Uppdatering:Q2’16 :Förutom databasprofileringsguiden i menygruppen för dataupptäckt i IRI Workbench som beskrivs nedan, har IRI introducerat robust dataklassificering som möjliggör tillämpning av fältregler för datatransformation och skydd med flera källor genom dataklassbibliotek. Uppdatering Q2’18 :IRI har också introducerat en schemaomfattande mönstersökningsguide för att hitta PII-matchande RegEx eller bokstavliga värden i flera tabeller samtidigt. Uppdatera Q2’19 :IRI tillhandahåller nu även inter/intra-schema dataklasssökning ochmaskering för användare IRI FieldShield eller Voracity. Och IRI publicerade just den här artikeln för att visa hur DB-profileringsresultaten nedan visas i Splunk.
Med mer data som samlas in från fler aspekter av verksamheten idag, är enkel medvetenhet om innehållet och naturen viktigt för att säkerställa kvaliteten, kvantiteten och säkerheten av dessa samlingar. Dataprofilering är den viktiga upptäcktsprocessen som hjälper dig att analysera, klassificera, rensa, integrera, maskera och rapportera om data i dina lager.
Förutom guider för mörk och strukturerad dataupptäckt (och metadatadefinition), tillsammans med cross-DB E-R diagramming i Eclipse, tillåter det nya cross-DB profileringsverktyget i IRI Workbench användare att undersöka strukturen och fullständigheten av databasdata och validera att rätt data lagras på rätt ställen. I den här artikeln kommer vi att undersöka det här verktyget och visa hur det ger sökresultat med tabellvärden och statistisk metadata.
För att få åtkomst till Databas Profiler, navigera till tabellen du vill komma åt i Data Source Explorer. Högerklicka på tabellen och för musen över alternativet IRI. Välj Ny databasprofil på menyn som visas .
På den första guidesidan ställer du in platsen och destinationen för jobbet och väljer utdata från profilrapporten, som .csv eller en .txt-fil, eller båda.
- .csv-formatet är användbart för att importera till nya tabeller och databaser, medan
- .txt-formatet är en förformaterad rapport, användbar för att snabbt granska resultat.
Statistisk profilinformation
Nästa del av guiden visas med två tabeller:
- Den översta tabellen är en lista över alla tabeller i databasen, med tabellen som startade guiden markerad som standard.
- Den här kryssrutan låter dig skanna alla tabeller och rader i din databas med ett klick.

- Den nedre tabellen visar profileringsalternativen, följt av kolumnerna i den markerade tabellen där du väljer att utföra alternativen.

