I den första delen av den här bloggserien har jag presenterat ett par benchmarkresultat som visar hur PostgreSQL OLTP-prestanda förändrats sedan 8.3, släppt 2008. I den här delen planerar jag att göra samma sak utom för analytiska / BI-frågor, bearbeta stora mängder data.
Det finns ett antal branschriktmärken för att testa denna arbetsbelastning, men förmodligen den vanligaste är TPC-H, så det är vad jag kommer att använda för det här blogginlägget. Det finns också TPC-DS, ett annat TPC-riktmärke för att testa beslutsstödssystem, som kan ses som en utveckling eller ersättning av TPC-H. Jag har bestämt mig för att hålla mig till TPC-H av ett par anledningar.
För det första är TPC-DS mycket mer komplex, både vad gäller schema (fler tabeller) och antal frågor (22 mot 99). Att ställa in det här ordentligt, särskilt när man hanterar flera PostgreSQL-versioner, skulle vara mycket svårare. För det andra använder vissa av TPC-DS-frågorna funktioner som inte stöds av äldre PostgreSQL-versioner (t.ex. grupperingsuppsättningar), vilket gör dessa frågor irrelevanta för vissa versioner. Och slutligen, jag skulle säga att folk är mycket mer bekanta med TPC-H jämfört med TPC-DS.
Målet med detta är inte att tillåta jämförelse med andra databasprodukter, bara att ge en rimlig långsiktig karakterisering av hur PostgreSQL-prestanda utvecklats sedan PostgreSQL 8.3.
Obs :För en mycket intressant analys av TPC-H benchmark rekommenderar jag starkt uppsatsen "TPC-H Analyzed:Hidden Messages and Lessons Learned from an Influential Benchmark" från Boncz, Neumann och Erling.
Hårdvaran
De flesta av resultaten i det här blogginlägget kommer från den "större lådan" jag har på vårt kontor, som har dessa parametrar:
- 2x E5-2620 v4 (16 kärnor, 32 trådar)
- 64 GB RAM
- Intel Optane 900P 280GB NVMe SSD (data)
- 3 x 7.2k SATA RAID0 (tillfälligt tabellutrymme)
- kärna 5.6.15, ext4 filsystem
Jag är säker på att du kan köpa betydligt tjockare maskiner, men jag tror att detta är tillräckligt bra för att ge oss relevant information. Det fanns två konfigurationsvarianter – en med parallellism inaktiverad, en med parallellism aktiverad. De flesta parametervärdena är desamma i båda fallen, inställda på tillgängliga hårdvaruresurser (CPU, RAM, lagring). Du kan hitta mer detaljerad information om konfigurationen i slutet av detta inlägg.
Riktmärket
Jag vill göra det väldigt tydligt att det inte är mitt mål att implementera ett giltigt TPC-H-riktmärke som kan klara alla kriterier som krävs av TPC. Mitt mål är att utvärdera hur prestanda för olika analytiska frågor förändrats över tiden, inte jaga något abstrakt mått på prestanda per dollar eller något liknande.
Så jag har bestämt mig för att bara använda en delmängd av TPC-H - i princip bara ladda data och köra de 22 frågorna (samma parametrar på alla versioner). Det finns inga datauppdateringar, datamängden är statisk efter den första laddningen. Jag har valt ett antal skalfaktorer, 1, 10 och 75, så att vi har resultat för passar-i-delade-buffertar (1), passar-i-minne (10) och mer-än-minne (75) . Jag skulle gå på 100 för att göra det till en "trevlig sekvens", som inte skulle passa in i 280 GB-lagringen i vissa fall (tack vare index, temporära filer, etc.). Observera att skalfaktor 75 inte ens erkänns av TPC-H som en giltig skalfaktor.
Men är det ens vettigt att jämföra 1 GB eller 10 GB datamängder? Människor tenderar att fokusera på mycket större databaser, så det kan verka lite dumt att bry sig om att testa dem. Men jag tror inte att det skulle vara användbart – den stora majoriteten av databaser i det vilda är ganska små, enligt min erfarenhet. Och även när hela databasen är stor, arbetar folk vanligtvis bara med en liten delmängd av den – senaste data, olösta beställningar etc. Så jag tror att det är vettigt att testa även med dessa små datamängder.
