Obs:Den här artikeln visar migreringen av en relationsdatabasmodell (RDB) till stjärnschemat med hjälp av Eclipse IDE för Voracity (och dess inkluderade produkter), IRI Workbench, efter en introduktion till båda arkitekturerna. Om du är intresserad av att migrera din RDB eller data till en Data Vault 2.0-modell kommer en ny Workbench-guide att debutera på World Wide Data Vault Consortium i maj 2019; prenumerera på IRI-bloggen för att få de steg-för-steg-instruktionerna så snart de publiceras!
Ett datalager (DW) är en samling data som extraherats från det operativa eller transaktionsmässiga systemet i ett företag, omvandlats för att åtgärda inkonsekvenser och sedan arrangeras för att stödja snabb analys och/eller rapportering. DW kräver ett schema eller logisk beskrivning och grafisk representation av dess operativa databas. Den här artikeln berör dessa ämnen samtidigt som den ger en vägledning för att gå från ett konventionellt relationsdatabasschema till ett populärt DW-schema som kallas stjärnschema.
Stjärnschema kontra relationell
De flesta relationsdatastrukturer illustreras i entity-relationship (ER) diagram. Ett ER-diagram används i utvecklingen av konceptuella modeller för ett databashanteringssystem för onlinetransaktionsbehandling (OLTP). Det är källan från vilken tabellstrukturen översätts.
Stjärnschemat är dock den allmänt accepterade standarden för den underliggande tabellstrukturen i ett datalager. Dess enkla stjärnform (när ER-diagram visas) visar faktatabellen (som innehåller transaktionsvärden eller mått) i mitten och dimensionstabeller (som innehåller beskrivande eller attributiva värden) som strålar ut från den. Vanligtvis är faktatabellen i tredje-normal form (3NF), medan dimensionstabeller är denormaliserade.
De grundläggande skillnaderna mellan en enhetsrelationell (ER) modell och en stjärnmodell är att:
- ER-modeller använder logiska och fysiska strukturer för normaliserad databasdesign
- Dimensionsmodeller använder en fysisk struktur för denormaliserad databasdesign
För att se hur IRI-programvara kan av/normalisera data genom svängning av rad-kolumn, klicka här.
Bakgrund för konverteringsprocessen
I den här artikeln visar jag hur man omvandlar data från en relationsmodell till stjärna med jobb som du bör definiera mer eller mindre manuellt, men som kan skapas och köras automatiskt och enkelt ändras.
Det du kommer att se här är IRI:s 4GL-data och jobbspecifikationer – uttryckta i "SortCL"-skript[1] – som mappar data till dimensionstabeller och sammanfogar data till den centrala faktatabellen. SortCL är det centrala programmet för datamanipulation och kartläggning i IRI Voracity datahantering och ETL-plattformen. Men att förstå metodiken och mappningarna i mina SortCL-jobb är nyckeln här, inte skriptsyntaxen.
Det gratis Eclipse GUI, IRI Workbench, ger en syntaxmedveten SortCL-redigerare, såväl som grafiska konturer och dialogrutor, arbetsflödes- och mappningsdiagram och intuitiva jobbguider, för att automatiskt bygga eller ändra dessa skript om du inte vill göra det för hand. FYI, IRI använder samma metadata och GUI för att profilera och diagramma DB:er, generera testdata, utföra ETL, formatera rapporter, maskera PII, fånga in ändrad data, migrera och replikera data, rensa och validera data, etc.
Workbench använder en förbättrad version av plugin-programmet Data Tools Platform (DTP) för Eclipse för att ansluta till databaser över JDBC och för att möjliggöra SQL-operationer och IRI-metadatautbyte i vyn Data Source Explorer (DSE). I det här fallet stöder Workbench:
- skapandet och populationen av begränsade Oracle-testtabeller (källa) via SortCL (eller IRI RowGen jobb, enligt denna artikel)
- mappningen av entitetstabelldata till dimensionstabeller via SortCL
- mappningen av faktaelement som en när relation för att associera principdimensionstabellen; d.v.s. utföra en flerbordskoppling i SortCL för att skapa faktatabellen
- population av alla måltabeller (stjärnschema)
- ER-diagram för käll- och målscheman
Entitetstyperna i min ursprungliga relationsmodell är:Dept, Emp, Project, Category, Item, Item_Use och Sale:
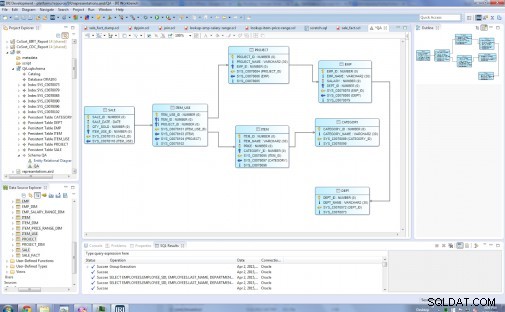
Innan …
Nästa diagram visar den slutliga Stjärnmodellen med åtta dimensionstabeller och en faktatabell. Dimensionstabellerna är: Dept_Dim, Emp_Dim, Emp_Salary_Range_Dim, Project_Dim, Category_Dim, Item_Price_Range_Dim, Item_Dim. Faktatabellen i mitten är Sale_Fact, som innehåller nycklar till alla dimensionstabeller.

