deploy-knappen. Efter några minuter bör vi göra vår klusterkonfiguration klar. ClusterControl tar hand om alla förutsättningar och konfigurationer för att distribuera lastbalanserare.
Efter en framgångsrik implementering kan vi se vårt nya klusters topologi; med lastbalansering och ytterligare läsnoder. Med fler noder ombord, aktiverar ClusterControl automatiskt automatisk återställning. På detta sätt, när masternoden går ner, kommer failover-operationen att starta av sig själv.
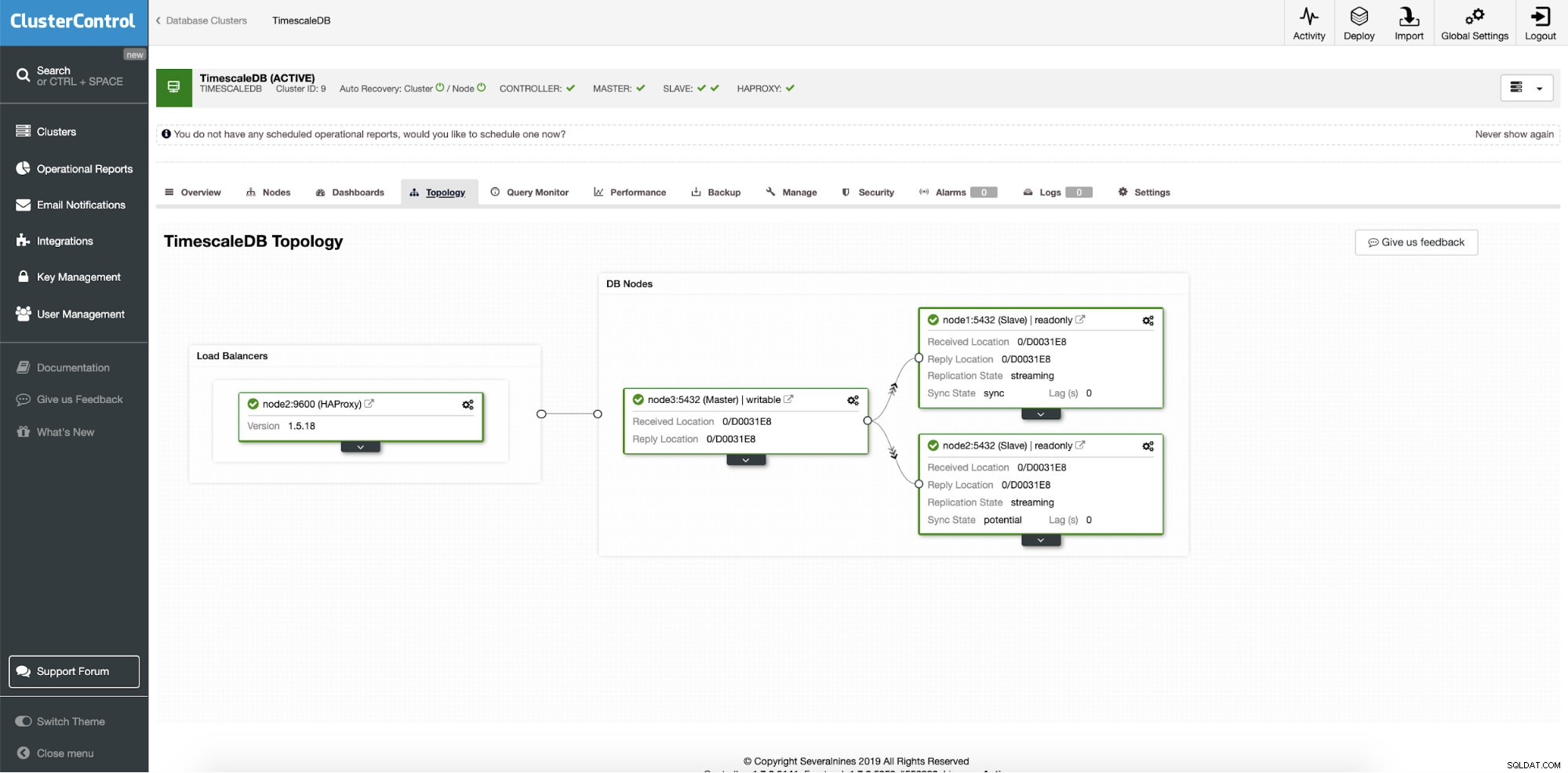 ClusterControl:Final topology
ClusterControl:Final topology Slutsats
TimescaleDB är en öppen källkodsdatabas som uppfunnits för att göra SQL skalbar för tidsseriedata. Att ha ett automatiserat sätt att utöka sitt kluster är en nyckel för att uppnå prestanda och effektivitet. Som vi har sett ovan kan du nu skala TimescaleDB genom att använda ClusterControl med lätthet.