Den ökande efterfrågan på system med hög tillgänglighet och snäva SLA:er driver oss att ersätta manuella procedurer med automatiserade lösningar. Men har du tid och nödvändiga resurser för att själv ta itu med komplexiteten i failover-operationer? Kommer du att offra driftstopptid för produktionsdatabasen för att lära dig det på den hårda vägen?
ClusterControl ger avancerat stöd för feldetektering och hantering. Det används av många företagsorganisationer och håller de mest kritiska produktionssystemen igång i 24/7-läge.
Den här databashanteringslösningen stöder dig även med distributionen av olika laddningsproxyer. Dessa proxyservrar spelar en nyckelroll i HA-stacken så det finns inget behov av att justera programanslutningssträngen eller DNS-posten för att omdirigera programanslutningar till den nya huvudnoden.
När ett fel upptäcks utför ClusterControl allt bakgrundsarbete för att välja en ny master, distribuera fail-over-slavservrar och konfigurera lastbalanserare. I den här bloggen kommer du att lära dig hur du uppnår automatisk failover av TimescaleDB i dina produktionssystem.
Distribuera hela replikeringstopologier
Med utgångspunkt från ClusterControl 1.7.2 kan du distribuera en hel TimescaleDB-replikeringsinställning på samma sätt som du skulle distribuera PostgreSQL:du kan använda menyn "Deploy Cluster" för att distribuera en primär och en eller flera TimescaleDB standby-servrar. Låt oss se hur det ser ut.
Först måste du definiera åtkomstdetaljer när du distribuerar nya kluster med ClusterControl. Det kräver root- eller sudo-lösenordsåtkomst till alla noder där ditt nya kluster kommer att distribueras.
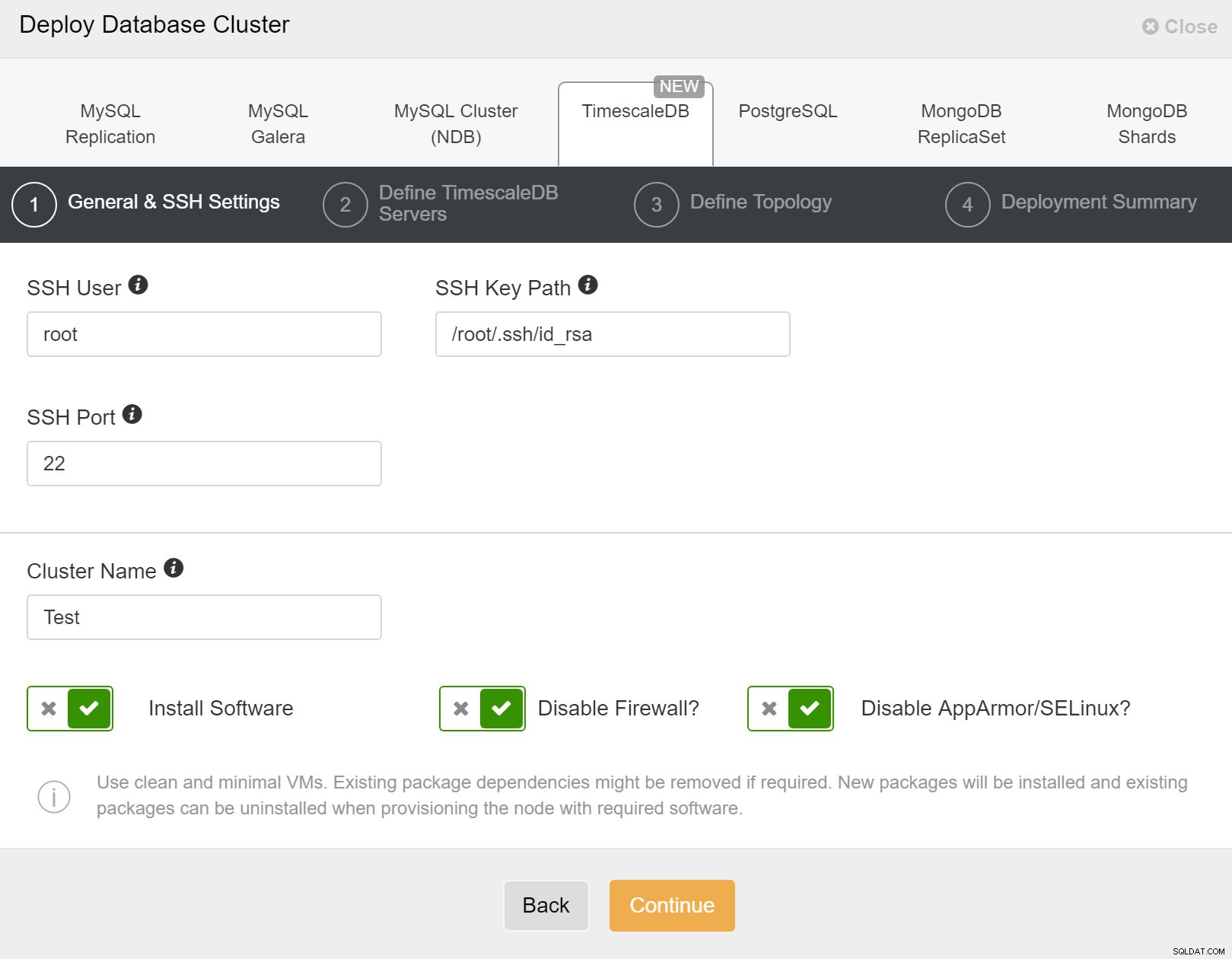 ClusterControl:Implementera nytt kluster
ClusterControl:Implementera nytt kluster Därefter måste vi definiera användaren och lösenordet för TimescaleDB-användaren.
