Välkommen till den tredje – och sista – delen av denna bloggserie, som utforskar hur PostgreSQL-prestandan har utvecklats under åren. Den första delen tittade på OLTP-arbetsbelastningar, representerade av pgbench-tester. Den andra delen tittade på analytiska / BI-frågor, med en delmängd av det traditionella TPC-H-riktmärket (i huvudsak en del av effekttestet).
Och den här sista delen tittar på fulltextsökning, det vill säga möjligheten att indexera och söka i stora mängder textdata. Samma infrastruktur (särskilt indexen) kan vara användbar för att indexera semi-strukturerad data som JSONB-dokument etc. men det är inte vad detta riktmärke fokuserar på.
Men först, låt oss titta på historien om fulltextsökning i PostgreSQL, vilket kan verka som en märklig funktion att lägga till i ett RDBMS, traditionellt avsett för att lagra strukturerad data i rader och kolumner.
Historien för fulltextsökning
När Postgres skapades med öppen källkod 1996 hade den inget vi kunde kalla fulltextsökning. Men människor som började använda Postgres ville göra intelligenta sökningar i textdokument, och LIKE-frågorna var inte tillräckligt bra. De ville kunna lemmatisera termerna med hjälp av ordböcker, ignorera stoppord, sortera matchande dokument efter relevans, använda index för att utföra dessa frågor och många andra saker. Saker du rimligen inte kan göra med traditionella SQL-operatorer.
Lyckligtvis var några av dessa människor också utvecklare så de började arbeta med detta – och de kunde, tack vare att PostgreSQL var tillgängligt som öppen källkod över hela världen. Det har varit många bidragsgivare till fulltextsökning under åren, men till en början leddes denna ansträngning av Oleg Bartunov och Teodor Sigaev, som visas på följande bild. Båda är fortfarande stora PostgreSQL-bidragsgivare och arbetar med fulltextsökning, indexering, JSON-stöd och många andra funktioner.

Teodor Sigaev och Oleg Bartunov
Till en början utvecklades funktionen som en extern "bidragsmodul" (numera skulle vi säga att det är en förlängning) kallad "tsearch", som släpptes 2002. Senare föråldrades detta av tsearch2, vilket avsevärt förbättrade funktionen på många sätt, och i PostgreSQL 8.3 (släpptes 2008) detta var helt integrerat i PostgreSQL-kärnan (dvs. utan att behöva installera något tillägg alls, även om tilläggen fortfarande fanns för bakåtkompatibilitet).
Det har skett många förbättringar sedan dess (och arbetet fortsätter, t.ex. för att stödja datatyper som JSONB, sökning med jsonpath etc.). men dessa plugins introducerade det mesta av fulltextfunktionaliteten vi har i PostgreSQL nu – ordböcker, fulltextindexering och frågefunktioner, etc.
Riktmärket
Till skillnad från OLTP / TPC-H-riktmärkena är jag inte medveten om något fulltextriktmärke som kan betraktas som "industristandard" eller designat för flera databassystem. De flesta av de riktmärken jag känner till är avsedda att användas med en enda databas/produkt, och det är svårt att portera dem på ett meningsfullt sätt, så jag var tvungen att ta en annan väg och skriva mitt eget fulltextriktmärke.
För flera år sedan skrev jag archie – ett par python-skript som tillåter nedladdning av PostgreSQL-postlistarkiv, och laddar de analyserade meddelandena till en PostgreSQL-databas som sedan kan indexeras och sökas i. Den aktuella ögonblicksbilden av alla arkiv har ~1M rader, och efter att ha laddats in i en databas är tabellen cirka 9,5 GB (indexen räknas inte med).
När det gäller frågorna skulle jag förmodligen kunna generera några slumpmässiga, men jag är inte säker på hur realistiskt det skulle vara. Lyckligtvis fick jag för ett par år sedan ett urval av 33 000 faktiska sökningar från PostgreSQL-webbplatsen (dvs saker som folk faktiskt sökte i communityns arkiv). Det är osannolikt att jag skulle kunna få något mer realistiskt/representativt.
Kombinationen av dessa två delar (datauppsättning + frågor) verkar vara ett bra riktmärke. Vi kan helt enkelt ladda data och köra sökningarna med olika typer av fulltextfrågor med olika typer av index.
Frågor
Det finns olika former av fulltextfrågor – frågan kan helt enkelt välja alla matchande rader, den kan rangordna resultaten (sortera dem efter relevans), returnera bara ett litet antal eller de mest relevanta resultaten, etc. Jag körde benchmark med olika typer av frågor, men i det här inlägget kommer jag att presentera resultat för två enkla frågor som jag tycker representerar det övergripande beteendet ganska bra.
