Nuförtiden är replikering en självklarhet i en hög tillgänglighet och feltolerant miljö för i stort sett all databasteknik som du använder. Det är ett ämne som vi har sett om och om igen, men som aldrig blir gammalt.
Om du använder TimescaleDB är den vanligaste typen av replikering strömmande replikering, men hur fungerar det?
I den här bloggen kommer vi att granska några koncept relaterade till replikering och vi kommer att fokusera på strömmande replikering för TimescaleDB, som är en funktionalitet som ärvts från den underliggande PostgreSQL-motorn. Sedan får vi se hur ClusterControl kan hjälpa oss att konfigurera det.
Så, strömmande replikering är baserad på att skicka WAL-posterna och låta dem appliceras på standby-servern. Så låt oss först se vad WAL är.
WAL
Write Ahead Log (WAL) är en standardmetod för att säkerställa dataintegritet, den är automatiskt aktiverad som standard.
WALs är REDO-loggarna i TimescaleDB. Men vad är REDO-loggarna?
REDO-loggar innehåller alla ändringar som gjorts i databasen och de används av replikering, återställning, online-backup och punktåterställning (PITR). Alla ändringar som inte har tillämpats på datasidorna kan göras om från REDO-loggarna.
Att använda WAL resulterar i ett avsevärt minskat antal diskskrivningar, eftersom endast loggfilen behöver spolas till disken för att garantera att en transaktion genomförs, snarare än varje datafil som ändras av transaktionen.
En WAL-post kommer att specificera, bit för bit, ändringarna som gjorts i datan. Varje WAL-post kommer att läggas till i en WAL-fil. Infogningspositionen är ett Log Sequence Number (LSN) som är en byteförskjutning i loggarna, som ökar med varje ny post.
WALs lagras i katalogen pg_wal, under datakatalogen. Dessa filer har en standardstorlek på 16MB (storleken kan ändras genom att ändra konfigurationsalternativet --with-wal-segsize när du bygger servern). De har ett unikt inkrementellt namn, i följande format:"00000001 00000000 00000000".
Antalet WAL-filer som finns i pg_wal kommer att bero på värdet som tilldelas parametrarna min_wal_size och max_wal_size i konfigurationsfilen postgresql.conf.
En parameter som vi behöver ställa in när vi konfigurerar alla våra TimescaleDB-installationer är wal_level. Det avgör hur mycket information som skrivs till WAL. Standardvärdet är minimalt, vilket bara skriver den information som behövs för att återhämta sig efter en krasch eller omedelbar avstängning. Arkiv lägger till loggning som krävs för WAL-arkivering; hot_standby lägger ytterligare till information som krävs för att köra skrivskyddade frågor på en standby-server; och slutligen lägger logical till information som är nödvändig för att stödja logisk avkodning. Den här parametern kräver en omstart, så det kan vara svårt att ändra på att köra produktionsdatabaser om vi har glömt det.
Strömmande replikering
Strömmande replikering baseras på loggleveransmetoden. WAL-posterna flyttas direkt från en databasserver till en annan för att tillämpas. Vi kan säga att det är en kontinuerlig PITR.
Denna överföring utförs på två olika sätt, genom att överföra WAL-poster en fil (WAL-segment) åt gången (filbaserad loggsändning) och genom att överföra WAL-poster (en WAL-fil består av WAL-poster) i farten (rekordsbaserad log shipping), mellan en masterserver och en eller flera slavservrar, utan att vänta på att WAL-filen ska fyllas i.
I praktiken kommer en process som kallas WAL-mottagare, som körs på slavservern, att ansluta till masterservern med en TCP/IP-anslutning. I masterservern finns en annan process, som heter WAL-avsändaren, och som ansvarar för att skicka WAL-registren till slavservern när de händer.
