När jag felsöker CPU-prestandaproblem på virtualiserade SQL-servrar som körs på VMware, är en av de första sakerna jag gör att verifiera att den virtuella maskinens konfiguration inte är en bidragande faktor till prestandaproblemet. Där en fysisk server har 100 % av de tillgängliga resurserna dedikerade till operativsystemet, gör inte en virtuell maskin det, så att titta på några grundläggande objekt i förväg eliminerar felsökning av fel problem och slöseri med tid. Tidigare har jag bloggat om vikten av att DBA:er har skrivskyddad tillgång till Virtual Center for VMware för grundläggande felsökning av prestandaproblem. Men även utan tillgång till Virtual Center är det fortfarande möjligt att ta reda på en del grundläggande information inuti Windows som kan leda till potentiella värdnivåproblem som påverkar prestandan.
Varje virtuell VMware-maskin har två prestandaräknargrupper i Windows som läggs till när VMware-verktygen installeras i gästen; VM-processor och VM-minne. Dessa prestandaräknare är en av de första sakerna jag tittar på när jag arbetar med en virtuell maskin på VMware, eftersom de ger dig en titt på vilka resurser den virtuella datorn tar emot från hypervisorn. VM-processorgruppen har följande räknare:
- % processortid
- Effektiv VM-hastighet i MHz
- Värdprocessorhastighet i MHz
- Gräns i MHz
- Reservation i MHz
- Delningar
På en VM-gäst som visar en hög Processor\% Processortid i Aktivitetshanteraren eller perfmon, kommer en kontroll av VM-processorns räknare att ge en korrekt redovisning av faktiska resurstilldelningar som VM-gästen tar emot. Om värdprocessorns hastighet i MHz är 3 000 och gästen har 8 virtuella processorer tilldelade till den, är den maximala effektiva hastigheten för den virtuella datorn 24 000 MHz och den effektiva VM-hastigheten i MHz kommer att återspegla om den virtuella datorn faktiskt får resurserna från värden. Vanligtvis när så är fallet måste du börja titta på värdnivåinformationen för att diagnostisera grundorsaken till problemet ytterligare. Men i ett kundengagemang nyligen visade det sig inte vara fallet.
Klient-VM i det här fallet matchade konfigurationen som beskrivs ovan och hade en maximal effektiv hastighet på 24000 MHz, men den effektiva VM-hastigheten i MHz-räknaren var endast i genomsnitt runt 6900 MHz med VM Windows Procent Processor-tid kopplad till nästan 100 %. Att titta strax under den effektiva VM-hastigheten i MHz-räknaren avslöjade orsaken till problemet:gränsen i MHz var 7000, vilket betyder att den virtuella datorn hade ett konfigurerat gränsvärde för CPU-användning på 7000MHz i ESX, så den strypts konsekvent av hypervisorn under ladda.
Förklaringen till detta var att just denna virtuella dator hade använts för teständamål i ett proof of concept och ursprungligen var samlokaliserad på en upptagen virtuell datorvärd; VM-administratörerna ville inte ha en okänd arbetsbelastning som orsakade prestandaproblem på den värden. Så för att säkerställa att det inte skulle påverka den verkliga produktionsbelastningen på värden negativt under POC, var den begränsad till att endast tillåta 7000 MHz CPU eller motsvarande 2 1/3 fysiska kärnor på värden. I slutändan eliminerades de höga CPU-problemen i Windows genom att ta bort VM CPU-gränsen i ESX, och prestandaproblemen som klienten upplevde försvann.
VM-minnesräknargruppen är lika viktig som VM-processorgruppen för att identifiera potentiella prestandaproblem för SQL Server. VM-minnesräknargruppen innehåller följande räknare:
- Minne aktivt i MB
- Minnesballong i MB
- Minnesgräns i MB
- Minne mappat i MB
- Minnesoverhead i MB
- Minnesreservation i MB
- Delat minne i MB
- Delat minne sparat i MB
- Minnesdelning
- Minne bytt i MB
- Minne som används i MB
Av dessa räknare är de som jag specifikt tittar på Memory Ballooned i MB och Memory Swapped i MB, som båda bör vara noll för SQL Server-arbetsbelastningar. Räknaren Memory Ballooned in MB talar om hur mycket minne som har tagits tillbaka från gäst-VM av ballongdrivrutinen på grund av minnesöverdrift på värden, vilket kommer att få SQL Server att minska minnesanvändningen för att svara på minnestrycket i Windows orsakat av ballongdrivrutinen blåsa upp för att ta minnet från den virtuella datorn. Räknaren Memory Swapped in MB spårar hur mycket minne som söktes till disken av värdhypervisorn på grund av minnesöverbelastning på värden som inte kunde lösas genom att ballongföra VM-gäster med ballongdrivrutinen. VMwares guide för bästa tillvägagångssätt för SQL Server rekommenderar att du använder reservationer för att garantera att SQL Server inte sprängs eller sänds ut av prestandaskäl, men många VM-administratörer är tveksamma till att ställa in statiska reservationer eftersom det minskar miljöflexibiliteten.
