I vår tidigare Hadoop-handledning , vi har studerat Hadoop Partitioner i detalj. Nu ska vi diskutera InputSplit i Hadoop MapReduce.
Här kommer vi att täcka vad som är Hadoop InputSplit, behovet av InputSplit i MapReduce. Vi kommer också att diskutera hur dessa InputSplits skapas i Hadoop MapReduce i detalj.
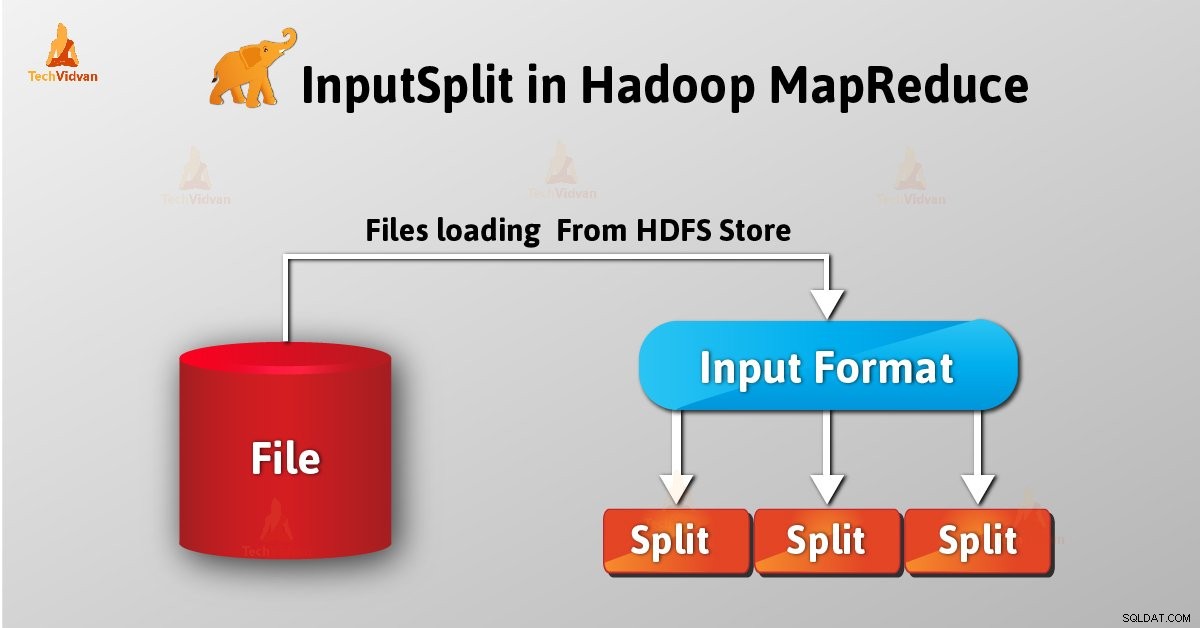
Introduktion till InputSplit i Hadoop
InputSplit är den logiska representationen av data i Hadoop MapReduce. Det representerar data som enskild kartläggare processer. Således är antalet kartuppgifter lika med antalet InputSplits. Framework delar upp i poster, som mappar processer.
MapReduce InputSplit-längden har uppmätts i byte. Varje InputSplit har lagringsplatser (värdnamnsträngar). MapReduce-systemet placerar kartuppgifter så nära delningens data som möjligt genom att använda lagringsplatser.
Ramprocesser Kartlägg uppgifter i storleksordningen på delarna så att den största bearbetas först (girig approximationsalgoritm). Detta minimerar arbetstiden.
Det viktigaste att fokusera på är att Inputsplit inte innehåller indata; det är bara en referens till data.
Hur skapas InputSplits i Hadoop MapReduce?
Som användare hanterar vi inte InputSplit i Hadoop direkt, eftersom InputFormat (eftersom InputFormat ansvarar för att skapa Inputsplit och dela upp i posterna) skapar den. FileInputFormat delar upp en fil i 128MB-bitar.
Dessutom genom att ställa in mapped .min .dela .storlek parameter i mapred-site .xml användaren kan ändra värdet enligt krav. Även genom detta kan vi åsidosätta parametern i jobbobjektet som används för att skicka ett visst MapReduce-jobb.
Genom att skriva ett anpassat InputFormat kan vi också kontrollera hur filen delas upp i delar.
InputSplit är användardefinierad. Användaren kan också styra delad storlek baserat på storleken på data i programmet MapReduce. Därför är antalet kartuppgifter i ett MapReduce-jobb lika med antalet InputSplits.
Genom att anropa ‘getSplit()’ , beräknar kunden fördelningarna för jobbet. Sedan skickades den till applikationsmastern, som använder sina lagringsplatser för att schemalägga kartuppgifter som kommer att bearbeta dem i klustret.
Efter den kartuppgiften skickar delingen till createRecordReader() metod. Från det får den RecordReader för splittringen. Sedan genererar RecordReader post (nyckel-värdepar) , som den skickar till kartfunktionen.
Slutsats
Sammanfattningsvis kan vi säga att InputSplit representerar den data som enskild kartläggare bearbetar. För varje delning skapas en kartuppgift. Därför skapar InputFormat InputSplit.
Om du har några frågor om InputSplit i MapReduce, vänligen lämna en kommentar i ett avsnitt nedan.