Strömmande replikering kan representeras enligt följande:
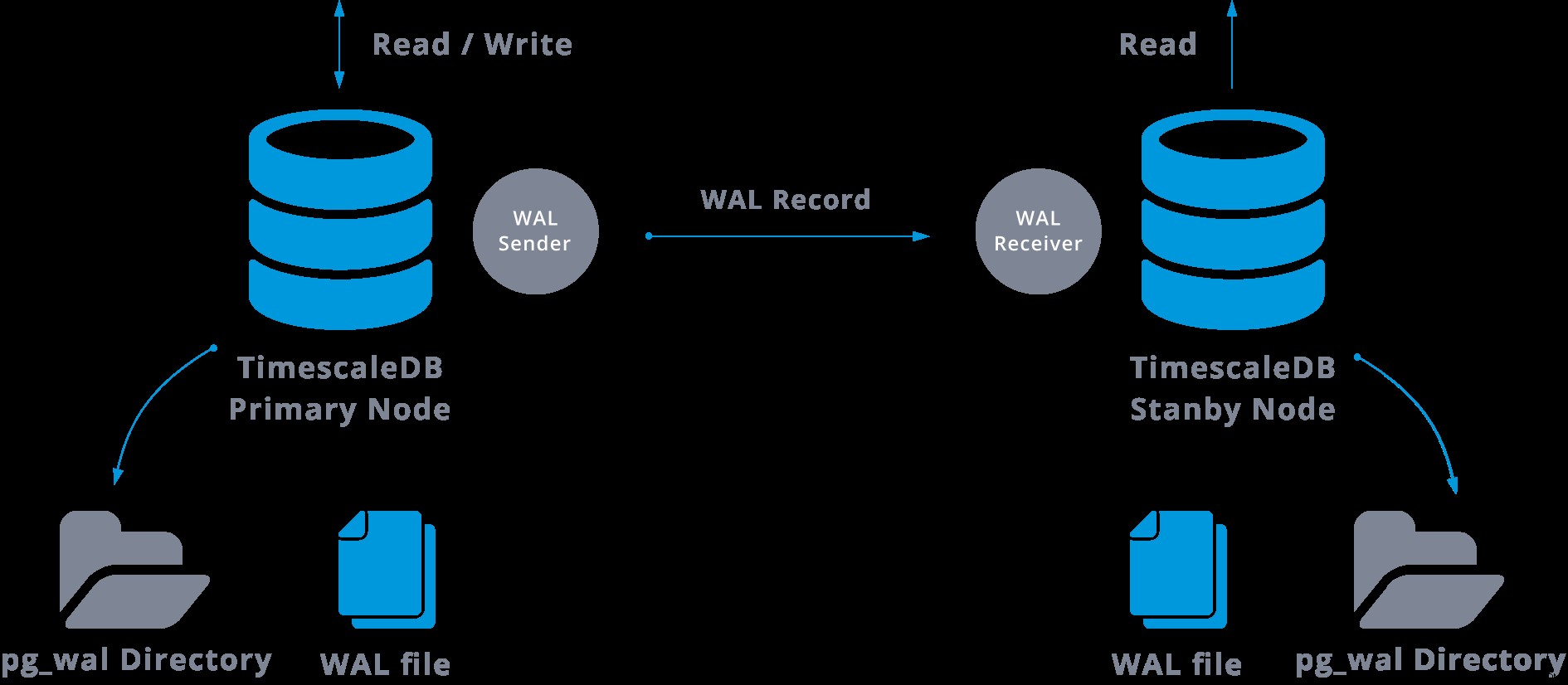
Genom att titta på diagrammet ovan kan vi tänka, vad händer när kommunikationen mellan WAL-sändaren och WAL-mottagaren misslyckas?
När vi konfigurerar strömmande replikering har vi möjlighet att aktivera WAL-arkivering.
Detta steg är faktiskt inte obligatoriskt, men är extremt viktigt för robust replikeringsinställning, eftersom det är nödvändigt att undvika att huvudservern återvinner gamla WAL-filer som ännu inte har applicerats på slaven. Om detta inträffar måste vi återskapa repliken från början.