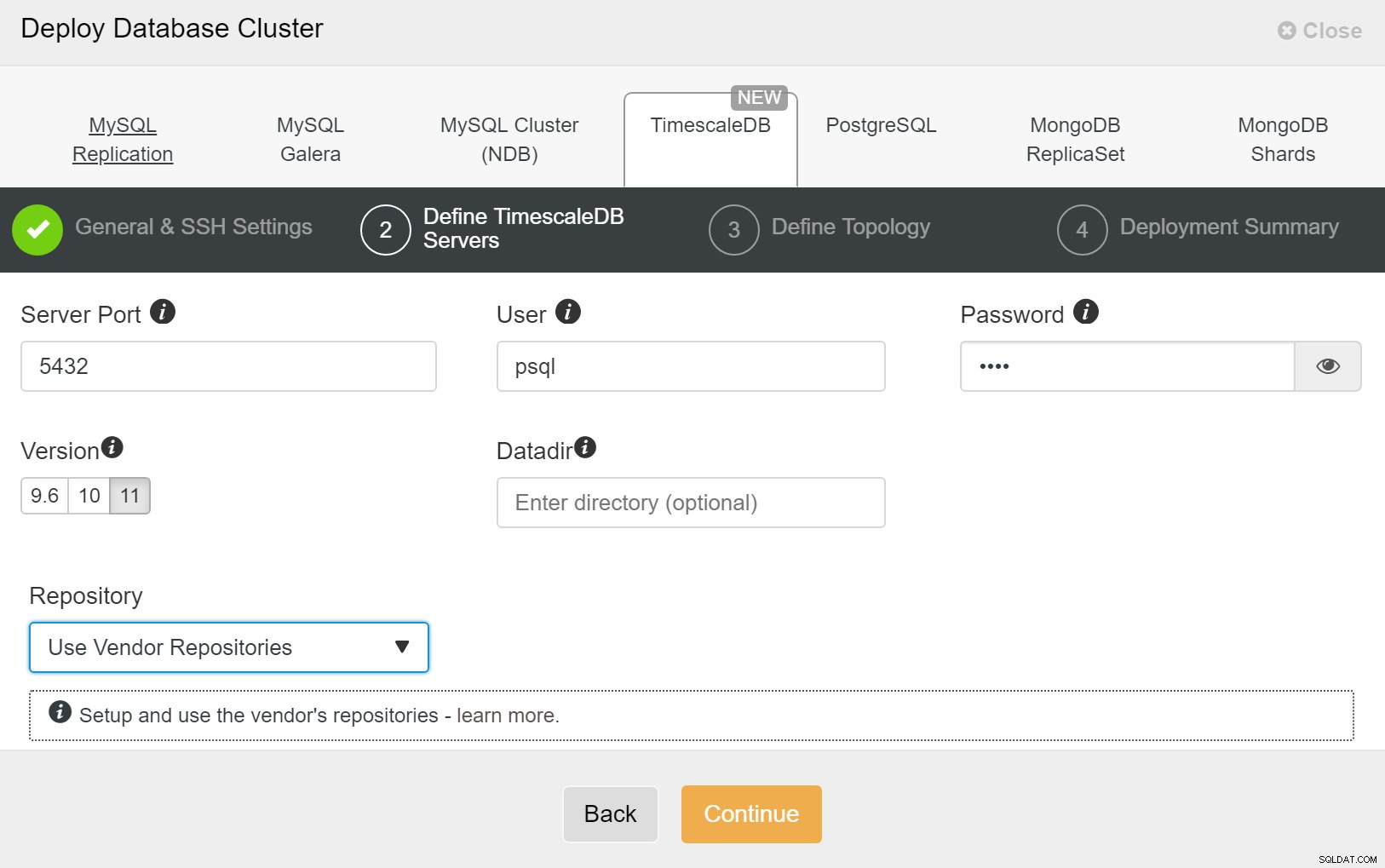 ClusterControl:Distribuera databaskluster
ClusterControl:Distribuera databaskluster Slutligen vill du definiera topologin - vilken värd som ska vara den primära och vilka värdar som ska konfigureras som standby. Medan du definierar värdar i topologin kommer ClusterControl att kontrollera om ssh-åtkomsten fungerar som förväntat - detta låter dig fånga eventuella anslutningsproblem tidigt. På den sista skärmen kommer du att bli tillfrågad om typen av replikering synkron eller asynkron.
