Effektiviteten i en databas bygger inte bara på att finjustera de mest kritiska parametrarna, utan går också vidare till lämplig datapresentation i de relaterade samlingarna. Nyligen arbetade jag med ett projekt som utvecklade en social chattapplikation, och efter några dagars testning märkte vi en viss fördröjning när vi hämtade data från databasen. Vi hade inte så många användare, så vi uteslöt att databasparametrarna skulle ställas in och fokuserade på våra frågor för att komma till grundorsaken.
Till vår förvåning insåg vi att vår datastrukturering inte var helt lämplig eftersom vi hade mer än 1 läsbegäran för att hämta viss information.
Den konceptuella modellen för hur applikationssektioner sätts på plats beror mycket på databassamlingens struktur. Om du till exempel loggar in på en social app, matas data in i de olika sektionerna enligt applikationsdesignen som avbildas från databaspresentationen.
I ett nötskal, för en väldesignad databas, är schemastruktur och samlingsrelationer nyckelfaktorer för dess förbättrade hastighet och integritet, vilket vi kommer att se i följande avsnitt.
Vi kommer att diskutera de faktorer du bör tänka på när du modellerar dina data.
Vad är datamodellering
Datamodellering är i allmänhet analys av dataobjekt i en databas och hur relaterade de är till andra objekt i den databasen.
I MongoDB till exempel kan vi ha en användarsamling och en profilsamling. Användarsamlingen listar namn på användare för en viss applikation medan profilsamlingen fångar profilinställningarna för varje användare.
I datamodellering måste vi utforma en relation för att koppla varje användare till korrespondentprofilen. I ett nötskal är datamodellering det grundläggande steget i databasdesign förutom att utgöra arkitekturbasen för objektorienterad programmering. Det ger också en ledtråd om hur den fysiska applikationen kommer att se ut under utvecklingen. En applikation-databas integrationsarkitektur kan illustreras enligt nedan.
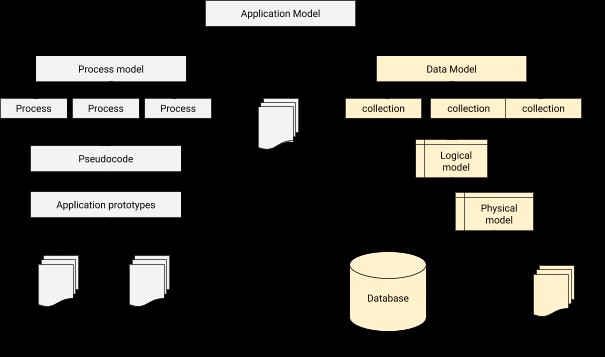
Processen för datamodellering i MongoDB
Datamodellering kommer med förbättrad databasprestanda, men på bekostnad av vissa överväganden som inkluderar:
- Datahämtningsmönster
- Balansera applikationens behov såsom:frågor, uppdateringar och databehandling
- Prestandafunktioner för den valda databasmotorn
- Den inneboende strukturen för själva data
MongoDB-dokumentstruktur
Dokument i MongoDB spelar en stor roll i beslutsfattandet om vilken teknik som ska tillämpas för en given uppsättning data. Det finns i allmänhet två samband mellan data, som är:
- Inbäddad data
- Referensdata
Inbäddad data
I det här fallet lagras relaterade data i ett enda dokument, antingen som ett fältvärde eller en array i själva dokumentet. Den största fördelen med detta tillvägagångssätt är att data denormaliseras och därför ger en möjlighet att manipulera relaterade data i en enda databasoperation. Följaktligen förbättrar detta hastigheten med vilken CRUD-operationer utförs, varför färre frågor krävs. Låt oss överväga ett exempel på ett dokument nedan:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"Settings" : {
"location" : "Embassy",
"ParentPhone" : 724765986
"bus" : "KAZ 450G",
"distance" : "4",
"placeLocation" : {
"lat" : -0.376252,
"lng" : 36.937389
}
}
}I denna uppsättning data har vi en elev med hans namn och annan ytterligare information. Fältet Inställningar har bäddats in med ett objekt och vidare är fältet placeLocation också inbäddat med ett objekt med latitud- och longitudkonfigurationer. All data för denna elev har funnits i ett enda dokument. Om vi behöver hämta all information för denna elev kör vi bara:
db.students.findOne({StudentName : "George Beckonn"})Inbäddningens styrkor
- Ökad dataåtkomsthastighet:För en förbättrad åtkomsthastighet till data är inbäddning det bästa alternativet eftersom en enda frågeoperation kan manipulera data i det angivna dokumentet med bara en enda databassökning.