Klicka på valfritt bord i listan som du vill se och profilera. Alternativmatrisen ändras automatiskt för att representera kolumnerna i den valda tabellen. Det finns flera sätt att hantera visningsalternativen:
- För alla alternativ klickar du på den översta kryssrutan i tabellen, märkt Alla, så kommer all metadata att rapporteras.
- Endast för grundläggande alternativ (räkning och värden), markera kryssrutan märkt Grunder.
- Endast för längdalternativ (värdelängder), markera kryssrutan märkt Längder.
Om du har många kolumner i din tabell och vill välja samma alternativ för alla, klicka på själva alternativnamnet, och alla kolumner kommer att ha det alternativet markerat. Du kan avmarkera kolumner inom alternativet.
När allt är klart klickar du på Slutför och sedan kommer profilen att genereras åt dig.
Uttryckssökning
Ett unikt val i alternativtabellen är -Expression Search-. Med det här alternativet kan du söka i kolumner mot en mängd olika sökalternativ. Dessa alternativ är:
- Reguljära uttryck (mönstersökning). Detta lokaliserar och räknar antalet gånger ett värde matchar formatet för ett sökmönster.
- Luddrig sträng. Med det här alternativet kan du söka efter strängar som liknar de du anger och att välja eller ange sökvillkor.
- Värdefil. Med det här alternativet kan du jämföra en sträng med varje sträng i en uppsättningsfil och räkna varje sträng som har en matchning.
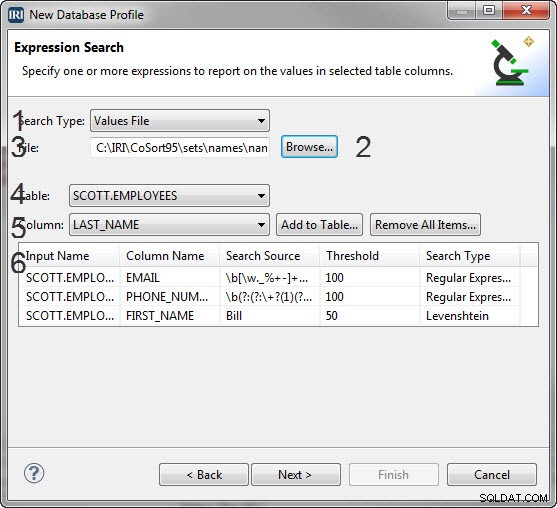
Uttryckssökningssidan har 6 viktiga avsnitt
- En kombinationsruta för söktyp för att välja vilken typ av sökning som ska utföras.
- Alternativgruppen som ändras beroende på vald söktyp
- Reguljärt uttryck:har två knappar; bläddra som bläddrar i de befintliga reguljära uttryck, och Create... som tillåter skapandet av nya reguljära uttryck.
- Fuzzy String:har en räkneruta som anger tröskeln för den fuzzy sökningen (hur nära strängarna måste vara för att betraktas som en matchning), och en kombinationsruta för att välja den fuzzy sökalgoritm som ska användas.
- Värdefil:har en knapp Bläddra... som låter dig söka efter den uppsättningsfil som ska användas för värdesökningen.
- En textruta där du anger data för din sökning.
- En rullgardinslista med tabeller som du kan använda uttryckssökningen på.
- En rullgardinslista med kolumner på vilka du kan använda uttryckssökningen.
- En tabell som visar de sökningar du har skapat och som kommer att utföras av profileraren.
Så här skapar du ett filter för reguljära uttryck:
- Välj Reguljärt uttryck i kombinationen Söktyp .
- Klicka på Bläddra till (ditt bibliotek med sparade uttryck), eller klicka på Skapa för att ange ett reguljärt uttryck som ska användas för att söka efter kolumnvärden.
- I menyn Tabell väljer du tabellen som innehåller kolumnen som ska filtreras.
- I kolumnmenyn väljer du den kolumn som det reguljära uttrycket ska tillämpas på.
- Klicka på Lägg till i tabell , och ett objekt visas i tabellen nedan som innehåller filnamnet, kolumnnamnet, sökkällan, tröskelvärdet och etiketten för reguljära uttryck som utgör filtret.
- Upprepa denna process för varje kolumn som du vill lägga till ett filter till. Om du har för många kolumner för att göra den här processen praktisk, kan du fortfarande skanna flera kolumner och tabeller automatiskt – efter data som matchar dina mönster över ett helt databasschema – med hjälp av den här guiden istället.
Så här skapar du en suddig strängsökning:
- Välj Fuzzy String i kombinationen Söktyp .
- Skriv strängen som ska användas för sökning.
- Välj antalet resultat som ska returneras (det här alternativet visas när Fuzzy Search är valt).
- Välj den Fuzzy Search Type att använda (det här alternativet visas när Fuzzy String väljs).
- I tabellmenyn väljer du filen som innehåller kolumnen för att göra suddig sökning.
- I kolumnmenyn väljer du den kolumn som den otydliga sökningen ska utföras till.
- Klicka på Lägg till i tabell , och ett objekt visas i tabellen nedan som innehåller filnamnet, kolumnnamnet, sökkällan, tröskeln och söktypen för den otydliga sökningen som ska utföras.
- Upprepa denna process för varje kolumn där du vill utföra en suddig strängsökning.
För att skapa en värdefilsökning:
- Välj Värdefil i kombinationen Söktyp .
- Klicka på Bläddra för att välja en uppsättningsfil som kolumnen ska kontrolleras mot.
- I menyn Tabell väljer du tabellen som innehåller kolumnen som ska filtreras.
- I kolumnmenyn väljer du den kolumn som det reguljära uttrycket ska tillämpas på.
- Klicka på Lägg till i tabell , och ett objekt visas i tabellen nedan som innehåller filnamnet, kolumnnamnet, sökkällan, tröskelvärdet och söketiketten för värdelistan som utgör filtret.
Kontroll av referensintegritet
Ett annat val i alternativtabellen är -Kontrollera referensintegritet-. Detta alternativ gör att profileraren kan jämföra en eller flera kolumner med en annan kolumn och avgöra om kolumnerna har referensintegritet. Om du vill använda den här funktionen markerar du rutorna -Kontrollera referensintegritet- i kolumnerna för att jämföra referensintegriteten. Nästa-knappen aktiveras och låter dig ange parametrarna för referensintegritetskontrollen (se nedan för detaljer).
Om du valde alternativet Kontrollera referensintegritet för någon av dina kolumner klickar du på Nästa för att gå till sidan för referensintegritetskontroll. Den här sidan har följande funktioner:
- Två kombinationsrutor, en för att välja den tabell som primärnyckeln finns i, den andra för att ange kolumnen för primärnyckeln.
- Två kombinationsrutor, en för att välja tabellen som den främmande nyckeln finns i, den andra för att ange kolumnen för den främmande nyckeln. Det finns också en knapp för att lägga till den främmande nyckeln till en lista med främmande nycklar för att jämföra med den primära nyckeln.
- En knapp för Skapa integritetskontroll för att lägga till primära och främmande kolumner i listan nedan.
- En lista som lagrar alla referensintegritetskontroller som kommer att utföras av profileraren.

Så här skapar du en referensintegritetskontroll:
- I tabellkomborutan under Primärnyckelkolumn väljer du tabellen som primärnyckeln finns i.
- Välj primärnyckeln i kolumnkombinationsrutan under Primärnyckelkolumn.
- Välj tabellen som den främmande nyckeln finns i i tabellkombinationsrutan under Kolumn Utländsk nyckel.
- Välj den främmande nyckeln i kolumnkombinationsrutan under Kolumn Utländsk nyckel.
- Klicka på knappen Lägg till i lista med främmande nyckel...
- Upprepa steg 3-5 för varje främmande nyckel som ska kontrolleras mot primärnyckeln
- Klicka på knappen Skapa integritetskontroll...
- Upprepa ovanstående processer för varje referensintegritetskontroll som ska utföras.
Exempel på profilutgångar

.csv visas i LibreOffice / .txt som visas i EditPad Lite