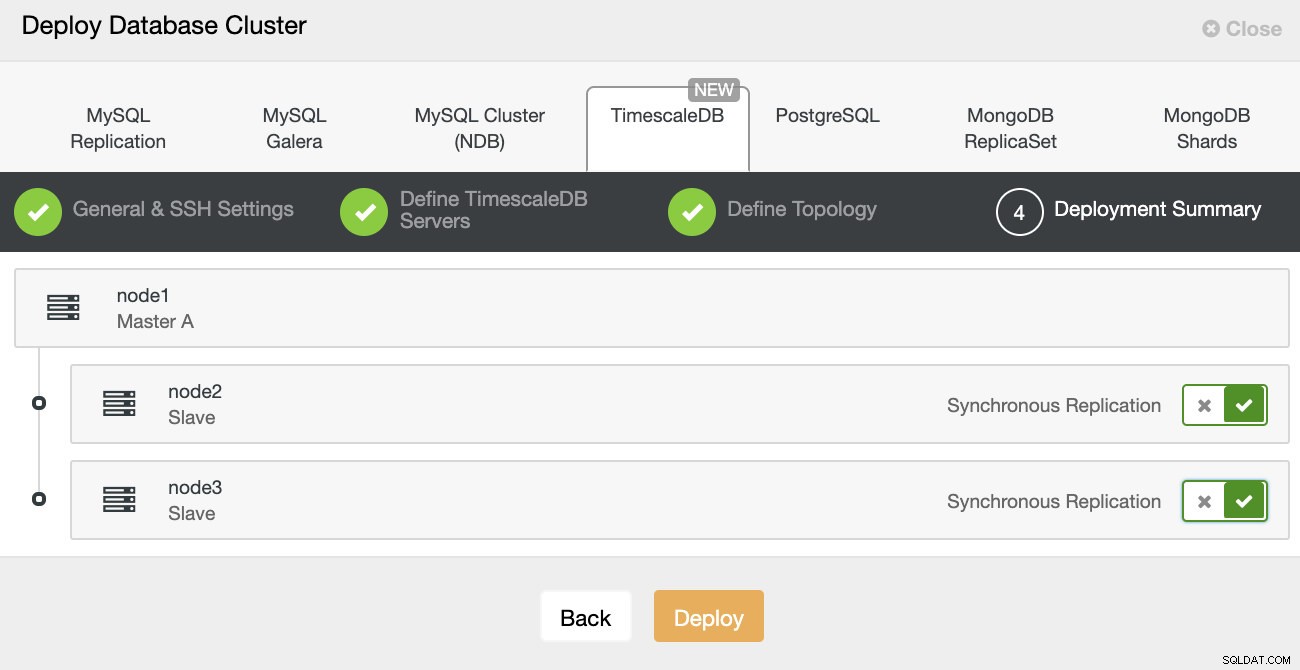 ClusterControl-distribution
ClusterControl-distribution Det är det, det är sedan en fråga om att börja utplaceringen. Ett jobb skapas i ClusterControl och du kommer att kunna följa utvecklingen.