... Efter
Konverteringssteg
- Definiera och skapa faktatabellen
Strukturen för tabellen Sale_Fact visas i det här dokumentet. Den primära nyckeln är sale_id, och resten av attributen är främmande nycklar som ärvts från dimensionstabellerna. Jag använder en Oracle-databas (även om vilken RDB som helst) kopplad till Workbench DSE (via JDBC) och SortCL för datatransformation och mappning ( via ODBC). Jag skapade mina tabeller i SQL-skript som redigerades i DSE:s SQL-klippbok och kördes i Workbench.
- Definiera och skapa dimensionstabellerna
Använd samma teknik och metadata som länkats ovan för att skapa dessa dimensionstabeller som kommer att ta emot relationsdata som mappas från SortCL-jobb i nästa steg:Category_Dim tabell, Dept to Dept_Dim, Project to Project_Dim, Item to Item_Dim och Emp to Emp_Dim. Du kan köra det .SQL-programmet med all CREATE-logik på en gång för att bygga tabellerna.
- Flytta den ursprungliga Entity-tabelldatan till dimensionstabellerna
Definiera och kör SortCL-jobben som visas här för att mappa (RowGen-skapat test) data från relationsschemat till dimensionstabeller för Star-schemat. Specifikt läser dessa skript in data från kategoritabellen till tabellen Category_Dim, Dept till Dept_Dim, Project to Project_Dim, Item to Item_Dim och Emp to Emp_Dim.
- Fyll i faktatabellen
Använd SortCL för att sammanfoga data från ursprungliga Sale, Emp, Project, Item_Use, Item, Category entitetstabeller för att förbereda data för den nya Sale_Fact-tabellen. Använd det andra skriptet (gå med jobb) här.
För att förbättra vårt exempel kommer vi också att använda SortCL för att introducera ny dimensionsdata i Star-schemat som min faktatabell också kommer att förlita sig på. Du kan se dessa ytterligare tabeller i stjärndiagrammet ovan som inte fanns i mitt relationsschema:Emp_Salary_Range_Dim och Item_Price_Range_Dim. Dessa tabeller skapas i samma .SQL-fil för faktatabellerna och andra dimensionstabeller.
Faktatabellen behöver data för emp_salary_range_id och item_price_range_id från dessa tabeller för att representera värdeintervallet i dessa dimensionstabeller. När jag till exempel laddar de dimensionella prisvärdena i datalagret, vill jag tilldela dem ett prisintervall:
| Artikelpris | Range_Id | Range_Name | Range_End |
|---|---|---|---|
| 1 | Låg | 1 | 100 |
| 2 | Mellan | 101 | 500 |
| 3 | Hög | 501 | 999 |
Det enklaste sättet att tilldela intervall-ID:n i jobbskriptet (det vill säga att förbereda data för min Sale_Fact-tabell) är att använda en IF-THEN-ELSE-sats i utdatasektionen. Se den här artikeln om bucketing-värden för bakgrund.
Hur som helst, jag skapade hela det här jobbet med CoSort New Join Job guiden i Workbench. Och när jag väl körde den fylldes min faktatabell i:
 Sale_Fact-tabellvisning i IRI Workbench DSE
Sale_Fact-tabellvisning i IRI Workbench DSE
Slutsats
Den stora fördelen med dimensionell datarepresentation är att en databasstrukturs komplexitet minskar. Detta gör databasen lättare för människor att förstå och skriva frågor mot genom att minimera antalet tabeller och därmed antalet anslutningar som krävs. Som tidigare nämnts optimerar dimensionsmodeller också frågeprestanda. Den har dock svaghet såväl som styrka. Stjärnschemats fasta struktur begränsar frågorna. Så eftersom det gör de vanligaste frågorna lätta att skriva, begränsar det också hur data kan analyseras.
IRI Workbench GUI for Voracity har en kraftfull och omfattande uppsättning verktyg som förenklar dataintegration, inklusive skapande, underhåll och expansion av datalager. Med detta intuitiva, lättanvända gränssnitt möjliggör Voracity snabb, flexibel, end-to-end ETL-process (extrahera, transformera, ladda) som involverar datastrukturer över olika plattformar.
I ETL-operationer extraheras data från olika källor, omvandlas separat och läses in i ett datalager och eventuellt andra mål. Att bygga ETL-processen är potentiellt en av de största uppgifterna med att bygga ett lager; det är komplext och tidskrävande. IRI:s ETL-metod stöder denna process på ett mycket effektivt och databasoberoende sätt genom att utföra all dataintegrering och iscensättning i filsystemet.
[1] Om du är en syntaxhund, observera att SortCL-skript som används i IRI CoSort-produkten eller IRI Voracity-plattformen stöder samma syntax och datadefinitioner som IRI RowGen för generering av testdata, IRI NextForm för datamigrering och IRI FieldShield för datamaskering. Alla dessa verktyg stöds i IRI Workbench GUI, och deras metadata kan också delas och teamhanteras för versionskontroll, jobb/datalinje och säkerhet i molnet.
[2] Så här visar du E-R-diagram i IRI Workbench:
- Välj Nytt IRI-projekt och skapa en ny mapp
- Välj den mappen och markera alla tillämpliga databastabeller i Data Source Explorer; högerklicka sedan på IRI, New ER-Diagram
- En fil (Schema.QA) kommer att skapas
- Högerklicka på den filen och välj New Representation, New Entity Relation Diagram.
[3] Delarna i ER-diagrammet som illustrerar sådana modeller inkluderar:
- definierade entitetstyper
- definierade attribut
- förhållandet mellan entitetstyperna
- övergripande bild, eller konceptuellt diagram
[4] IRI FACT och SQL*Loader är bulkextraktion respektive laddningsalternativ.