Apache Hadoop är ett mjukvaruramverk som bearbetar och lagrar stordata över hela klustret av råvaruhårdvara. Hadoop bygger på MapReduce-modellen för att bearbeta enorma mängder data på ett distribuerat sätt.
Denna MapReduce-handledning tog till sig flera funktioner i MapReduce. Efter att ha läst detta kommer du tydligt att förstå varför MapReduce passar bäst för att bearbeta stora mängder data.
Först kommer vi att se en liten introduktion till MapReduce-ramverket. Sedan kommer vi att utforska olika funktioner i MapReduce.
Låt oss börja med introduktionen till MapReduce-ramverket.
Introduktion till MapReduce
MapReduce är ett ramverk för programvara för att skriva applikationer som kan bearbeta enorma mängder data över klustren av billiga noder. Hadoop MapReduce är bearbetningsdelen av Apache Hadoop.
Det är också känt som hjärtat av Hadoop. Det är den mest föredragna databehandlingsapplikationen. Flera aktörer inom e-handelssektorn som Amazon, Yahoo och Zuventus, etc. använder MapReduce-ramverket för databehandling med stora volymer.
Låt oss nu studera de olika funktionerna i Hadoop MapReduce.
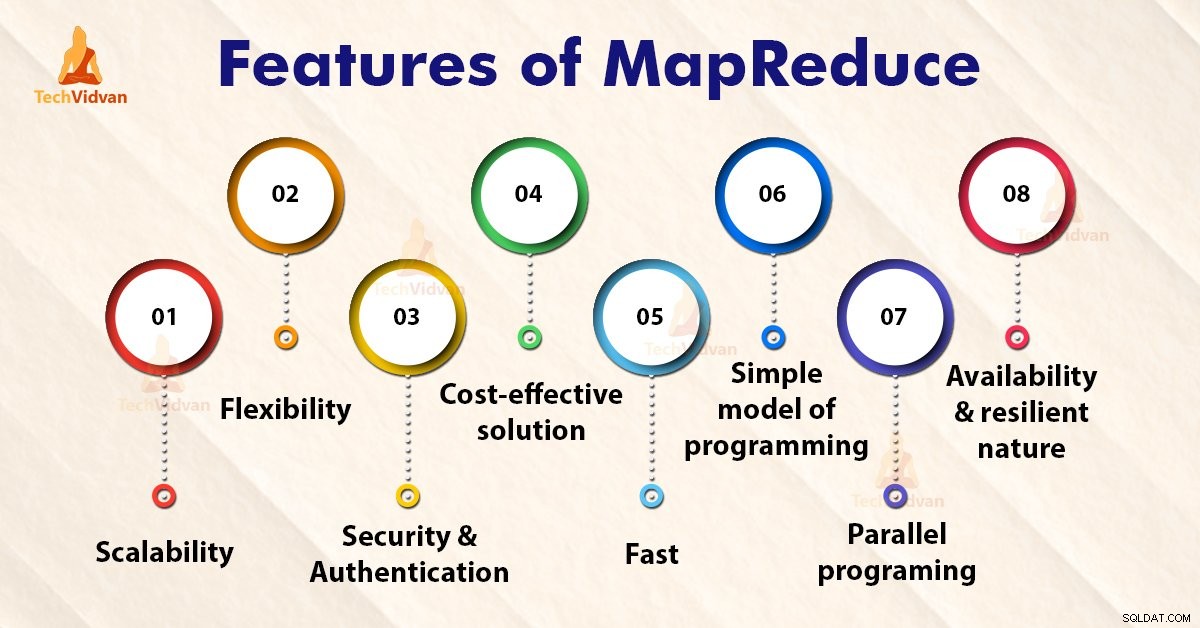
Funktioner i MapReduce
1. Skalbarhet
Apache Hadoop är ett mycket skalbart ramverk. Detta beror på dess förmåga att lagra och distribuera enorma data över massor av servrar. Alla dessa servrar var billiga och kan fungera parallellt. Vi kan enkelt skala lagrings- och beräkningskraften genom att lägga till servrar i klustret.