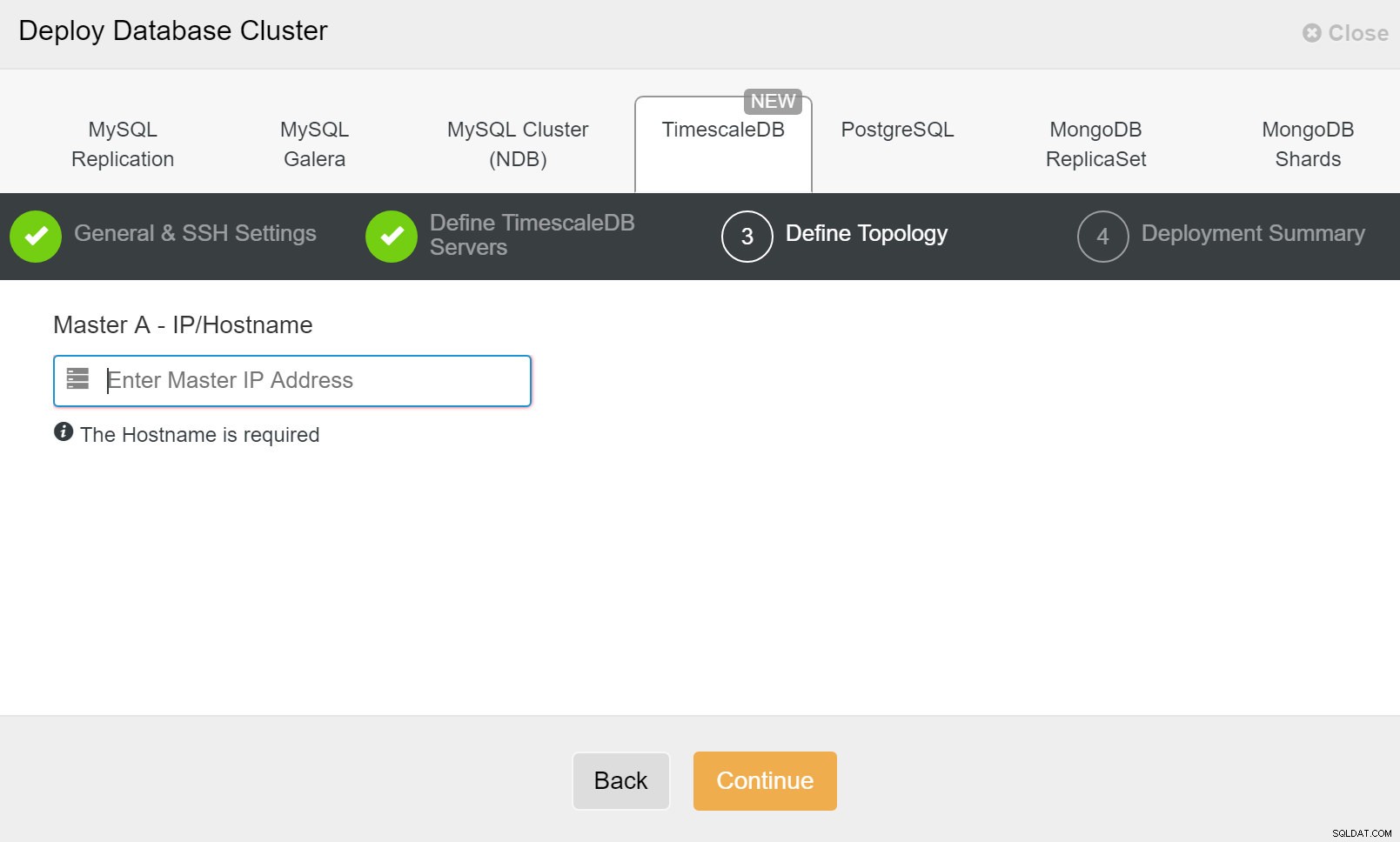 ClusterControl:Definiera topologi för TimescleDb-klustret
ClusterControl:Definiera topologi för TimescleDb-klustret När du är klar kommer du att se topologiinställningen med roller i klustret. Observera att vi också har lagt till en lastbalanserare (HAProxy) framför databasinstanserna så att den automatiska failover inte kräver ändringar i databasanslutningsinställningarna.