Data laddas
Låt oss först se hur lång tid det tar att ladda data till databasen – utan och med parallellitet. Jag visar bara resultat från datauppsättningen på 75 GB, eftersom det övergripande beteendet är nästan detsamma för de mindre fallen.
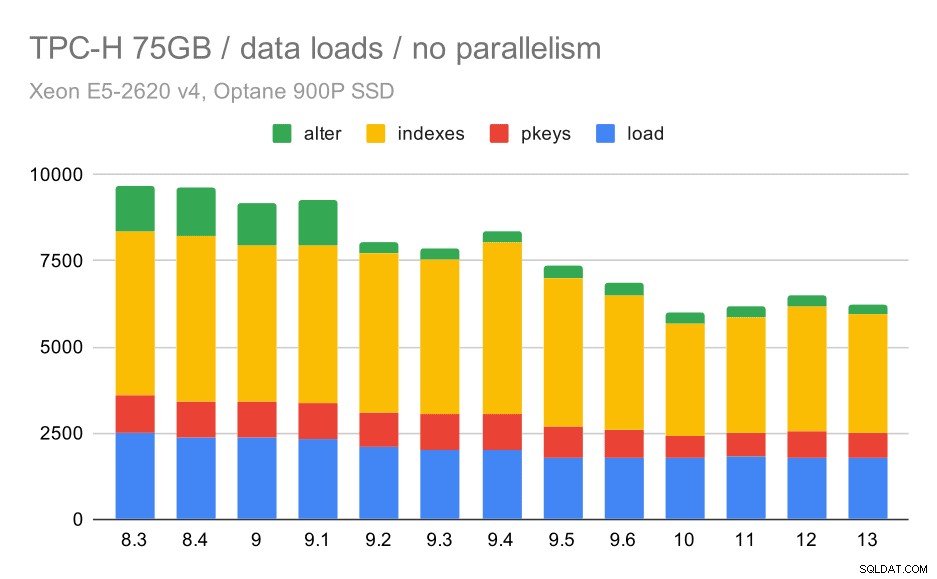
TPC-H-dataladdningslängd – skala 75 GB, ingen parallellitet
Du kan tydligt se att det finns en stadig trend av förbättringar, som rakar bort cirka 30 % av varaktigheten bara genom att förbättra effektiviteten i alla fyra stegen – KOPIERA, skapa primärnycklar och index och (särskilt) ställa in främmande nycklar. "Ändra"-förbättringen i 9.2 är särskilt tydlig.
| KOPIERA | PKEYS | INDEX | ALTER | |
| 8.3 | 2531 | 1156 | 1922 | 1615 |
| 8.4 | 2374 | 1171 | 1891 | 1370 |
| 9.0 | 2374 | 1137 | 1797 | 1282 |
| 9.1 | 2376 | 1118 | 1807 | 1268 |
| 9.2 | 2104 | 1120 | 1833 | 1157 |
| 9.3 | 2008 | 1089 | 1836 | 1229 |
| 9.4 | 1990 | 1168 | 1818 | 1197 |
| 9.5 | 1982 | 1000 | 1903 | 1203 |
| 9.6 | 1779 | 872 | 1797 | 1174 |
| 10 | 1773 | 777 | 1469 | 1012 |
| 11 | 1807 | 762 | 1492 | 758 |
| 12 | 1760 | 768 | 1513 | 741 |
| 13 | 1782 | 836 | 1587 | 675 |
Låt oss nu se hur att möjliggöra parallellism förändrar beteendet. Följande diagram jämför resultat med parallellism aktiverad – markerade med "(p)" – med resultat med parallellism inaktiverad.