När vi konfigurerar replikering med kontinuerlig arkivering, utgår vi från en säkerhetskopia och för att nå synkroniseringstillståndet med mastern måste vi tillämpa alla ändringar som finns i WAL som hände efter säkerhetskopieringen. Under denna process kommer vänteläget först att återställa all tillgänglig WAL på arkivplatsen (görs genom att anropa restore_command). Restore_command kommer att misslyckas när vi når den senast arkiverade WAL-posten, så efter det kommer vänteläget att titta på pg_wal-katalogen för att se om ändringen finns där (detta görs faktiskt för att undvika dataförlust när masterservrarna kraschar och vissa ändringar som redan har flyttats in i repliken och tillämpats där har ännu inte arkiverats).
Om det misslyckas och den begärda posten inte finns där, kommer den att börja kommunicera med mastern genom strömmande replikering.
Närhelst strömmande replikering misslyckas, går den tillbaka till steg 1 och återställer posterna från arkivet igen. Denna loop med hämtning från arkivet, pg_wal och via strömmande replikering fortsätter tills servern stoppas eller failover utlöses av en triggerfil.
Detta kommer att vara ett diagram över sådan konfiguration:
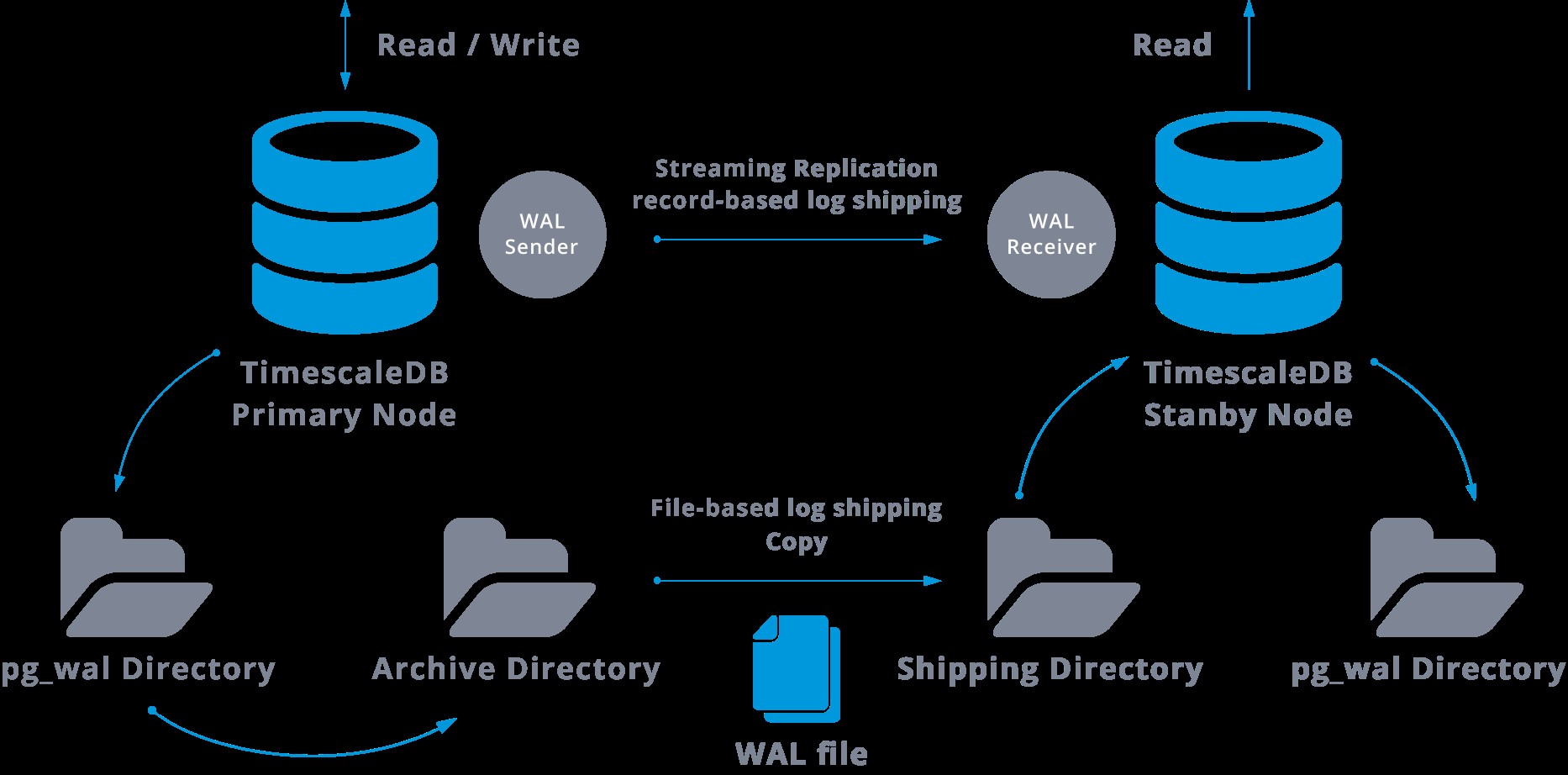
Strömmande replikering är asynkron som standard, så vid ett visst tillfälle kan vi ha några transaktioner som kan utföras i mastern och ännu inte replikeras till standby-servern. Detta innebär en viss potentiell dataförlust.
Denna fördröjning mellan commit och effekten av ändringarna i repliken ska dock vara väldigt liten (några millisekunder), givetvis förutsatt att replikservern är tillräckligt kraftfull för att hålla jämna steg med belastningen.
I de fall då risken för en liten dataförlust inte är tolerabel kan vi använda funktionen för synkron replikering.