- VÄLJ ID, ämne FRÅN meddelanden WHERE body_tsvector @@ $1
- VÄLJ ID, ämne FRÅN meddelanden WHERE body_tsvector @@ $1
ORDER BY ts_rank(body_tsvector, $1) DESC LIMIT 100
Den första frågan returnerar helt enkelt alla matchande rader, medan den andra returnerar de 100 mest relevanta resultaten (detta är något du förmodligen skulle använda för användarsökningar).
Jag har experimenterat med olika andra typer av frågor, men alla betedde sig till slut på ett sätt som liknar en av dessa två frågetyper.
Index
Varje meddelande har två huvuddelar som vi kan söka i – ämne och kropp. Var och en av dem har en separat tsvektorkolumn och indexeras separat. Meddelandeämnena är mycket kortare än kroppar, så indexen är naturligtvis mindre.
PostgreSQL har två typer av index användbara för fulltextsökning – GIN och GiST. De huvudsakliga skillnaderna förklaras i dokumenten, men i korthet:
- GIN-index är snabbare för sökningar
- GiST-index är förlorade, det vill säga kräver omkontroll under sökningar (och är därför långsammare)
Vi brukade hävda att GiST-index är billigare att uppdatera (särskilt med många samtidiga sessioner), men detta togs bort från dokumentationen för en tid sedan på grund av förbättringar i indexeringskoden.
Det här riktmärket testar inte beteende med uppdateringar – det laddar helt enkelt tabellen utan fulltextindex, bygger dem på en gång och exekverar sedan 33k-frågorna på data. Det betyder att jag inte kan göra några uttalanden om hur dessa indextyper hanterar samtidiga uppdateringar baserat på detta riktmärke, men jag tror att dokumentationsändringarna återspeglar olika GIN-förbättringar nyligen.
Detta bör också matcha användningsfallet för e-postlistans arkiv ganska bra, där vi bara lägger till nya e-postmeddelanden då och då (få uppdateringar, nästan ingen skrivsamtidighet). Men om din applikation gör många samtidiga uppdateringar måste du jämföra det på egen hand.
Hårdvaran
Jag gjorde riktmärket på samma två maskiner som tidigare, men resultaten/slutsatserna är nästan identiska, så jag kommer bara att presentera siffrorna från den mindre, dvs.
- CPU i5-2500K (4 kärnor/trådar)
- 8 GB RAM
- 6 x 100 GB SSD RAID0
- kärna 5.6.15, ext4 filsystem
Jag har tidigare nämnt att datamängden har nästan 10 GB när den laddas, så den är större än RAM. Men indexen är fortfarande mindre än RAM, vilket är det som är viktigt för riktmärket.
Resultat
Okej, dags för lite siffror och diagram. Jag kommer att presentera resultat för både dataladdningar och förfrågningar, först med GIN och sedan med GiST-index.
GIN / dataladdning
Lasten är inte speciellt intressant tycker jag. För det första har det mesta (den blå delen) inget med fulltext att göra, eftersom det händer innan de två indexen skapas. Det mesta av denna tid går åt till att analysera meddelanden, bygga om e-posttrådarna, underhålla listan med svar och så vidare. En del av denna kod är implementerad i PL/pgSQL-triggers, en del av den är implementerad utanför databasen. Den ena delen som potentiellt är relevant för fulltext är att bygga tsvektorerna, men det är omöjligt att isolera den tid som spenderas på det.
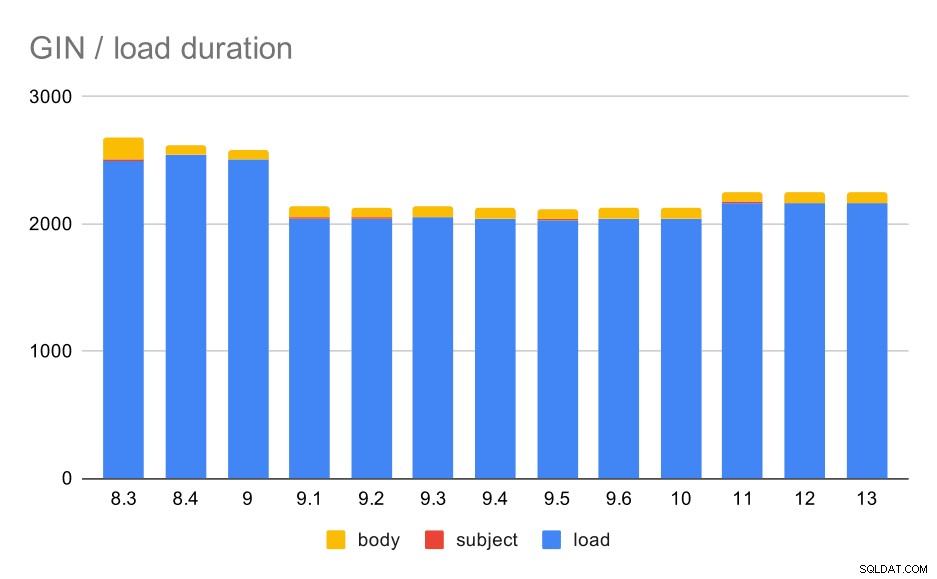
Dataladdningsoperationer med en tabell och GIN-index.