Övervakningsverktyg, som SentryOne V Sentry, kan också hjälpa. Tänk på fallet där du kanske inte har direkt tillgång till vCenter, men någon kan ställa in övervakning mot det för din räkning. Nu kan du få fantastisk visualisering och insikt i CPU, minne och till och med diskproblem – på både gäst- och värdnivå – och all historik som kommer med det också. På instrumentpanelen nedan kan du se värdstatistik till vänster (inklusive CPU-avbrott för co-stop och redo tid), och gäststatistik till höger:
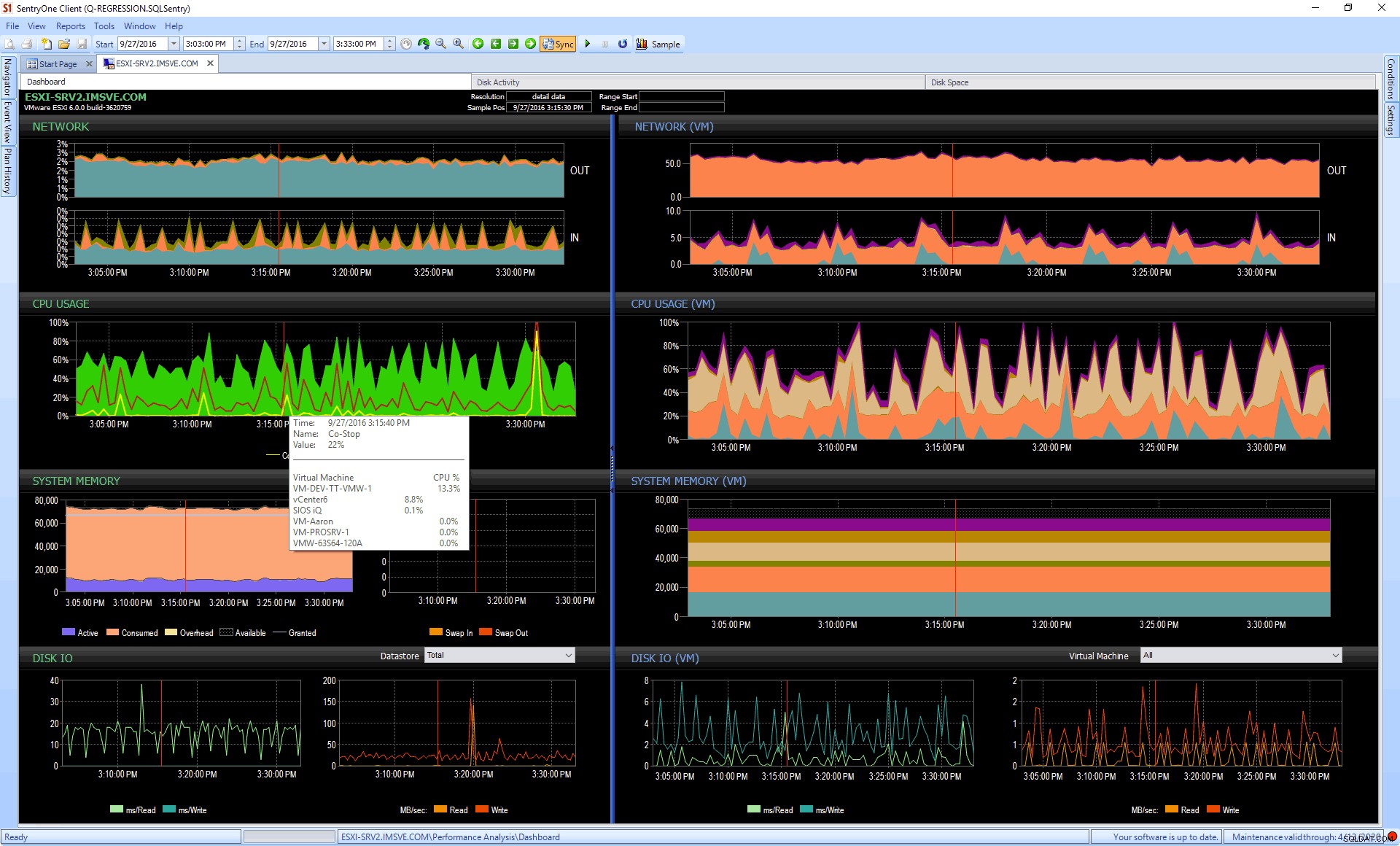
För att prova denna och andra funktioner från SentryOne kan du ladda ner en gratis provversion.
Slutsats
När du felsöker prestandaproblem på virtualiserade SQL-servrar på VMware är det viktigt att se på problemet ur en holistisk synvinkel istället för att göra en "knee-jerk" felsökning med endast begränsad information. De VMware-specifika räknarna i Performance Monitor kan vara ett utmärkt sätt att snabbt verifiera att den virtuella datorn får de grundläggande resurstilldelningarna från värden innan du vidtar ytterligare steg för att felsöka problemet.