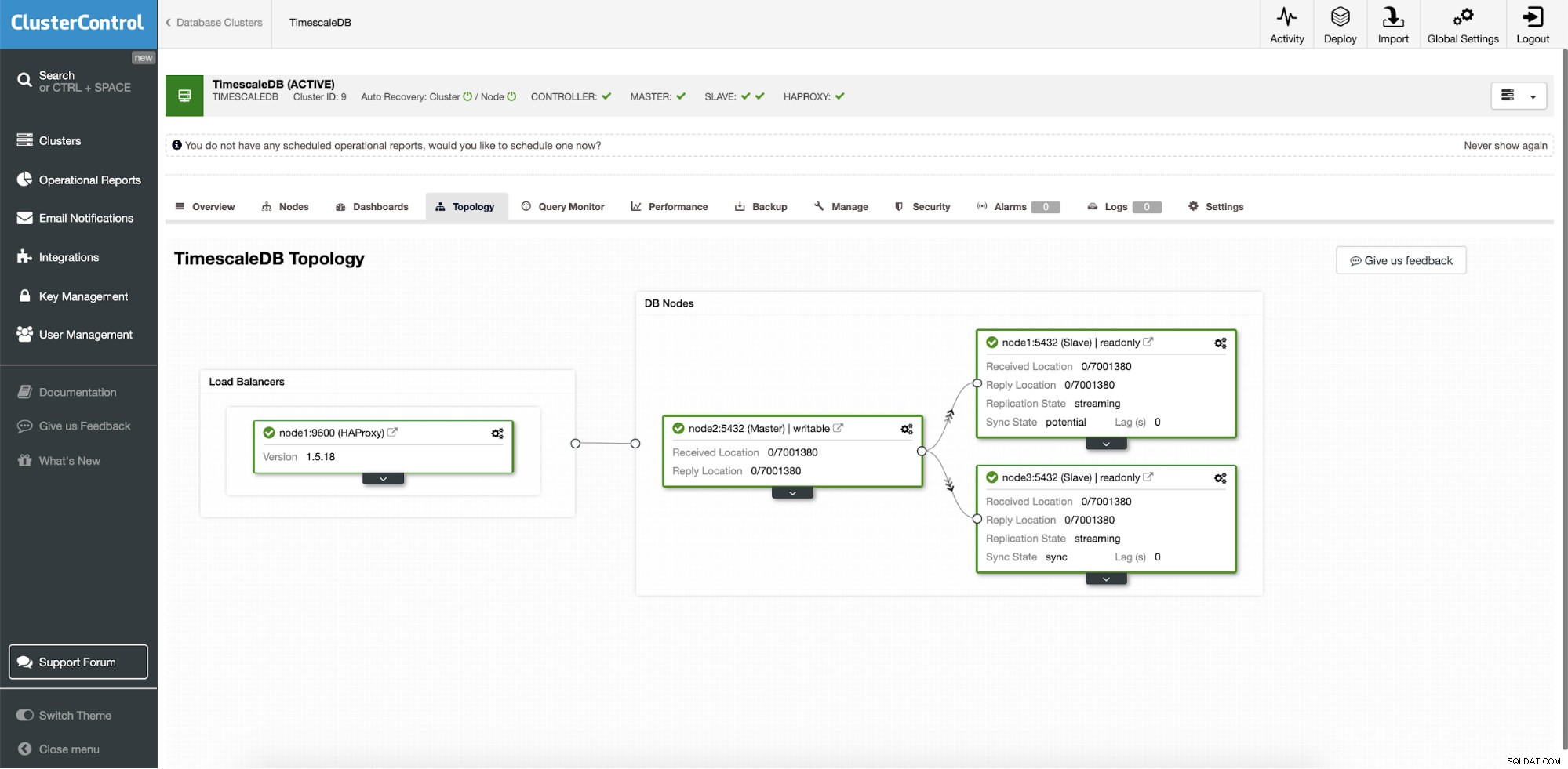 ClusterControl:Topologi
ClusterControl:Topologi När Timescale distribueras av ClusterControl är automatisk återställning aktiverad som standard. Tillståndet kan kontrolleras i klusterfältet.
 ClusterControl:Auto Recovery Cluster and Node state
ClusterControl:Auto Recovery Cluster and Node state Failover-konfiguration
När replikeringsinställningen har distribuerats kan ClusterControl övervaka installationen och automatiskt återställa eventuella servrar som inte fungerar. Den kan också orkestrera förändringar i topologi.
ClusterControls automatiska failover utformades med följande principer:
- Se till att mastern verkligen är död innan du failover
- Filover endast en gång
- Failover inte till en inkonsekvent slav
- Skriv bara till mastern
- Återställ inte den misslyckade mastern automatiskt
Med de inbyggda algoritmerna kan failover ofta utföras ganska snabbt så att du kan säkerställa de högsta SLA:erna för din databasmiljö.
