I denna Hadoop-handledning , kommer vi att ge dig en detaljerad beskrivning av Hadoop Combiner. Först och främst kommer vi att se vad som är MapReduce Combiner, vad som är nyckelrollen för Combiner i MapReduce.
Sedan kommer vi att diskutera exemplet med MapReduce-programmet med och utan combiner i Hadoop. Äntligen kommer vi också att se några fördelar och nackdelar med Combiner i MapReduce.
Vad är Hadoop Combiner?
Kombinator är också känd som "Mini-Reducer ” som sammanfattar Mapper mata ut posten med samma nyckel innan du går till Reducer .
På en stor datamängd när vi kör MapReduce jobb. Så Mapper genererar stora bitar av mellanliggande data. Sedan skickar ramverket dessa mellanliggande data till Reducer för vidare bearbetning.
Detta leder till enorma nätstockningar. Hadoop-ramverket tillhandahåller en funktion som kallas Combiner som spelar en nyckelroll för att minska överbelastningen på nätet.
Den primära uppgiften för Combiner en "Mini-Reducer är att bearbeta utdata från Mapper, innan den skickas till Reducer. Den körs efter mapparen och före reduceraren. Dess användning är valfri.
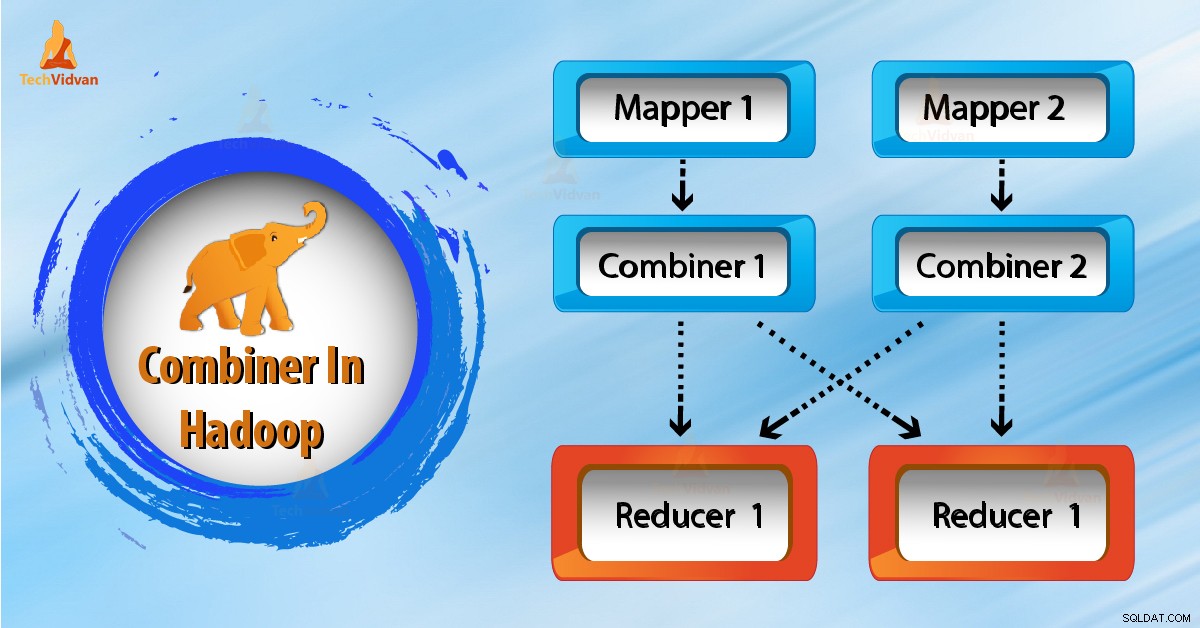
Hur fungerar Combiner i Hadoop?
Låt oss nu lära oss hur saker förändras när vi använder combinern i MapReduce?

Som vi ser i diagrammet ovan finns ingen kombinerare där. Indata är uppdelat i två mappar. Ramverket genererar 9 nycklar från kartläggarna.
Så nu har vi (9 nyckel/värde) mellanliggande data. Ytterligare mappare skickar detta nyckel-värde direkt till reduceringen. När den skickar data till reduceraren förbrukar den viss nätverksbandbredd. Det tar längre tid att överföra data till reducering om datastorleken är stor.

Nu från ovanstående diagram, om vi använder en combiner mellan mapper och reducerare. Sedan blandar combiner 9 nyckel/värde innan den skickas till reduceraren. Och genererar sedan 4 nyckel/värdepar som en utdata.
Nu behöver Reducer endast bearbeta 4 nyckel-/värdepardata som genereras från 2 kombinerare. Därför exekveras reduceraren endast 4 gånger för att producera den slutliga uteffekten. Detta ökar alltså den totala prestandan.
Fördelar med Combiner i MapReduce
Låt oss nu diskutera fördelarna med Hadoop Combiner i MapReduce.
- Användning av combiner minskar tiden det tar för dataöverföring mellan mapper och reducer.
- Combiner förbättrar reducerarens övergripande prestanda.
- Det minskar mängden data som reduceraren måste bearbeta.
Nackdelar med Combiner i MapReduce
Det finns också några nackdelar med Hadoop Combiner. Låt oss nu diskutera detsamma.
- I det lokala filsystemet, när Hadoop lagrar nyckel-värdeparen och kör kombineraren senare kommer detta att orsaka dyr disk-IO.
- MapReduce-jobb kan inte bero på kombinationsutförandet eftersom det inte finns någon garanti för dess utförande.
Slutsats
Därför spelar Hadoop Combiner en nyckelroll för att minska överbelastningen i nätverket. Det förbättrar reducerarens övergripande prestanda genom att sammanfatta resultatet från Mapper.
Jag hoppas att du nu har en klar förståelse för Hadoop Combiner. Om du fortfarande har några frågor, så låt oss veta att lämna en kommentar i ett avsnitt nedan.