Följande tabell visar källdata för detta diagram – värdena är varaktighet i sekunder. LOAD inkluderar analys av mbox-arkiven (från ett Python-skript), infogning i en tabell och diverse ytterligare uppgifter (återbygga e-posttrådar, etc.). SUBJECT/BODY INDEX hänvisar till skapandet av GIN-index i fulltext på ämnes-/kroppskolumnerna efter att data har laddats.
| LADDA | ÄMNESINDEX | BODY INDEX | |
| 8,3 | 2501 | 8 | 173 |
| 8.4 | 2540 | 4 | 78 |
| 9.0 | 2502 | 4 | 75 |
| 9.1 | 2046 | 4 | 84 |
| 9.2 | 2045 | 3 | 85 |
| 9.3 | 2049 | 4 | 85 |
| 9.4 | 2043 | 4 | 85 |
| 9.5 | 2034 | 4 | 82 |
| 9.6 | 2039 | 4 | 81 |
| 10 | 2037 | 4 | 82 |
| 11 | 2169 | 4 | 82 |
| 12 | 2164 | 4 | 79 |
| 13 | 2164 | 4 | 81 |
Uppenbarligen är prestandan ganska stabil – det har skett en ganska betydande förbättring (ungefär 20%) mellan 9,0 och 9,1. Jag är inte helt säker på vilken förändring som kan vara ansvarig för den här förbättringen - ingenting i 9.1-utgåvan verkar tydligt relevant. Det finns också en tydlig förbättring i uppbyggnaden av GIN-indexen i 8.4, vilket halverar tiden ungefär. Vilket är trevligt såklart. Intressant nog ser jag inte heller något uppenbart relaterat release notes-objekt för detta.
Hur är det dock med storlekarna på GIN-indexen? Det finns mycket mer variation, åtminstone fram till 9.4, då storleken på index sjunker från ~1GB till endast cirka 670MB (ungefär 30%).
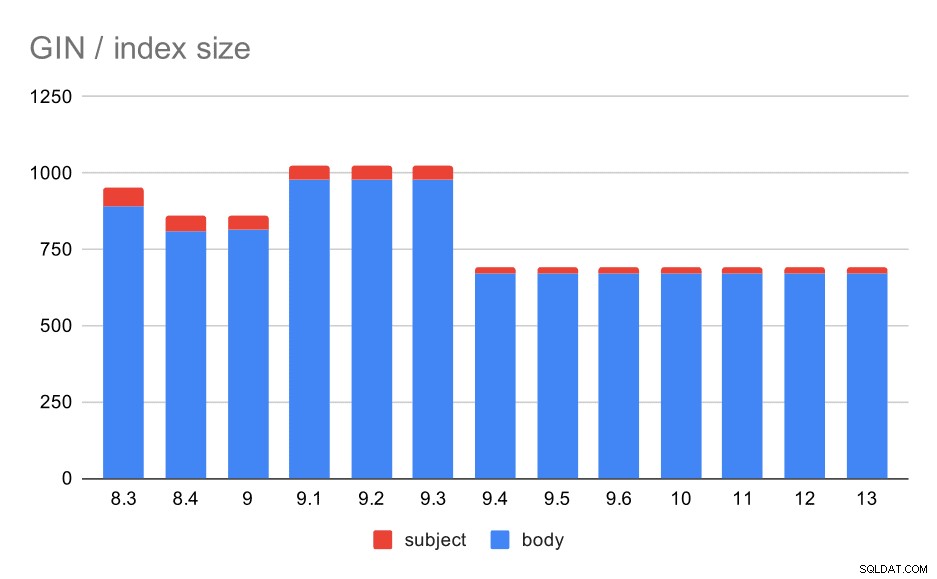
Storlek på GIN-index på meddelandets ämne/kropp. Värden är megabyte.