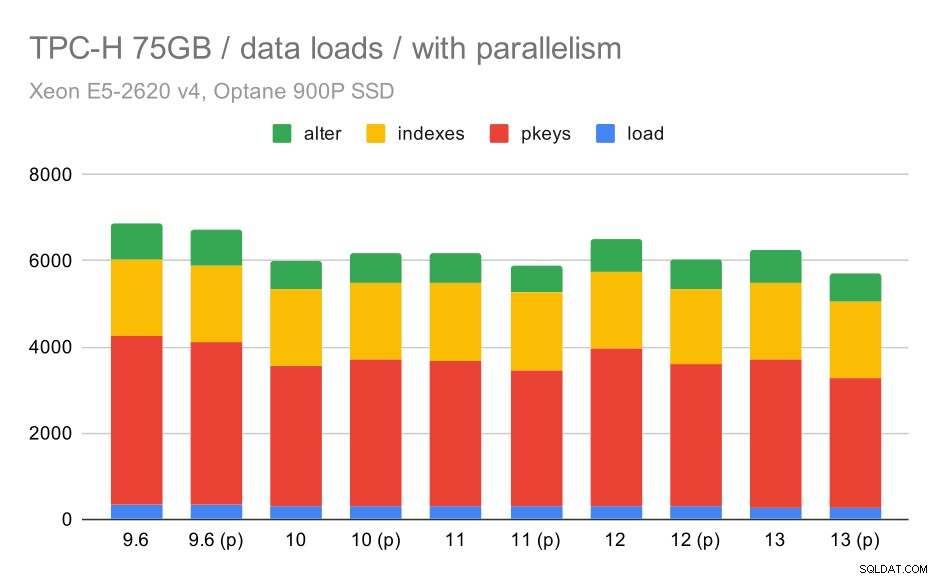
TPC-H-dataladdningslängd – skala 75 GB, parallellitet aktiverad.
Tyvärr verkar det som om effekten av parallellism är mycket begränsad i det här testet – det hjälper lite, men skillnaderna är ganska små. Så den totala förbättringen är fortfarande cirka 30 %.
| KOPIERA | PKEYS | INDEX | ALTER | |
| 9.6 | 344 | 3902 | 1786 | 831 |
| 9.6 (p) | 346 | 3781 | 1780 | 832 |
| 10 | 318 | 3259 | 1766 | 671 |
| 10 (p) | 315 | 3400 | 1769 | 693 |
| 11 | 319 | 3357 | 1817 | 690 |
| 11 (p) | 320 | 3144 | 1791 | 618 |
| 12 | 314 | 3643 | 1803 | 754 |
| 12 (p) | 313 | 3296 | 1752 | 657 |
| 13 | 276 | 3437 | 1790 | 744 |
| 13 (P) | 274 | 3011 | 1770 | 641 |
Frågor
Nu kan vi ta en titt på frågor. TPC-H har 22 frågemallar – jag har genererat en uppsättning faktiska frågor och kört dem på alla versioner två gånger – först efter att ha släppt alla cachar och startat om instansen, sedan med den uppvärmda cachen. Alla siffror som presenteras i diagrammen är de bästa av dessa två körningar (i de flesta fall är det den andra, naturligtvis).
Ingen parallellism
Utan parallellitet är resultaten på den minsta datamängden ganska tydliga – varje stapel är uppdelad i flera delar med olika färger för var och en av de 22 frågorna. Det är svårt att säga vilken del som mappas till vilken exakt fråga, men det räcker för att identifiera fall när en fråga förbättras eller blir mycket sämre mellan två körningar. Till exempel i det första diagrammet är det mycket tydligt att Q21 blev mycket snabbare mellan 8,3 och 8,4.