Hadoop MapReduce-programmering gör det möjligt för organisationer att köra applikationer från stora uppsättningar noder som kan involvera användningen av tusentals terabyte data.
Hadoop MapReduce-programmering gör det möjligt för företagsorganisationer att köra applikationer från stora uppsättningar noder. Detta kan använda tusentals terabyte data.
2. Flexibilitet
MapReduce-programmering gör det möjligt för företag att få tillgång till nya datakällor. Det gör det möjligt för företag att arbeta med olika typer av data. Det tillåter företag att få tillgång till såväl strukturerad som ostrukturerad data och få betydande värde genom att få insikter från de många datakällorna.
Dessutom ger MapReduce-ramverket också stöd för flera språk och data från källor från e-post, sociala medier till klickström.
MapReduce bearbetar data i enkla nyckel-värdepar stöder alltså datatyper inklusive metadata, bilder och stora filer. MapReduce är därför flexibel för att hantera data snarare än traditionell DBMS.
3. Säkerhet och autentisering
MapReduce-programmeringsmodellen använder HBase och HDFS säkerhetsplattform som endast tillåter åtkomst till autentiserade användare för att använda data. Således skyddar det obehörig åtkomst till systemdata och förbättrar systemsäkerheten.
4. Kostnadseffektiv lösning
Hadoops skalbara arkitektur med MapReduce-programmeringsramverket tillåter lagring och bearbetning av stora datamängder på ett mycket prisvärt sätt.
5. Snabbt
Hadoop använder en distribuerad lagringsmetod som kallas ett Hadoop Distributed File System som i princip implementerar ett mappningssystem för att lokalisera data i ett kluster.
Verktygen som används för databearbetning, såsom MapReduce-programmering, finns i allmänhet på samma servrar som möjliggör snabbare bearbetning av data.
Så även om vi har att göra med stora volymer ostrukturerad data tar Hadoop MapReduce bara några minuter att bearbeta terabyte med data. Den kan bearbeta petabyte med data på bara en timme.
6. Enkel modell för programmering
Bland de olika funktionerna i Hadoop MapReduce är en av de viktigaste funktionerna att den är baserad på en enkel programmeringsmodell. I grund och botten tillåter detta programmerare att utveckla MapReduce-programmen som kan hantera uppgifter enkelt och effektivt.
MapReduce-programmen kan skrivas i Java, vilket inte är särskilt svårt att plocka upp och som också används flitigt. Så vem som helst kan enkelt lära sig och skriva MapReduce-program och möta deras databehandlingsbehov.
7. Parallell programmering
En av de viktigaste aspekterna av arbetet med MapReduce-programmering är dess parallella bearbetning. Den delar upp uppgifterna på ett sätt som gör att de kan utföras parallellt.
Den parallella bearbetningen tillåter flera processorer att utföra dessa uppdelade uppgifter. Så hela programmet körs på kortare tid.
8. Tillgänglighet och motståndskraftig natur
Närhelst data skickas till en enskild nod, vidarebefordras samma uppsättning data till några andra noder i ett kluster. Så om någon viss nod lider av ett fel, så finns det alltid andra kopior på andra noder som fortfarande kan nås när det behövs. Detta säkerställer hög tillgänglighet för data.
En av de viktigaste funktionerna som erbjuds av Apache Hadoop är dess feltolerans. Hadoop MapReduce-ramverket har förmågan att snabbt känna igen fel som uppstår.
Den tillämpar sedan en snabb och automatisk återställningslösning. Den här funktionen gör den till en spelväxlare i en värld av big data-bearbetning.
Sammanfattning
Jag hoppas att du efter att ha läst den här artikeln tydligt förstått de olika funktionerna i Hadoop MapReduce. Artikeln tog upp olika funktioner i MapReduce. MapReduce-ramverket är skalbart, flexibelt, kostnadseffektivt och snabbt bearbetningssystem.
Den erbjuder säkerhet, feltolerans och autentisering. MapReduce är en enkel modell för programmering och erbjuder parallell programmering.