- Minskad datainkonsekvens:Under drift, om något går fel (till exempel en nätverksavbrott eller strömavbrott) kan endast ett fåtal dokument påverkas eftersom kriterierna ofta väljer ett enda dokument.
- Minskad CRUD-verksamhet. Det vill säga att läsoperationerna faktiskt kommer att överstiga skrivningarna. Dessutom är det möjligt att uppdatera relaterade data i en enda atomär skrivoperation. Dvs för ovanstående data kan vi uppdatera telefonnumret och även öka avståndet med denna enda operation:
db.students.updateOne({StudentName : "George Beckonn"}, { $set: {"ParentPhone" : 72436986}, $inc: {"Settings.distance": 1} })
Svagheter med inbäddning
- Begränsad dokumentstorlek. Alla dokument i MongoDB är begränsade till BSON-storleken på 16 megabyte. Därför bör den totala dokumentstorleken tillsammans med inbäddade data inte överskrida denna gräns. Annars, för vissa lagringsmotorer som MMAPv1, kan data växa ur och resultera i datafragmentering som ett resultat av försämrad skrivprestanda.
- Dataduplicering:flera kopior av samma data gör det svårare att söka efter replikerad data och det kan ta längre tid att filtrera inbäddade dokument, vilket överträffar kärnfördelen med inbäddning.
Pricknotation
Punktnotationen är identifieringsfunktionen för inbäddade data i programmeringsdelen. Den används för att komma åt element i ett inbäddat fält eller en array. I exempeldata ovan kan vi returnera information om studenten vars plats är "ambassaden" med denna fråga med hjälp av punktnotationen.
db.users.find({'Settings.location': 'Embassy'})Referensdata
Datarelationen i detta fall är att relaterade data lagras i olika dokument, men någon referenslänk ges till dessa relaterade dokument. För exempeldata ovan kan vi rekonstruera dem på ett sådant sätt att:
Användardokument
{ "_id" : xyz,
"StudentName" : "George Beckonn",
"ParentPhone" : 075646344,
}Inställningsdokument
{
"id" :xyz,
"location" : "Embassy",
"bus" : "KAZ 450G",
"distance" : "4",
"lat" : -0.376252,
"lng" : 36.937389
}Det finns 2 olika dokument, men de är länkade med samma värde för fälten _id och id. Datamodellen är därmed normaliserad. Men för att vi ska få tillgång till information från ett relaterat dokument måste vi ställa ytterligare frågor och följaktligen resulterar detta i ökad exekveringstid. Om vi till exempel vill uppdatera ParentPhone och de relaterade avståndsinställningarna kommer vi att ha minst 3 frågor, dvs.
//fetch the id of a matching student
var studentId = db.students.findOne({"StudentName" : "George Beckonn"})._id
//use the id of a matching student to update the ParentPhone in the Users document
db.students.updateOne({_id : studentId}, {
$set: {"ParentPhone" : 72436986},
})
//use the id of a matching student to update the distance in settings document
db.students.updateOne({id : studentId}, {
$inc: {"distance": 1}
})Referensstyrkor
- Datakonsistens. För varje dokument upprätthålls ett kanoniskt formulär, varför risken för datainkonsekvens är ganska låg.
- Förbättrad dataintegritet. På grund av normalisering är det enkelt att uppdatera data oavsett driftlängd och därför säkerställa korrekta data för varje dokument utan att orsaka förvirring.
- Förbättrad cacheanvändning. Kanoniska dokument som används ofta lagras i cachen snarare än för inbäddade dokument som nås några gånger.
- Effektivt hårdvaruanvändning. I motsats till inbäddning, vilket kan leda till att dokument växer ut, främjar inte hänvisningar dokumenttillväxt, vilket minskar disk- och RAM-användningen.
- Förbättrad flexibilitet, särskilt med en stor uppsättning underdokument.
- Snabbare skriver.
Svagheter med referenser
- Flera uppslagningar:Eftersom vi måste titta i ett antal dokument som matchar kriterierna ökar lästiden vid hämtning från disk. Dessutom kan detta leda till cachemissar.