Processen är konfigurerbar. Den levereras med flera parametrar som du kan använda för att anpassa återställningen till din miljös specifikationer.
| max_replication_lag | Max tillåten replikeringsfördröjning i sekunder innan |
| replication_stop_on_error | Failover/växlingsprocedurer kommer att misslyckas om fel uppstår som kan orsaka dataförlust. Aktiverad som standard. 0 betyder inaktivera, |
| replication_auto_rebuild_slave | Om SQL THREAD stoppas och felkoden inte är noll så kommer slaven att byggas om automatiskt. 1 betyder aktivera, 0 betyder inaktivera (standard). |
| replication_failover_blacklist | Kommaseparerad lista över värdnamn:portpar. Svartlistade servrar kommer inte att betraktas som en kandidat under failover. replication_failover_blacklist ignoreras om replication_failover_whitelist är inställd. |
| replication_failover_whitelist | Kommaseparerad lista över värdnamn:portpar. Endast vitlistade servrar kommer att betraktas som en kandidat under failover. Om ingen server på vitlistan är tillgänglig (upp/ansluten) kommer failover att misslyckas. replication_failover_blacklist ignoreras om replication_failover_whitelist är inställd. |
Failover-hantering
När ett masterfel upptäcks skapas en lista med masterkandidater och en av dem väljs till den nya mastern. Det är möjligt att ha en vitlista över servrar att främja till primär, samt en svartlista över servrar som inte kan flyttas upp till primär. De återstående slavarna är nu slavar från den nya primära, och den gamla primära startas inte om.
Nedan kan vi se en simulering av nodfel.
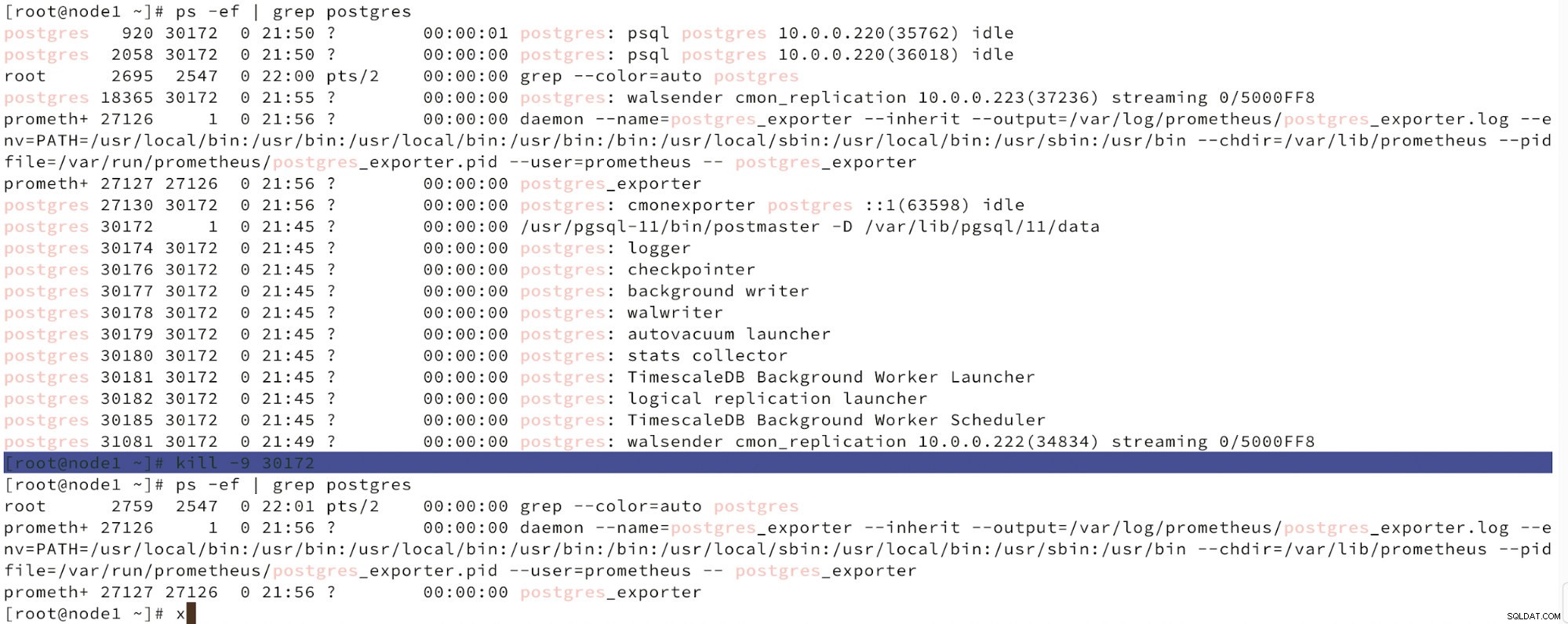 Simulera masternodfel med kill
Simulera masternodfel med kill När nodfel upptäcks och automatisk återställning upptäcks utlöser ClusterControl jobbet för att utföra failover. Nedan kan vi se åtgärder som vidtagits för att återställa klustret.