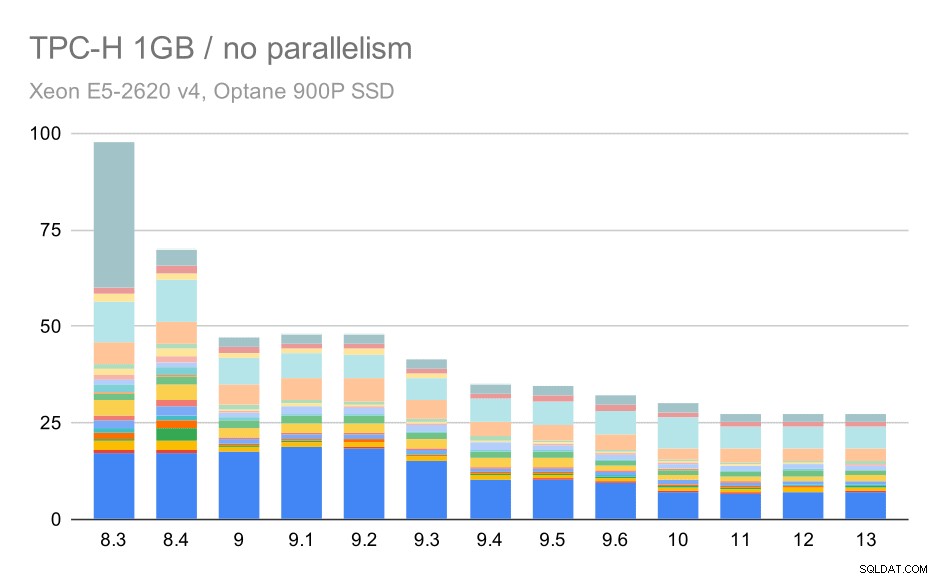
TPC-H-frågor på liten datamängd (1 GB) – parallellism inaktiverad
För 10 GB-skalan är resultaten något svåra att tolka, eftersom en av frågorna (Q21) på 8.3 tar så lång tid att köra att den förvärrar allt annat.
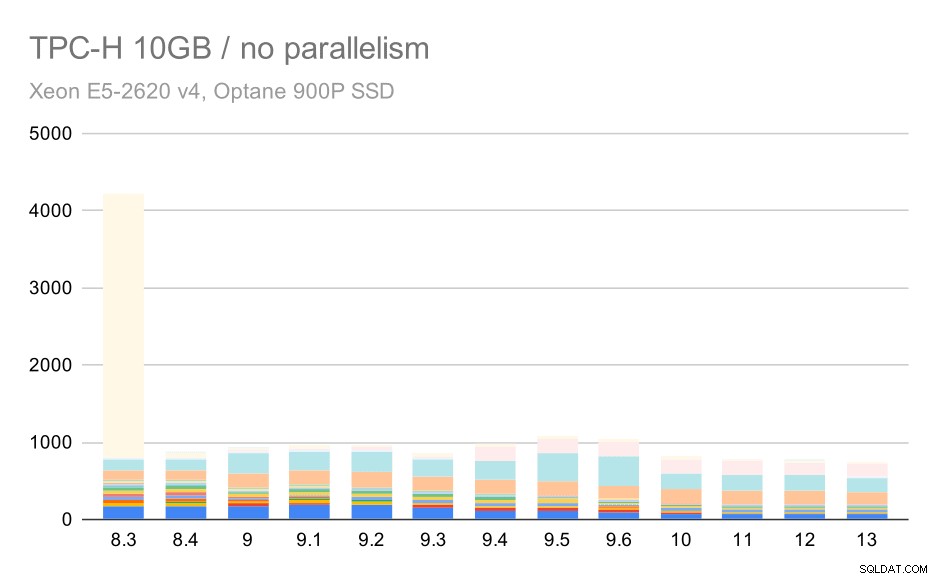
TPC-H-frågor på medium datamängd (10 GB) – parallellism inaktiverad
Så låt oss se hur diagrammet skulle se ut utan Q21:
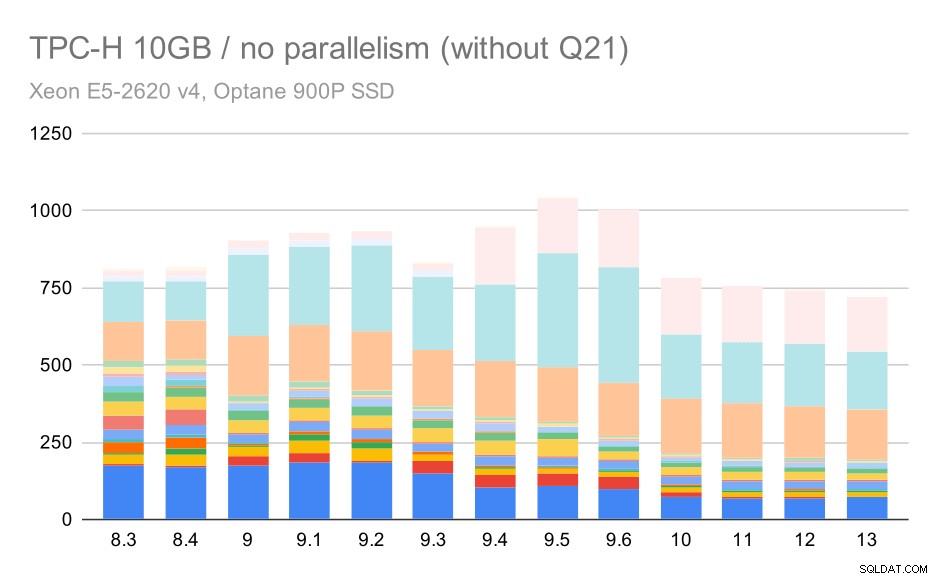
TPC-H-frågor på medium datauppsättning (10 GB) – parallellism inaktiverad, utan problematisk Q2
Okej, det är lättare att läsa. Vi kan tydligt se att de flesta av frågorna (upp till Q17) gick snabbare, men sedan blev två av frågorna (Q18 och Q20) något långsammare. Vi kommer att se ett liknande problem på den största datamängden, så jag ska diskutera vad som kan vara grundorsaken då.
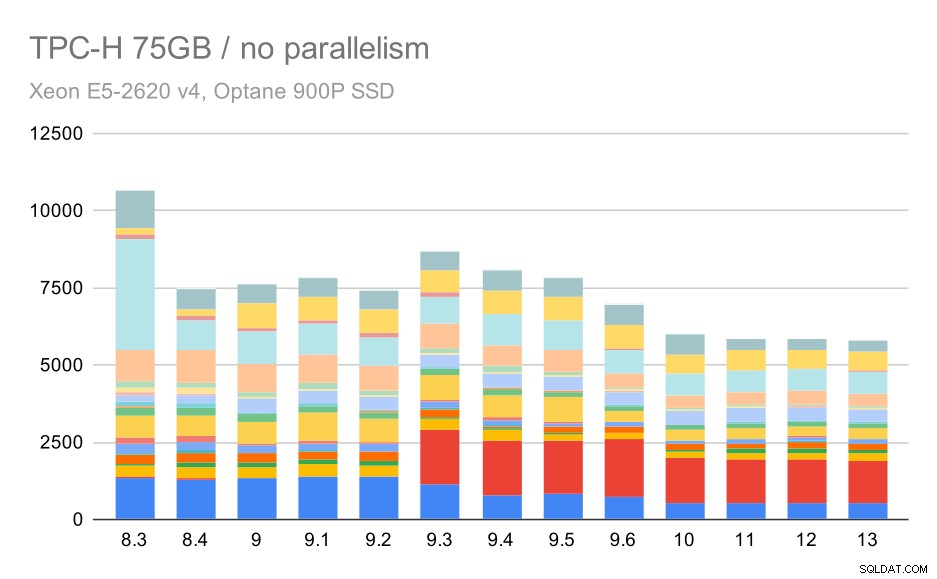
TPC-H-frågor på stor datamängd (75 GB) – parallellism inaktiverad
Återigen ser vi en plötslig ökning för en av frågorna i 9.3 – den här gången är det Q2, utan vilket diagrammet ser ut så här:
