I den här bloggen kommer vi att ge dig en fullständig introduktion av Hadoop Mapper . I
I den här bloggen kommer vi att svara på vad som är Mapper i Hadoop MapReduce, hur Hadoop Mapper fungerar, vad är processen för Mapper i Mapreduce, hur Hadoop genererar nyckel-värdepar i MapReduce.
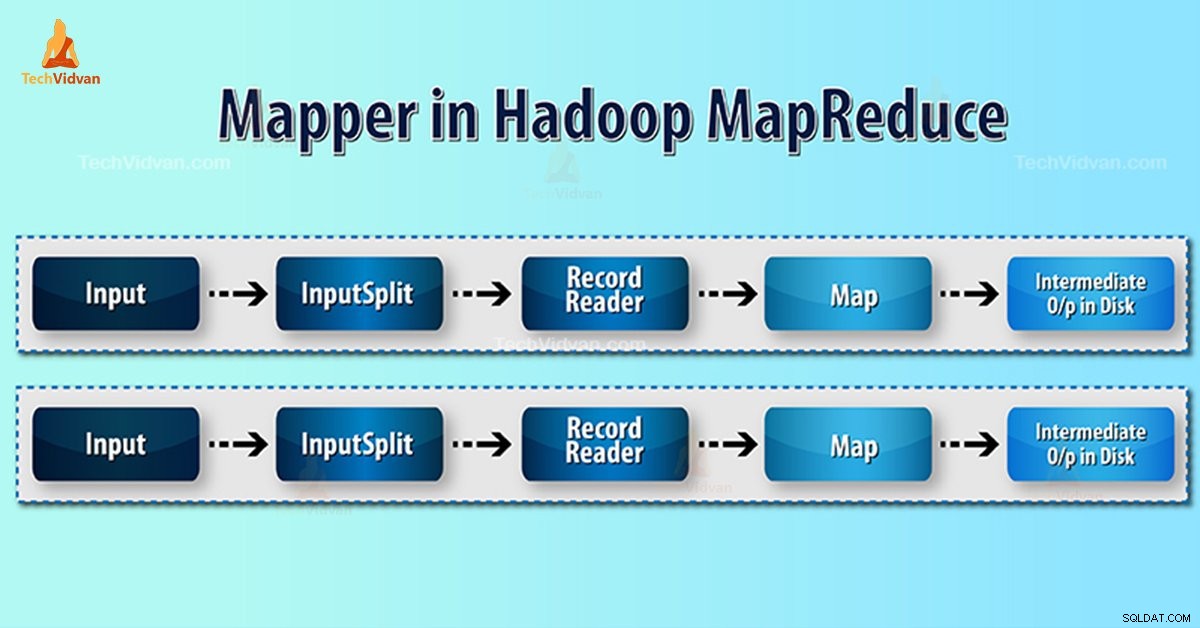
Introduktion till Hadoop Mapper
Hadoop Mapper bearbetar indatapost som produceras av RecordReader och genererar mellanliggande nyckel-värdepar. Mellanutgången är helt annorlunda än ingångsparet.
Utdata från mapparen är den fullständiga samlingen av nyckel-värdepar. Innan du skriver utdata för varje mapparuppgift sker partitionering av utdata på basis av nyckeln. Partitionering specificerar alltså att alla värden för varje nyckel är grupperade tillsammans.
Hadoop MapReduce genererar en kartuppgift för varje InputSplit.
Hadoop MapReduce förstår endast nyckel-värdepar av data. Så, innan du skickar data till kartläggaren, bör Hadoop-ramverket hölja data i nyckel-värdeparet.
Hur genereras nyckel-värdepar i Hadoop?
När vi har förstått vad som är mapper i hadoop, kommer vi nu att diskutera hur Hadoop genererar nyckel-värdepar?
- InputSplit – Det är den logiska representationen av data som genereras av InputFormat. I MapReduce-programmet beskriver det en arbetsenhet som innehåller en enda kartuppgift.
- RecordReader- Den kommunicerar med inputSplit. Och konverterar sedan data till nyckel-värdepar som är lämpliga för läsning av Mapper. RecordReader använder som standard TextInputFormat för att konvertera data till nyckel-värdeparet.
Mapper Process i Hadoop MapReduce
InputSplit konverterar den fysiska representationen av blocken till logisk för Mapper. Till exempel, för att läsa filen på 100 MB, krävs 2 InputSplit. För varje block skapar ramverket en InputSplit. Varje InputSplit skapar en mappare.
MapReduce InputSplit beror inte alltid på antalet datablock . Vi kan ändra numret på en uppdelning genom att ställa in egenskapen mapred.max.split.size under arbetets utförande.
MapReduce RecordReader ansvarar för att läsa/konvertera data till nyckel-värdepar till slutet av filen. RecordReader tilldelar Byte offset till varje rad som finns i filen.
Sedan får Mapper det här nyckelparet. Mapper producerar mellanutgången (nyckel-värdepar som är förståeliga att reducera).
Hur många kartuppgifter i Hadoop?
Antalet kartuppgifter beror på det totala antalet block i inmatningsfilerna. I MapReduce map verkar den rätta nivån av parallellitet vara runt 10-100 kartor/nod. Men det finns 300 kartor för CPU-light kartuppgifter.
Till exempel har vi en blockstorlek på 128 MB. Och vi förväntar oss 10 TB indata. Den producerar alltså 82 000 kartor. Antalet kartor beror därför på InputFormat.
Mapper =(total datastorlek)/ (delad indatastorlek)
Exempel – datastorleken är 1 TB. Storleken på delad ingång är 100 MB.
Mapper =(1000*1000)/100 =10 000
Slutsats
Därför tar Mapper i Hadoop en uppsättning data och konverterar den till en annan uppsättning data. Således delar den upp individuella element i tupler (nyckel/värdepar).
Hoppas du gillar det här blocket, om du har några frågor om Hadoop mapper, så vänligen lämna en kommentar i ett avsnitt nedan. Vi löser dem gärna.