Följande tabell visar storlekarna på GIN-index på meddelandetext och ämne. Värdena är i megabyte.
| BODY | ÄMNE | |
| 8.3 | 890 | 62 |
| 8.4 | 811 | 47 |
| 9.0 | 813 | 47 |
| 9.1 | 977 | 47 |
| 9.2 | 978 | 47 |
| 9.3 | 977 | 47 |
| 9.4 | 671 | 20 |
| 9.5 | 671 | 20 |
| 9.6 | 671 | 20 |
| 10 | 672 | 20 |
| 11 | 672 | 20 |
| 12 | 672 | 20 |
| 13 | 672 | 20 |
I det här fallet tror jag att vi med säkerhet kan anta att denna snabbhet är relaterad till den här artikeln i 9.4 release notes:
- Minska GIN-indexstorleken (Alexander Korotkov, Heikki Linnakangas)
Storleksvariabiliteten mellan 8,3 och 9,1 tycks bero på förändringar i lemmatisering (hur ord omvandlas till den "grundläggande" formen). Bortsett från storleksskillnaderna, returnerar frågorna på de versionerna något olika antal resultat, till exempel.
GIN / frågor
Nu är huvuddelen av detta riktmärke – frågeprestanda. Alla siffror som presenteras här är för en enskild klient – vi har redan diskuterat klientens skalbarhet i den del som är relaterad till OLTP-prestanda, resultaten gäller även dessa frågor. (Dessutom har just den här maskinen bara 4 kärnor, så vi skulle inte komma särskilt långt när det gäller skalbarhetstestning ändå.)
VÄLJ ID, ämne FRÅN meddelanden WHERE tsvector @@ $1
Först, sökfrågan söker efter alla matchande dokument. För sökningar i "ämne"-kolumnen kan vi göra cirka 800 frågor per sekund (och det sjunker faktiskt lite i 9.1), men i 9.4 skjuter det plötsligt upp till 3000 frågor per sekund. För kolumnen "kropp" är det i princip samma historia – 160 frågor initialt, en minskning till ~90 frågor i 9.1 och sedan en ökning till 300 i 9.4.
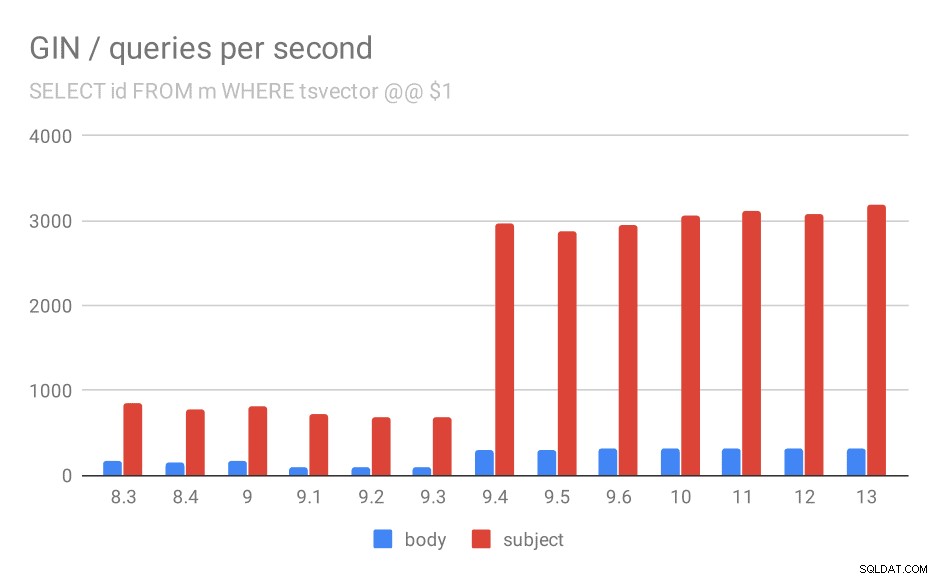
Antal frågor per sekund för den första frågan (hämtar alla matchande rader).
Och återigen, källdata – siffrorna är genomströmning (frågor per sekund).
| BODY | ÄMNE | |
| 8.3 | 168 | 848 |
| 8.4 | 155 | 774 |
| 9.0 | 160 | 816 |
| 9.1 | 93 | 712 |
| 9.2 | 93 | 675 |
| 9.3 | 95 | 692 |
| 9.4 | 303 | 2966 |
| 9.5 | 303 | 2871 |
| 9.6 | 310 | 2942 |
| 10 | 311 | 3066 |
| 11 | 317 | 3121 |
| 12 | 312 | 3085 |
| 13 | 320 | 3192 |
Jag tror att vi säkert kan anta att förbättringen i 9.4 är relaterad till denna artikel i release notes:
- Förbättra hastigheten på flernyckels GIN-sökningar (Alexander Korotkov, Heikki Linnakangas)
Så, ytterligare en 9.4-förbättring i GIN från samma två utvecklare – uppenbarligen gjorde Alexander och Heikki mycket bra arbete med GIN-index i 9.4-versionen 😉
VÄLJ ID, ämne FRÅN meddelanden WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
För frågan som rangordnar resultaten efter relevans med ts_rank och LIMIT, är det övergripande beteendet nästan exakt detsamma, jag tror inte att du behöver beskriva diagrammet i detalj.
