I vår tidigare blogg har vi studerat Hadoop Introduktion och Funktioner i Hadoop , Nu i den här bloggen kommer vi att täcka HDFS NameNode High Availability-funktionen i detalj.
Först och främst kommer vi att diskutera HDFS NemNode High Availability Architecture, därefter med implementeringen av Hadoop High Availability Architecture med hjälp av Quorum Journal Nodes och Shared Storage.
HDFS NameNode High Availability
I HDFS , data är högt tillgänglig och tillgänglig trots maskinvarufel. HDFS är det mest pålitliga lagringssystemet designat för att lagra mycket stora filer.
HDFS följer master/slav topologi. I vilken master är NameNode och slavar är DataNode . NameNode lagrar metadata. Metadata inkluderar antalet block, deras plats, repliker och andra detaljer. För snabbare hämtning av data finns metadata tillgänglig i mastern. NameNode underhåller och tilldelar uppgifter till slavnoden.
NameNode var Single Point of Failure (SPOF) före Hadoop 2.0. HDFS-klustret hade en enda NameNode. Om NameNode misslyckas, försvinner hela klustret.
Single point of failure begränsar hög tillgänglighet på följande sätt:
- Om någon oplanerad händelse utlöser, som nodkraschar, skulle klustret vara otillgängligt om inte en operatör startade om den nya namnnoden.
- Också planerade underhållsaktiviteter som hårdvaruuppgraderingar på NameNode kommer att resultera i driftstopp för Hadoop-klustret.
HDFS NameNode High Availability Architecture
Introduktionen av Hadoop 2.0 övervinner dennaSPOF genom att ge stöd till flera NameNode. HDFS NameNode High Availability-arkitektur ger möjlighet att köra två redundanta NameNodes i samma kluster i en aktiv/passiv konfiguration med ett hot standby.
- Aktiv namnnod – Den hanterar alla HDFS-klientoperationer i HDFS-klustret.
- Passiv namnnod – Det är en standby-namnnod. Den har liknande data som aktiv NameNode.
Så, närhelst Active NameNode misslyckas, kommer passiv NameNode att ta allt ansvar för aktiv nod. Således fortsätter HDFS-klustret att fungera.
Problem med att upprätthålla konsekvens i HDFS High Availability-klustret är följande:
- Active och Standby NameNode ska alltid vara synkroniserade med varandra, d.v.s. de ska ha samma metadata. Detta tillstånd för att återställa Hadoop-klustret till samma namnområdestillstånd där det kraschade. Och detta kommer att ge oss snabb failover.
- Det bör bara finnas en NameNode aktiv åt gången. Annars kommer två NameNode att leda till korruption av data. Vi kallar det här scenariot som ett "Scenario med delad hjärna ”, där ett kluster delas upp i det mindre klustret. Var och en tror att det är det enda aktiva klustret. "Fäktning" undviker sådant. Fäktning är en process för att säkerställa att endast en NameNode förblir aktiv vid en viss tidpunkt.
Implementering av Hadoop High Availability Architecture
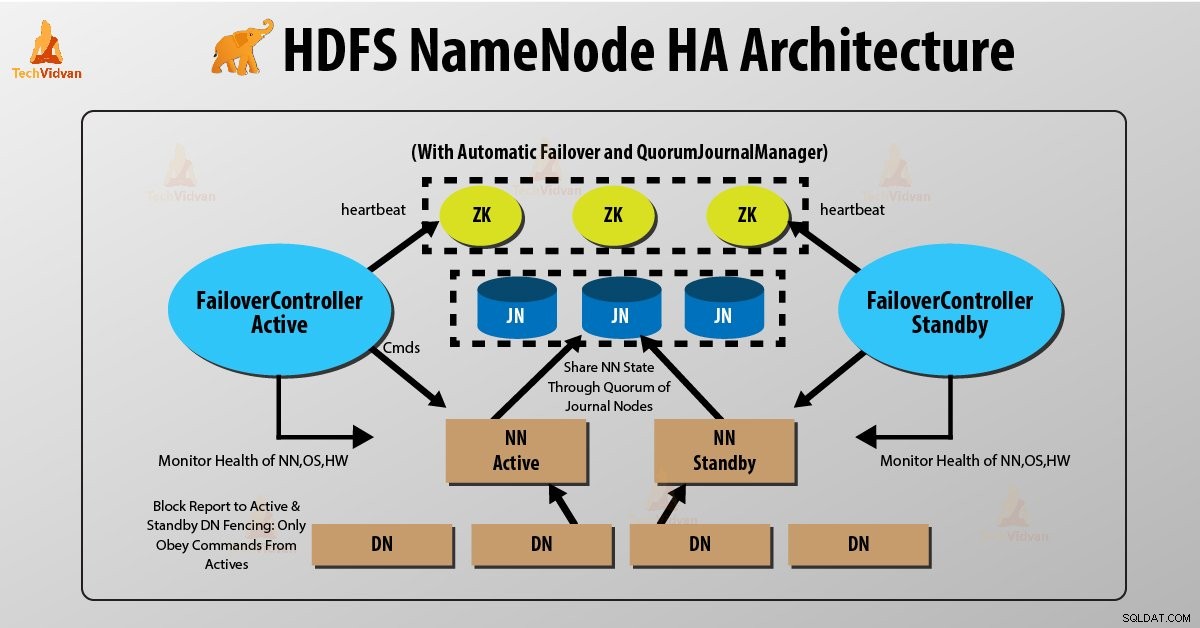
Två NameNodes körs samtidigt i HDFS NameNode High Availability Architecture. HDFS-klienten kan implementera Active och Standby NameNode-konfigurationen på följande två sätt:
- Använda kvorumjournalnoder
- Använda delad lagring
1. Använda kvorumjournalnoder
Quorum Journal Noder är en HDFS-implementering. QJN tillhandahåller redigeringsloggar. Det tillåter att dela dessa redigeringsloggar mellan den aktiva och standby-namnnoden.