- Många förfrågningar utfärdas för att uppnå viss operation, därför kräver normaliserade datamodeller fler rundresor till servern för att slutföra en specifik operation.
Datanormalisering
Datanormalisering avser att omstrukturera en databas i enlighet med vissa normala former för att förbättra dataintegriteten och minska händelser av dataredundans.
Datamodellering kretsar kring 2 stora normaliseringstekniker som är:
-
Normaliserade datamodeller
Som tillämpas i referensdata delar normalisering upp data i flera samlingar med referenser mellan de nya samlingarna. En enda dokumentuppdatering kommer att utfärdas till den andra samlingen och tillämpas i enlighet med det matchande dokumentet. Detta ger en effektiv datauppdateringsrepresentation och används ofta för data som ändras ganska ofta.
-
Denormaliserade datamodeller
Data innehåller inbäddade dokument vilket gör läsoperationerna ganska effektiva. Det är dock förknippat med mer diskutrymmesanvändning och även svårigheter att hålla synkroniseringen. Denormaliseringskonceptet kan väl appliceras på underdokument vars data inte ändras ganska ofta.
MongoDB Schema
Ett schema är i grunden ett skisserat skelett av fält och datatyp varje fält bör hålla för en given uppsättning data. Med tanke på SQL-synpunkten är alla rader utformade för att ha samma kolumner och varje kolumn bör innehålla den definierade datatypen. Men i MongoDB har vi som standard ett flexibelt schema som inte håller samma överensstämmelse för alla dokument.
Flexibelt schema
Ett flexibelt schema i MongoDB definierar att dokumenten inte nödvändigtvis behöver ha samma fält eller datatyp, för ett fält kan skilja sig åt mellan dokument inom en samling. Kärnfördelen med detta koncept är att man kan lägga till nya fält, ta bort befintliga eller ändra fältvärdena till en ny typ och därmed uppdatera dokumentet till en ny struktur.
Till exempel kan vi ha dessa två dokument i samma samling:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"ParentPhone" : 75646344,
"age" : 10
}
{ "_id" : ObjectId("5b98bfe7e8b9ab98757e8b9a"),
"StudentName" : "Fredrick Wesonga",
"ParentPhone" : false,
}I det första dokumentet har vi ett åldersfält medan det i det andra dokumentet inte finns något åldersfält. Vidare är datatypen för ParentPhone-fältet ett nummer medan det i det andra dokumentet har ställts in på false vilket är en boolesk typ.
Schemaflexibilitet underlättar mappning av dokument till ett objekt och varje dokument kan matcha datafält för den representerade enheten.
Styvt schema
Så mycket som vi har sagt att dessa dokument kan skilja sig från varandra, ibland kan du välja att skapa ett stelbent schema. Ett stel schema kommer att definiera att alla dokument i en samling kommer att dela samma struktur och detta ger dig en bättre chans att ställa in vissa dokumentvalideringsregler som ett sätt att förbättra dataintegriteten under infogning och uppdatering.
Schemadatatyper
När du använder vissa serverdrivrutiner för MongoDB såsom mongoose, finns det några datatyper som gör det möjligt för dig att göra datavalidering. De grundläggande datatyperna är:
- Sträng
- Nummer
- Boolesk
- Datum
- Buffert
- ObjectId
- Array
- Blandat
- Decimal128
- Karta
Ta en titt på exempelschemat nedan
var userSchema = new mongoose.Schema({
userId: Number,
Email: String,
Birthday: Date,
Adult: Boolean,
Binary: Buffer,
height: Schema.Types.Decimal128,
units: []
});Exempel på användningsfall
var user = mongoose.model(‘Users’, userSchema )
var newUser = new user;
newUser.userId = 1;
newUser.Email = “example@sqldat.com”;
newUser.Birthday = new Date;
newUser.Adult = false;
newUser.Binary = Buffer.alloc(0);
newUser.height = 12.45;
newUser.units = [‘Circuit network Theory’, ‘Algerbra’, ‘Calculus’];
newUser.save(callbackfunction);Schemavalidering
Så mycket som du kan göra datavalidering från applikationssidan, är det alltid bra att göra valideringen från serversidan också. Vi uppnår detta genom att använda reglerna för schemavalidering.