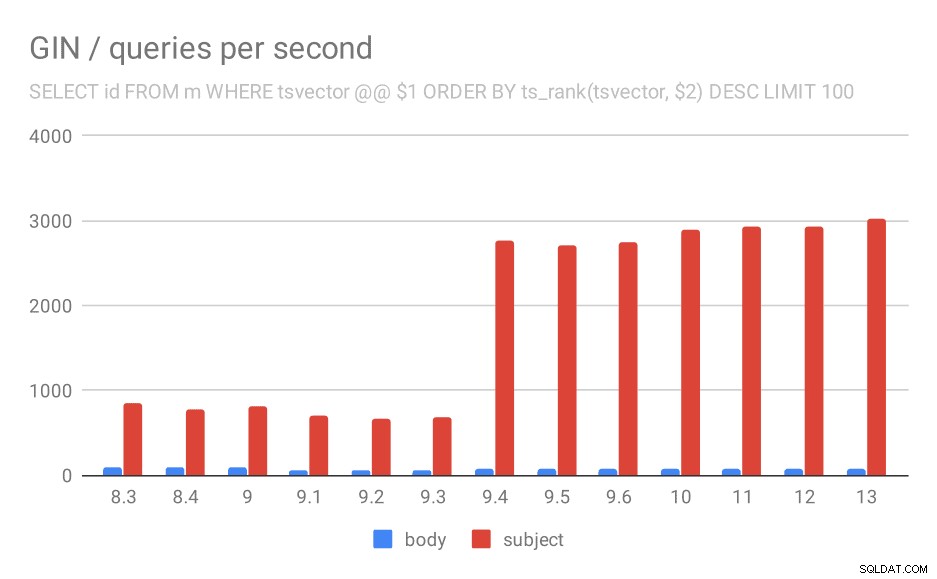
Antal frågor per sekund för den andra frågan (hämtar de mest relevanta raderna).
| BODY | ÄMNE | |
| 8.3 | 94 | 840 |
| 8.4 | 98 | 775 |
| 9.0 | 102 | 818 |
| 9.1 | 51 | 704 |
| 9.2 | 51 | 666 |
| 9.3 | 51 | 678 |
| 9.4 | 80 | 2766 |
| 9.5 | 81 | 2704 |
| 9.6 | 78 | 2750 |
| 10 | 78 | 2886 |
| 11 | 79 | 2938 |
| 12 | 78 | 2924 |
| 13 | 77 | 3028 |
Det finns dock en fråga - varför föll prestandan mellan 9,0 och 9,1? Det verkar vara en ganska betydande nedgång i genomströmningen – med cirka 50 % för kroppssökningar och 20 % för sökningar i meddelandeämnen. Jag har ingen tydlig förklaring till vad som hände, men jag har två observationer …
För det första ändrades indexstorleken - om du tittar på det första diagrammet "GIN / indexstorlek" och tabellen, ser du att indexet på meddelandekroppar växte från 813 MB till cirka 977 MB. Det är en betydande ökning, och det kan förklara en del av nedgången. Problemet är dock att indexet över ämnen inte växte alls, men frågorna blev också långsammare.
För det andra kan vi titta på hur många resultat frågorna gav. Den indexerade datamängden är exakt densamma, så det verkar rimligt att förvänta sig samma antal resultat i alla PostgreSQL-versioner, eller hur? Tja, i praktiken ser det ut så här:
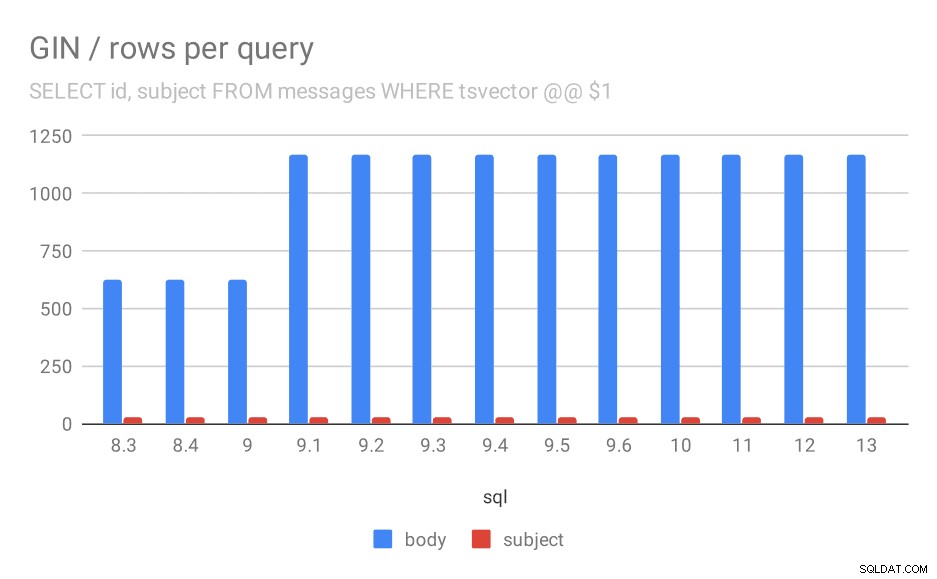
Antal rader som returneras för en fråga i genomsnitt.
