Huvudmålet med dennaHadoop Tutorial är att ge dig en detaljerad beskrivning av varje komponent som används i Hadoop-arbete. I den här handledningen kommer vi att täcka partitioneraren i Hadoop.
Vad är Hadoop Partitioner, vad är behovet av Partitioner i Hadoop, Vad är standardpartitioner i MapReduce, hur många MapReduce Partitioner används i Hadoop?
Vi kommer att svara på alla dessa frågor i denna MapReduce-handledning.
Vad är Hadoop Partitioner?
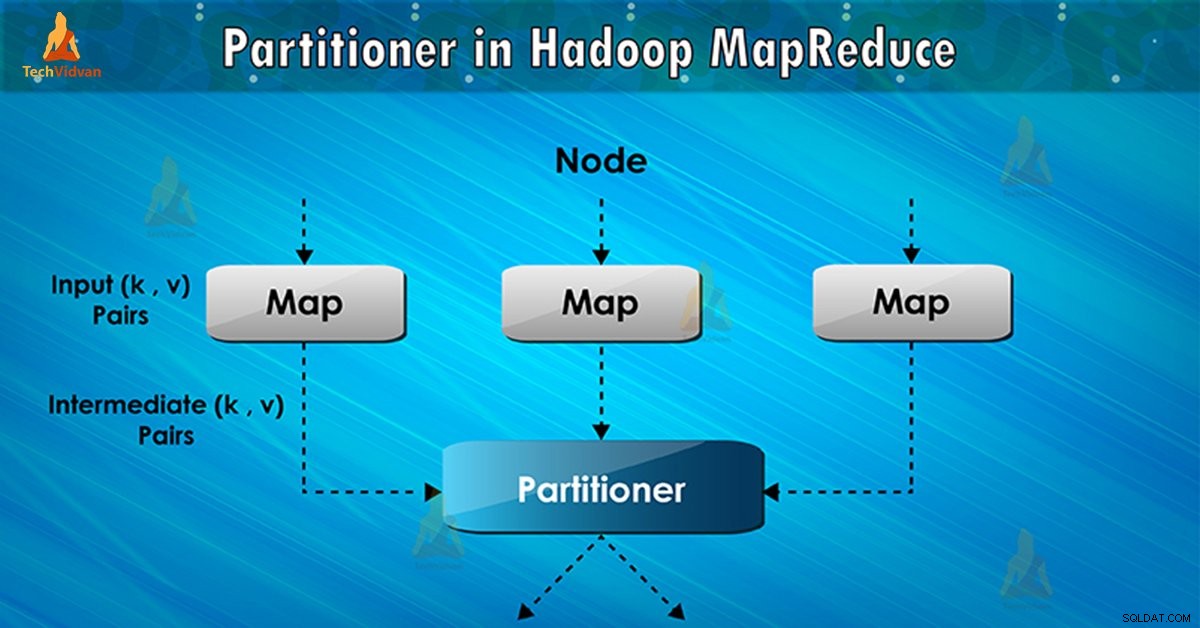
Partitionerare i MapReduce-jobbkörning kontrollerar partitioneringen av nycklarna för de mellanliggande kartutgångarna. Med hjälp av hash-funktionen härleder nyckel (eller en delmängd av nyckeln) partitionen. Det totala antalet partitioner är lika med antalet reduceringsuppgifter.
På basis av nyckelvärde , rampartitioner, varjemappare produktion. Poster som har samma nyckelvärde går in i samma partition (inom varje mappare). Sedan skickas varje partition till en reducer .
Partitionsklass bestämmer vilken partition ett givet (nyckel, värde) par ska gå. Partitionsfas i MapReduce-dataflödet sker efter kartfas och före reduceringsfas.
Behov av MapReduce Partitioner i Hadoop
I MapReduce-jobbkörning tar den en indatauppsättning och producerar listan med nyckelvärdespar. Dessa nyckel-värdepar är resultatet av kartfasen. Där indata delas upp och varje uppgift bearbetar uppdelningen och varje karta matar ut listan med nyckelvärdespar.
Sedan skickar ramverket kartutdata för att minska uppgiften. Minska processer den användardefinierade reduceringsfunktionen på kartutgångar. Innan reduceringsfasen sker partitionering av kartutdata på basis av nyckeln.
Hadoop Partitioning anger att alla värden för varje nyckel är grupperade tillsammans. Den ser också till att alla värden för en enda nyckel går till samma reducering. Detta möjliggör en jämn fördelning av kartutdata över reduceraren.
Partitionerare i ett MapReduce-jobb omdirigerar mapparens utdata till reduceraren genom att bestämma vilken reducerare som hanterar den specifika nyckeln.
Hadoop Default Partitioner
Hash Partitioner är standardpartitioneraren. Den beräknar ett hashvärde för nyckeln. Den tilldelar också partitionen baserat på detta resultat.
Hur många partitionerare i Hadoop?
Det totala antalet partitionerare beror på antalet reducerare. Hadoop Partitioner delar upp data efter antalet reducerare. Den ställs in av JobConf.setNumReduceTasks() metod.
Således bearbetar den enda reduceraren data från en enda partitionerare. Det viktiga att lägga märke till är att ramverket skapar partitioner endast när det finns många reducerare.
Dålig partitionering i Hadoop MapReduce
Om i datainmatning i MapReduce-jobb visas en nyckel mer än någon annan nyckel. I sådana fall använder vi två mekanismer för att skicka data till partitionen:
- Nyckeln som visas fler gånger kommer att skickas till en partition.
- Alla andra nyckel kommer att skickas till partitioner på basis av deras hashCode() .
Om hashCode() metoden distribuerar inte andra nyckeldata över partitionsintervallet. Då kommer inte data att skickas till reducerarna.
Dålig partitionering av data innebär att vissa reducerare kommer att ha mer datainmatning jämfört med andra. De kommer att ha mer att göra än andra reducerare. Alltså måste hela jobbet vänta på att en reducerare slutför sin extra stora del av lasten.
Hur övervinner man dålig partitionering i MapReduce?
För att övervinna dålig partitionerare i Hadoop MapReduce kan vi skapa anpassad partitionerare. Detta gör det möjligt att dela arbetsbelastning mellan olika reducerare.
Slutsats
Sammanfattningsvis tillåter Partitioner enhetlig fördelning av kartutdata över reduceraren. I MapReducer Partitioner sker partitionering av kartutdata på basis av nyckeln och värdet.
Därför har vi täckt den fullständiga översikten av Partitioner i den här bloggen. Hoppas du gillade det. Om du har några tvivel om Hadoop Partitioner, så glöm inte att dela med dig av det till oss.