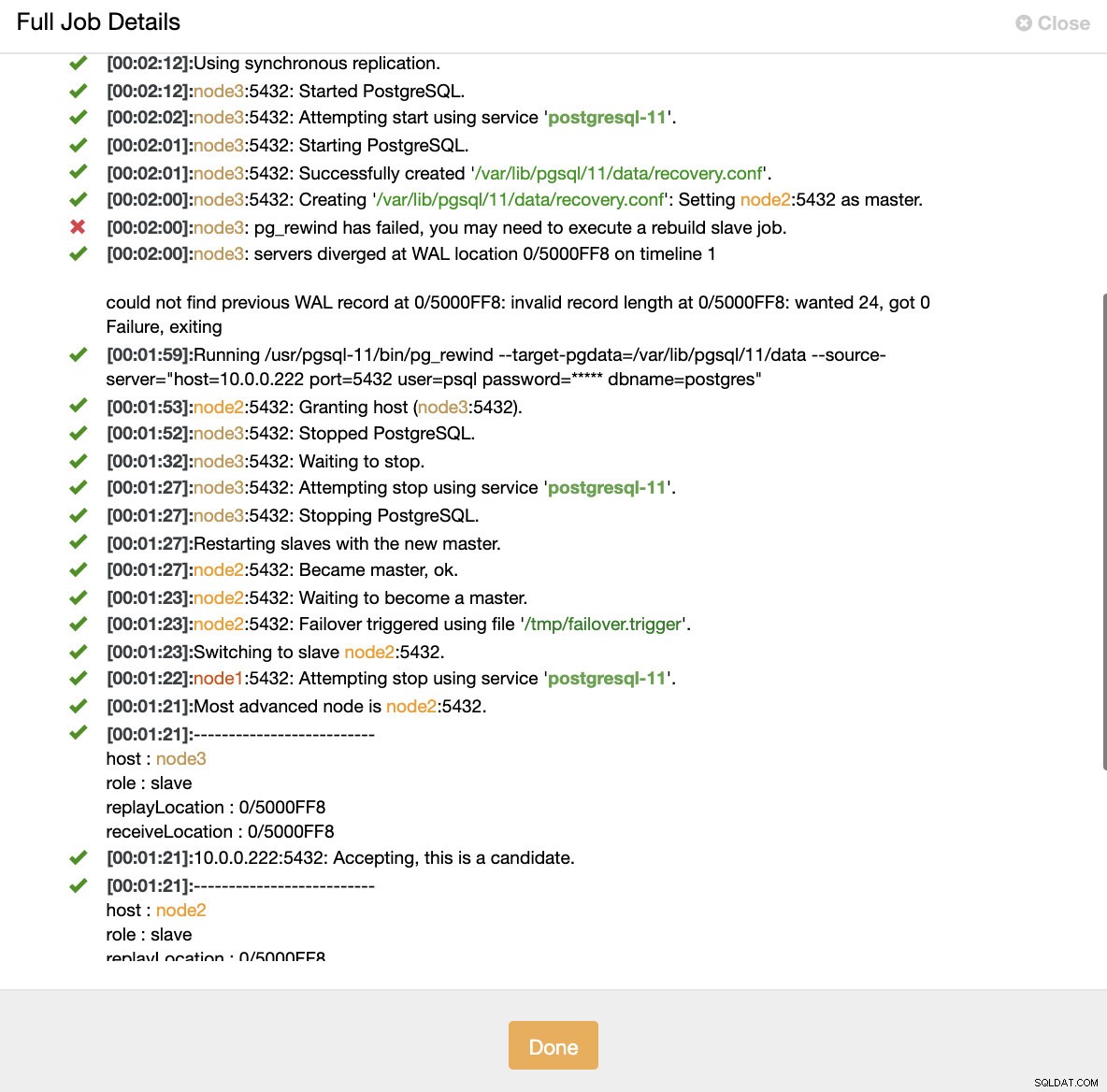 ClusterControl:Jobb utlöstes för att bygga om klustret
ClusterControl:Jobb utlöstes för att bygga om klustret ClusterControl håller avsiktligt den gamla primära offline eftersom det kan hända att en del av datan inte har överförts till standbyservrarna. I ett sådant fall är den primära den enda värden som innehåller dessa data och du kanske vill återställa de saknade data manuellt. För dem som vill få den misslyckade primära automatiskt återuppbyggd, finns det ett alternativ i cmon-konfigurationsfilen:replication_auto_rebuild_slave. Som standard är den inaktiverad men när användaren aktiverar den kommer den misslyckade primära enheten att byggas om som en slav av den nya primära. Naturligtvis, om det saknas data som bara finns på den misslyckade primära, kommer denna data att gå förlorad.