| BODY | ÄMNE | |
| 8.3 | 624 | 26 |
| 8.4 | 624 | 26 |
| 9.0 | 622 | 26 |
| 9.1 | 1165 | 26 |
| 9.2 | 1165 | 26 |
| 9.3 | 1165 | 26 |
| 9.4 | 1165 | 26 |
| 9.5 | 1165 | 26 |
| 9.6 | 1165 | 26 |
| 10 | 1165 | 26 |
| 11 | 1165 | 26 |
| 12 | 1165 | 26 |
| 13 | 1165 | 26 |
Det är uppenbart att i 9.1 det genomsnittliga antalet resultat för sökningar i meddelandekroppar plötsligt fördubblas, vilket är nästan perfekt proportionell mot nedgången. Antalet resultat för ämnessökningar förblir dock detsamma. Jag har ingen bra förklaring till detta, förutom att indexeringen ändrades på ett sätt som gör det möjligt att matcha fler meddelanden, men göra det lite långsammare. Om du har bättre förklaringar vill jag gärna höra dem!
GiST / dataladdning
Nu, den andra typen av fulltextindex – GiST. Dessa index är förlustbringande, det vill säga kräver omkontroll av resultaten med hjälp av värden från tabellen. Så vi kan förvänta oss lägre genomströmning jämfört med GIN-indexen, men annars är det rimligt att förvänta sig ungefär samma mönster.
Laddningstiderna matchar verkligen GIN nästan perfekt – tiderna för att skapa index är olika, men det övergripande mönstret är detsamma. Hastighet upp i 9.1, liten nedgång i 11.
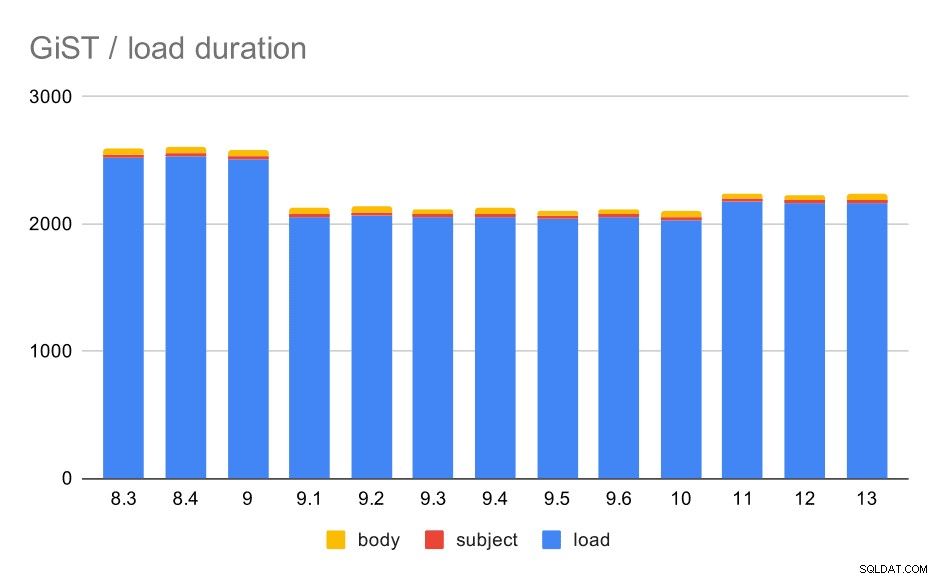
Dataladdningsoperationer med en tabell och GiST-index.
| LADDA | ÄMNE | BODY | |
| 8.3 | 2522 | 23 | 47 |
| 8.4 | 2527 | 23 | 49 |
| 9.0 | 2511 | 23 | 45 |
| 9.1 | 2054 | 22 | 46 |
| 9.2 | 2067 | 22 | 47 |
| 9.3 | 2049 | 23 | 46 |
| 9.4 | 2055 | 23 | 47 |
| 9.5 | 2038 | 22 | 45 |
| 9.6 | 2052 | 22 | 44 |
| 10 | 2029 | 22 | 49 |
| 11 | 2174 | 22 | 46 |
| 12 | 2162 | 22 | 46 |
| 13 | 2170 | 22 | 44 |
Indexstorleken förblev dock nästan konstant – det fanns inga GiST-förbättringar liknande GIN i 9.4, vilket minskade storleken med ~30%. Det finns en ökning av 9.1, vilket är ytterligare ett tecken på att fulltextindexeringen ändrades i den versionen för att indexera fler ord.