Dessa regler tillämpas under insättning och uppdatering. De deklareras normalt på insamlingsbasis under skapandet. Du kan dock också lägga till dokumentvalideringsreglerna till en befintlig samling med kommandot collMod med valideringsalternativ, men dessa regler tillämpas inte på de befintliga dokumenten förrän en uppdatering tillämpas på dem.
På samma sätt, när du skapar en ny samling med kommandot db.createCollection() kan du utfärda valideringsalternativet. Ta en titt på det här exemplet när du skapar en samling för elever. Från version 3.6 stöder MongoDB JSON Schema-validering, så allt du behöver är att använda $jsonSchema-operatorn.
db.createCollection("students", {
validator: {$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "gpa" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
gender: {
bsonType: "string",
description: "must be a string and is not required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
exclusiveMaximum: false,
description: "must be an integer in [ 2017, 2020 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
minimum: 0,
description: "must be a double and is required"
}
}
}})I denna schemadesign, om vi försöker infoga ett nytt dokument som:
db.students.insert({
name: "James Karanja",
year: NumberInt(2016),
major: "History",
gpa: NumberInt(3)
})Återuppringningsfunktionen kommer att returnera felet nedan, på grund av vissa överträdda valideringsregler som att det angivna årsvärdet inte ligger inom de angivna gränserna.
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 121,
"errmsg" : "Document failed validation"
}
})Vidare kan du lägga till frågeuttryck till ditt valideringsalternativ med hjälp av frågeoperatorer utom $where, $text, near och $nearSphere, dvs.:
db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )Schemavalideringsnivåer
Som nämnts tidigare, utfärdas validering till skrivoperationerna, normalt.
Validering kan dock även tillämpas på redan befintliga dokument.
Det finns tre nivåer av validering:
- Strikt:detta är standardmongoDB-valideringsnivån och den tillämpar valideringsregler på alla inlägg och uppdateringar.
- Moderat:Valideringsreglerna tillämpas endast vid infogningar, uppdateringar och på redan befintliga dokument som uppfyller valideringskriterierna.
- Av:denna nivå ställer in valideringsreglerna för ett givet schema till null, så ingen validering kommer att göras för dokumenten.
Exempel:
Låt oss infoga data nedan i en klientsamling.
db.clients.insert([
{
"_id" : 1,
"name" : "Brillian",
"phone" : "+1 778 574 666",
"city" : "Beijing",
"status" : "Married"
},
{
"_id" : 2,
"name" : "James",
"city" : "Peninsula"
}
]Om vi tillämpar den moderata valideringsnivån med:
db.runCommand( {
collMod: "test",
validator: { $jsonSchema: {
bsonType: "object",
required: [ "phone", "name" ],
properties: {
phone: {
bsonType: "string",
description: "must be a string and is required"
},
name: {
bsonType: "string",
description: "must be a string and is required"
}
}
} },
validationLevel: "moderate"
} )Valideringsreglerna kommer endast att tillämpas på dokumentet med _id på 1 eftersom det kommer att matcha alla kriterier.
För det andra dokumentet, eftersom valideringsreglerna inte uppfylls med de utfärdade kriterierna, kommer dokumentet inte att valideras.
Schemavalideringsåtgärder
Efter att ha gjort validering på dokument kan det finnas några som kan bryta mot valideringsreglerna. Det finns alltid ett behov av att vidta åtgärder när detta händer.
MongoDB tillhandahåller två åtgärder som kan utfärdas för de dokument som inte uppfyller valideringsreglerna:
- Fel:detta är standardåtgärden för MongoDB, som avvisar all infogning eller uppdatering om den bryter mot valideringskriterierna.
-
Varna:Denna åtgärd kommer att registrera överträdelsen i MongoDB-loggen, men tillåter att infognings- eller uppdateringsåtgärden slutförs. Till exempel:
db.createCollection("students", { validator: {$jsonSchema: { bsonType: "object", required: [ "name", "gpa" ], properties: { name: { bsonType: "string", description: "must be a string and is required" }, gpa: { bsonType: [ "double" ], minimum: 0, description: "must be a double and is required" } } }, validationAction: “warn” })Om vi försöker infoga ett dokument så här:
db.students.insert( { name: "Amanda", status: "Updated" } );Gpa saknas oavsett att det är ett obligatoriskt fält i schemadesignen, men eftersom valideringsåtgärden har ställts in på att varna kommer dokumentet att sparas och ett felmeddelande kommer att registreras i MongoDB-loggen.