Standby Namenode kommunicerar och synkroniserar med den aktiva NameNode för hög tillgänglighet. Det kommer att ske av en grupp demoner som kallas "Journal nodes". Kvorumjournalnoderna körs som en grupp av journalnoder. Minst tre journalnoder bör finnas där.
För N journalnoder kan systemet som mest tolerera (N-1)/2 fel. Systemet fortsätter alltså att fungera. Så för tre journalnoder kan systemet tolerera fel på en {(3-1)/2} av dem.
Närhelst en aktiv nod utför någon modifiering, loggar den modifiering till alla journalnoder.
Standbynoden läser redigeringarna från journalnoderna och tillämpar sitt eget namnområde på ett konstant sätt. I fallet med failover kommer vänteläget att se till att det har läst alla redigeringar från journalnoderna innan det går upp till det aktiva tillståndet. Detta säkerställer att namnområdets tillstånd är helt synkroniserat innan ett fel inträffar.
För att tillhandahålla en snabb failover måste standbynoden ha uppdaterad information om var datablocken finns i klustret. För att detta ska hända är IP-adressen för både NameNode tillgänglig för alla datanoder och de skickar blockplatsinformation och hjärtslag till båda NameNode.
Fäktning av NameNode
För att ett HA-kluster ska fungera korrekt bör endast en av NameNodes vara aktiv åt gången. Annars skulle namnområdets tillstånd avvika mellan de två namnnoderna. Så, stängsel är en process för att säkerställa den här egenskapen i ett kluster.
- Journalnoderna utför detta stängsel genom att endast tillåta en NameNode att skriva åt gången.
- Vänteläget NameNode tar ansvar för att skriva till journalnoderna och förbjuder någon annan NameNode att förbli aktiv.
- Äntligen kan den nya aktiva NameNode utföra sina aktiviteter.
2. Använda delad lagring
Standby och aktiv NameNode synkroniseras med varandra genom att använda "delad lagringsenhet". För denna implementering måste både aktiv NameNode och standby-Namenode ha åtkomst till den specifika katalogen på den delade lagringsenheten (dvs nätverksfilsystemet).
När aktiv NameNode utför någon namnområdesändring, loggar den en post över ändringen till en redigeringsloggfil som lagras i den delade katalogen. Standby NameNode bevakar den här katalogen för redigeringar, och när ändringar sker, applicerar standby NameNode dem på sitt eget namnområde. I händelse av misslyckande kommer standby-namnnoden att se till att den har läst alla redigeringar från den delade lagringen innan den flyttar upp sig själv till det aktiva tillståndet. Detta säkerställer att namnområdets tillstånd är helt synkroniserat innan failover inträffar.
För att förhindra "split-brain-scenariot" där namnområdets tillstånd avviker mellan de två NameNode, måste en administratör konfigurera minst en stängselmetod för den delade lagringen.
Slutsats
Därför tillhandahåller Hadoop 2.0 HDFS HA en enda aktiv NameNode och singel standby NameNode. Men vissa implementeringar kräver en hög grad av feltolerans . Hadoop nya version 3.0, låter användaren köra många standby-namnnoder.
Till exempel, konfigurera fem journalnoder och tre NameNode. Som ett resultat kan hadoop-klustret tolerera fel på två noder snarare än en.
Vänligen dela dina erfarenheter och förslag i samband med HDFS NameNode High Availability i kommentarsfältet nedan.