Hittills har vi täckt Hadoop-introduktionen och Hadoop HDFS i detalj. I den här handledningen kommer vi att ge dig en detaljerad beskrivning av Hadoop Reducer.
Här diskuteras vad som är Reducer i MapReduce, hur Reducer fungerar i Hadoop MapReduce, olika faser av Hadoop Reducer, hur kan vi ändra antalet Reducer i Hadoop MapReduce.
Vad är Hadoop Reducer?
Reducerare i Hadoop minskar MapReduce en uppsättning mellanvärden som delar en nyckel till en mindre uppsättning värden.
I MapReduce jobbexekveringsflöde tar Reducer en uppsättning av ett mellanliggande nyckel-värdepar producerad av kartläggningen som ingång. Sedan kan Reducer aggregera, filtrera och kombinera nyckel-värdepar och detta kräver ett brett spektrum av bearbetning.
En-en-mappning sker mellan nycklar och reducerare i MapReduce-jobbexekveringen. De löper parallellt eftersom de är oberoende av varandra. Användaren bestämmer antalet reducerare i MapReduce.
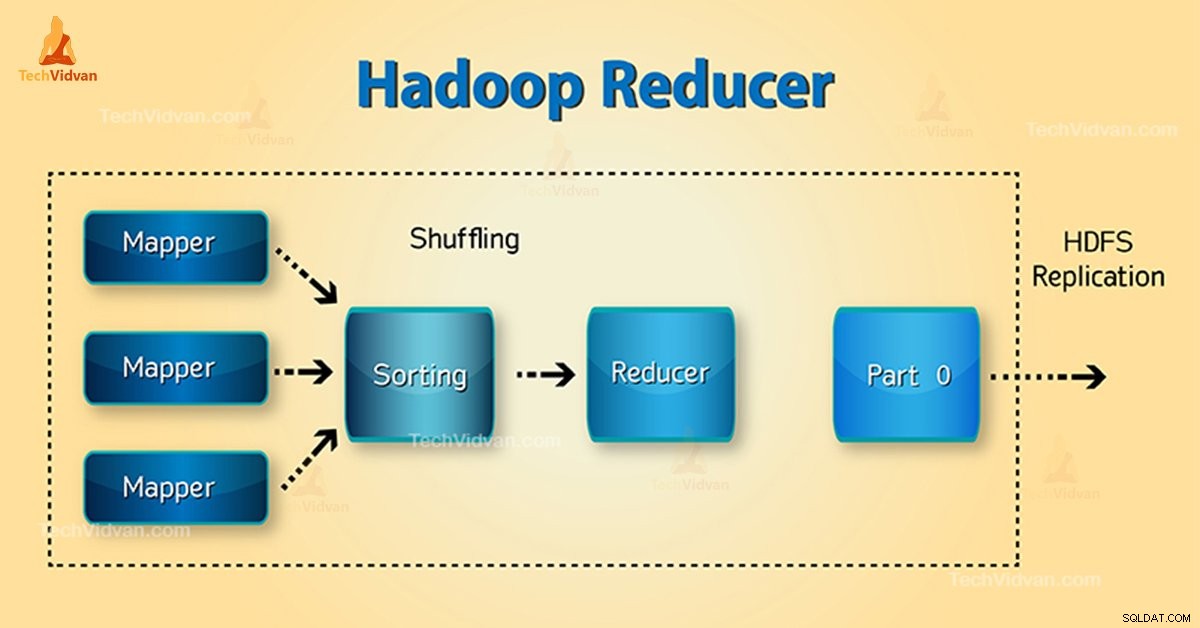
Faser av Hadoop Reducer
Tre faser av Reducer är som följer:
1. Blanda fas
Detta är den fas i vilken sorterad utdata från mapparen är ingången till reduceraren. Ramverket med hjälp av HTTP hämtar den relevanta partitionen av utdata från alla mappare i denna fas.Sorteringsfas
2. Sorteringsfas
Detta är den fas i vilken indata från olika kartläggare igen sorteras baserat på liknande nycklar i olika kartläggare.
Både Blanda och Sortera sker samtidigt.
3. Minska fas
Denna fas inträffar efter blandning och sortering. Minska uppgiften samlar nyckel-värdeparen. Med OutputCollector.collect() egenskapen, skrivs utdata från reduceringsuppgiften till filsystemet. Reducer output sorteras inte.
Antal reducerare i Hadoop MapReduce
Användaren ställer in antalet reducerare med hjälp av Job.setNumreduceTasks(int) fast egendom. Alltså rätt antal reducerare med formeln:
0,95 eller 1,75 multiplicerat med (
Så med 0,95 startar alla reducerar omedelbart. Börja sedan överföra kartutdata när kartorna är klara.
Snabbare nod avslutar den första omgången av reducerare med 1,75. Sedan lanserar den den andra vågen av reducerare som gör mycket bättre jobb med lastbalansering.
Med ökningen av antalet reducerar:
- Framework overhead ökar.
- Lastbalanseringen ökar.
- Kostnaden för misslyckanden minskar.
Slutsats
Därför tar Reducer mappers utdata som indata. Bearbeta sedan nyckel-värde-paren och producerar utdata. Reducer output är den slutliga utgången. Om du gillar den här bloggen eller om du har någon fråga relaterade till Hadoop Reducer, så dela gärna med oss genom att lämna en kommentar.
Hoppas vi hjälper dig.