I synkron replikering kommer varje commit av en skrivtransaktion att vänta tills bekräftelse tas emot att commit har skrivits till skriv-ahead-loggen på disken på både den primära och standby-servern.
Den här metoden minimerar risken för dataförlust, eftersom för att det ska hända måste både master och standby misslyckas samtidigt.
Den uppenbara nackdelen med denna konfiguration är att svarstiden för varje skrivtransaktion ökar, eftersom vi måste vänta tills alla parter har svarat. Så tiden för en commit är åtminstone en tur och retur mellan befälhavaren och repliken. Skrivskyddade transaktioner kommer inte att påverkas av det.
För att ställa in synkron replikering måste vi för var och en av standby-servrarna ange ett application_name i filen primary_conninfo för recovery.conf:primary_conninfo ='...aplication_name=slaveX' .
Vi måste också specificera listan över standby-servrar som kommer att delta i den synkrona replikeringen:synchronous_standby_name ='slaveX,slaveY'.
Vi kan ställa in en eller flera synkrona servrar, och den här parametern anger också vilken metod (FÖRSTA och NÅGON) för att välja synkrona väntelägen från de listade.
För att distribuera TimescaleDB med strömmande replikeringsinställningar (synkron eller asynkron), kan vi använda ClusterControl, som vi kan se här.
När vi har konfigurerat vår replikering, och den är igång, kommer vi att behöva ha några ytterligare funktioner för övervakning och säkerhetskopiering. ClusterControl låter oss övervaka och hantera säkerhetskopior/lagring av vårt TimescaleDB-kluster från samma plats utan något externt verktyg.
Hur man konfigurerar strömmande replikering på TimescaleDB
Att ställa in streamingreplikering är en uppgift som kräver att vissa steg måste följas noggrant. Om du vill konfigurera det manuellt kan du följa vår blogg om detta ämne.