Detta stöds ytterligare av att det genomsnittliga antalet resultat med GiST är exakt detsamma som för GIN (med en ökning på 9,1).
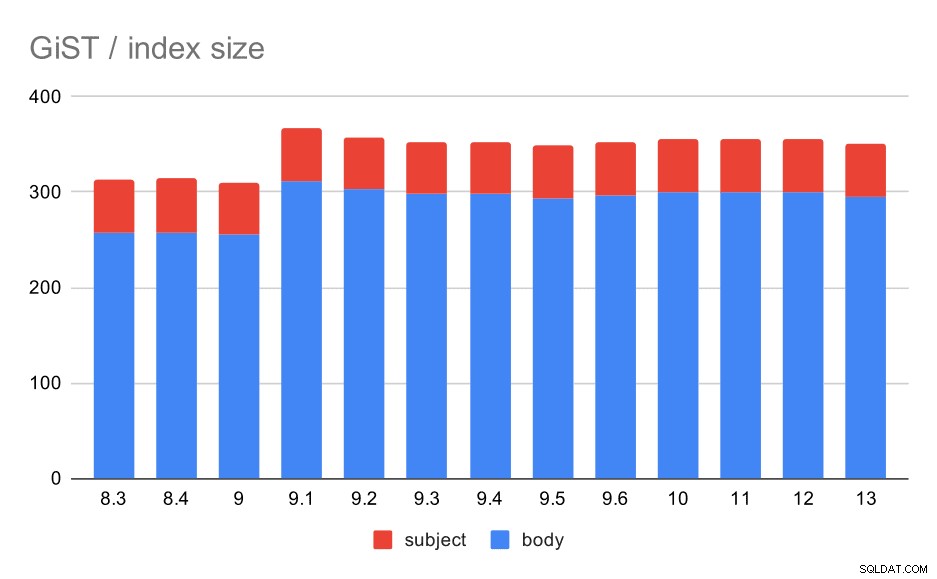
Storlek på GiST-index på meddelandets ämne/kropp. Värden är megabyte.
| BODY | ÄMNE | |
| 8.3 | 257 | 56 |
| 8.4 | 258 | 56 |
| 9.0 | 255 | 55 |
| 9.1 | 312 | 55 |
| 9.2 | 303 | 55 |
| 9.3 | 298 | 55 |
| 9.4 | 298 | 55 |
| 9.5 | 294 | 55 |
| 9.6 | 297 | 55 |
| 10 | 300 | 55 |
| 11 | 300 | 55 |
| 12 | 300 | 55 |
| 13 | 295 | 55 |
GiST / queries
Unfortunately, for the queries the results are nowhere as good as for GIN, where the throughput more than tripled in 9.4. With GiST indexes, we actually observe continuous degradation over the time.
SELECT id, subject FROM messages WHERE tsvector @@ $1
Even if we ignore versions before 9.1 (due to the indexes being smaller and returning fewer results faster), the throughput drops from ~270 to ~200 queries per second, with the main drop between 9.2 and 9.3.