Återbygga standby-servrar
En annan funktion är "Rebuild Replication Slave"-jobbet som är tillgängligt för alla slavar (eller standby-servrar) i replikeringsinställningen. Detta ska användas till exempel när du vill rensa ut data i vänteläge och bygga om den igen med en ny kopia av data från den primära. Det kan vara fördelaktigt om en standby-server inte kan ansluta och replikera från den primära av någon anledning.
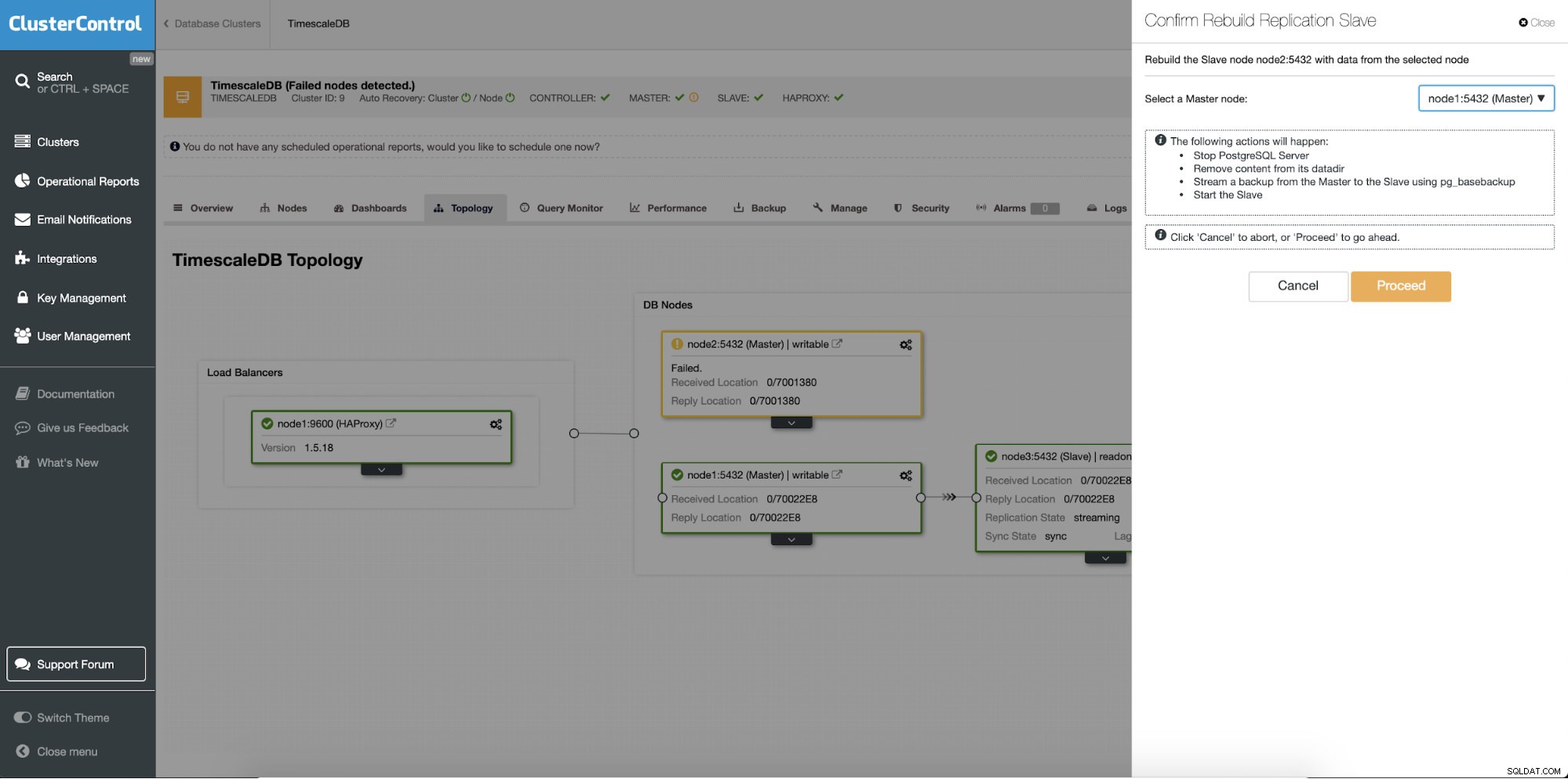 ClusterControl:Bygg om replikeringsslav
ClusterControl:Bygg om replikeringsslav  ClusterControl:Bygg om slav
ClusterControl:Bygg om slav