Du kan dock distribuera eller importera din nuvarande TimescaleDB på ClusterControl, och sedan kan du konfigurera strömmande replikering med några få klick. Låt oss se hur vi kan göra det.
För den här uppgiften antar vi att du har ditt TimescaleDB-kluster som hanteras av ClusterControl. Gå till ClusterControl -> Välj Cluster -> Cluster Actions -> Add Replication Slave.
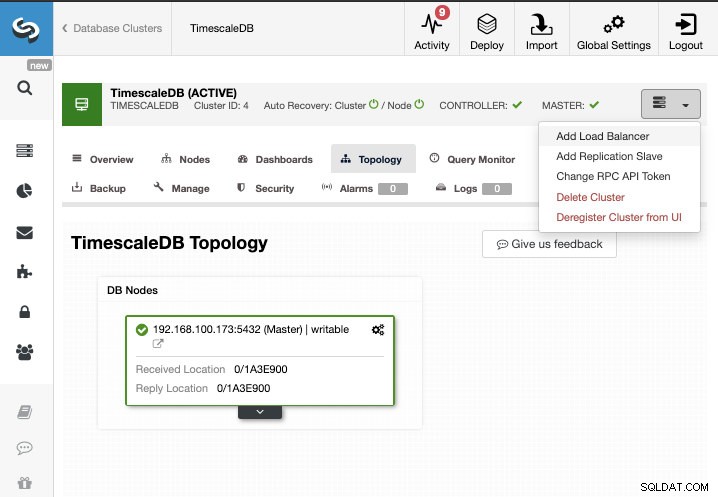
Vi kan skapa en ny replikeringsslav (standby) eller så kan vi importera en befintlig. I det här fallet skapar vi en ny.
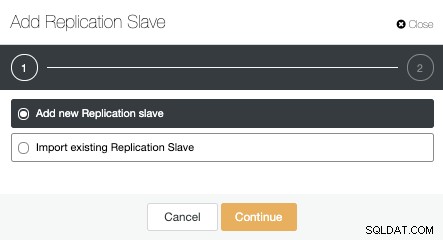
Nu måste vi välja masternoden, lägga till IP-adressen eller värdnamnet för den nya standbyservern och databasporten. Vi kan också ange om vi vill att ClusterControl ska installera programvaran och om vi vill konfigurera synkron eller asynkron streamingreplikering.
Det är allt. Vi behöver bara vänta tills ClusterControl avslutar jobbet. Vi kan övervaka statusen från aktivitetssektionen.
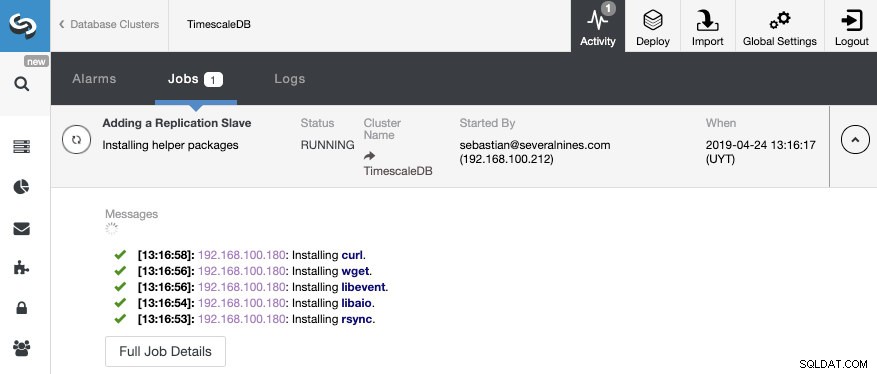
När jobbet har slutförts bör vi ha strömningsreplikeringen konfigurerad och vi kan kontrollera den nya topologin i avsnittet ClusterControl Topology View.