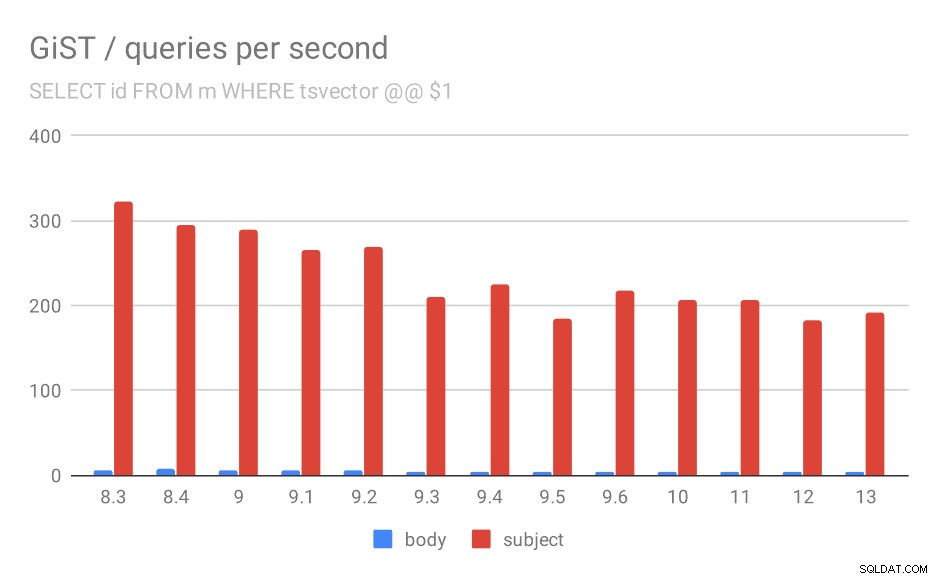
Number of queries per second for the first query (fetching all matching rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 322 |
| 8.4 | 7 | 295 |
| 9.0 | 6 | 290 |
| 9.1 | 5 | 265 |
| 9.2 | 5 | 269 |
| 9.3 | 4 | 211 |
| 9.4 | 4 | 225 |
| 9.5 | 4 | 185 |
| 9.6 | 4 | 217 |
| 10 | 4 | 206 |
| 11 | 4 | 206 |
| 12 | 4 | 183 |
| 13 | 4 | 191 |
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
And for queries with ts_rank the behavior is almost exactly the same.
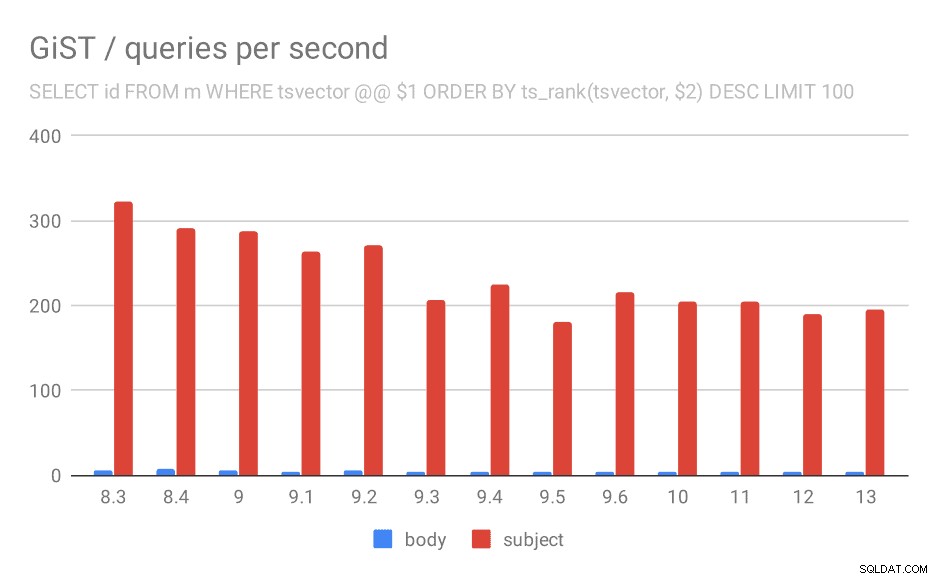
Number of queries per second for the second query (fetching the most relevant rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 323 |
| 8.4 | 7 | 291 |
| 9.0 | 6 | 288 |
| 9.1 | 4 | 264 |
| 9.2 | 5 | 270 |
| 9.3 | 4 | 207 |
| 9.4 | 4 | 224 |
| 9.5 | 4 | 181 |
| 9.6 | 4 | 216 |
| 10 | 4 | 205 |
| 11 | 4 | 205 |
| 12 | 4 | 189 |
| 13 | 4 | 195 |
I’m not entirely sure what’s causing this, but it seems like a potentially serious regression sometime in the past, and it might be interesting to know what exactly changed.
It’s true no one complained about this until now – possibly thanks to upgrading to a faster hardware which masked the impact, or maybe because if you really care about speed of the searches you will prefer GIN indexes anyway.
But we can also see this as an optimization opportunity – if we identify what caused the regression and we manage to undo that, it might mean ~30% speedup for GiST indexes.
Summary and future
By now I’ve (hopefully) convinced you there were many significant improvements since PostgreSQL 8.3 (and in 9.4 in particular). I don’t know how much faster can this be made, but I hope we’ll investigate at least some of the regressions in GiST (even if performance-sensitive systems are likely using GIN). Oleg and Teodor and their colleagues were working on more powerful variants of the GIN indexing, named VODKA and RUM (I kinda see a naming pattern here!), and this will probably help at least some query types.
I do however expect to see features buil extending the existing full-text capabilities – either to better support new query types (e.g. the new index types are designed to speed up phrase search), data types and things introduced by recent revisions of the SQL standard (like jsonpath).