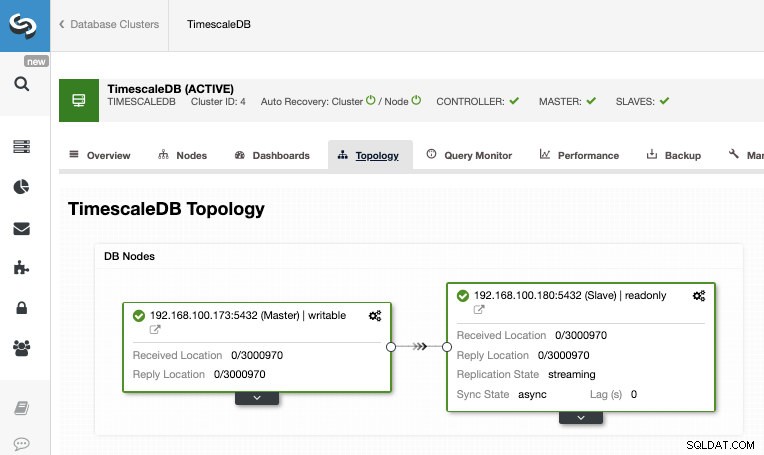
Genom att använda ClusterControl kan du också utföra flera hanteringsuppgifter på din TimescaleDB som säkerhetskopiering, övervakning och varning, automatisk failover, lägga till noder, lägga till lastbalanserare och ännu mer.
Failover
Som vi kunde se använder TimescaleDB en ström av WAL-poster (Write-ahead Log) för att hålla standby-databaserna synkroniserade. Om huvudservern misslyckas innehåller standby-läget nästan all data från huvudservern och kan snabbt göras till den nya huvuddatabasservern. Detta kan vara synkront eller asynkront och kan endast göras för hela databasservern.
För att effektivt säkerställa hög tillgänglighet räcker det inte med en master-standby-arkitektur. Vi måste också aktivera någon automatisk form av failover, så om något misslyckas kan vi ha minsta möjliga fördröjning med att återuppta normal funktionalitet.
TimescaleDB inkluderar inte en automatisk failover-mekanism för att identifiera fel på masterdatabasen och meddela slaven att ta äganderätten, så det kommer att kräva lite arbete på DBA:s sida. Du kommer också att ha bara en server som fungerar, så återskapandet av master-standby-arkitekturen måste göras, så vi kommer tillbaka till samma normala situation som vi hade innan problemet.
ClusterControl inkluderar en automatisk failover-funktion för TimescaleDB för att förbättra medeltiden till reparation (MTTR) i din miljö med hög tillgänglighet. I händelse av misslyckande kommer ClusterControl att marknadsföra den mest avancerade slaven till master, och den kommer att konfigurera om de återstående slaverna för att ansluta till den nya mastern. HAProxy kan också distribueras automatiskt för att erbjuda en enda databasslutpunkt till applikationer, så att de inte påverkas av en förändring av huvudservern.
Begränsningar
Relaterade resurser ClusterControl for TimescaleDB Hur man enkelt distribuerar TimescaleDB PostgreSQL Streaming Replication - a Deep DiveVi har några välkända begränsningar när vi använder Streaming Replication:
- Vi kan inte replikera till en annan version eller arkitektur
- Vi kan inte ändra något på standbyservern
- Vi har inte mycket granularitet i vad vi kan replikera
Så för att övervinna dessa begränsningar har vi den logiska replikeringsfunktionen. Om du vill veta mer om denna replikeringstyp kan du läsa följande blogg.
Slutsats
En master-standby-topologi har många olika användningsområden som analys, backup, hög tillgänglighet, failover. I alla fall är det nödvändigt att förstå hur streamingreplikeringen fungerar på TimescaleDB. Det är också användbart att ha ett system för att hantera hela klustret och för att ge dig möjligheten att skapa denna topologi på ett enkelt sätt. I den här bloggen såg vi hur man uppnår det genom att använda ClusterControl, och vi har granskat några grundläggande koncept om strömmande replikering.