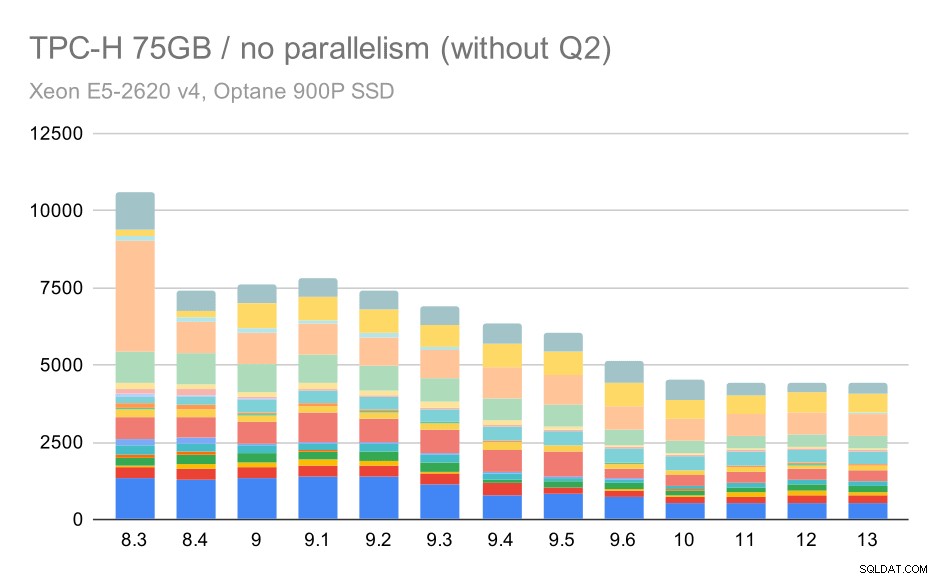
TPC-H-frågor på stor datamängd (75 GB) – parallellism inaktiverad, utan problematisk Q2
Det är en ganska trevlig förbättring i allmänhet, som snabbar upp hela exekveringen från ~2,7 timmar till endast ~1,2h, bara genom att göra planeraren och optimeraren smartare, och genom att göra executorn mer effektiv (kom ihåg att parallelliteten inaktiverades i dessa körningar) .
Så vad kan problemet vara med Q2, vilket gör det långsammare i 9.3? Det enkla svaret är att varje gång du gör planeraren och optimeraren smartare – antingen genom att konstruera nya typer av vägar/planer, eller genom att göra den beroende av viss statistik, innebär det också att nya misstag kan göras när statistiken eller uppskattningarna är felaktiga. I Q2 refererar WHERE-satsen till en sammanställd underfråga – en förenklad version av frågan kan se ut så här:
Välj 1 från Partsuppenwhere var PS_SUPPLYCOST =(SELECT MIN (PS_SUPPLYCOST) FRÅN PARTSUPP, LEVERANTER, NATION, Region där P_Partkey =PS_Partkey och S_SuppKey =PS_SuppKey och S_NationKey =N_NationKey och N_regionkey =R_region och r_name =')Problemet är att vi inte känner till medelvärdet vid planeringstillfället, vilket gör det omöjligt att beräkna tillräckligt bra uppskattningar för WHERE-tillståndet. Det faktiska Q2 innehåller ytterligare kopplingar, och planeringen av dessa beror i grunden på goda uppskattningar av de anslutna förbindelserna. I äldre versioner verkar optimeraren ha gjort rätt, men sedan i 9.3 gjorde vi det smartare på något sätt, men med den dåliga uppskattningen lyckas den inte fatta rätt beslut. Med andra ord, de goda planerna i äldre versioner var bara tur, tack vare planerarens begränsningar.
Jag skulle slå vad om att regressionerna för Q18 och Q20 på den mindre datamängden också orsakas av något liknande, även om jag inte har undersökt dem i detalj.
Jag tror att några av dessa optimeringsproblem kan åtgärdas genom att justera kostnadsparametrarna (t.ex. random_page_cost etc.) men jag har inte provat det på grund av tidsbrist. Det visar dock att uppgraderingar inte automatiskt förbättrar alla frågor – ibland kan en uppgradering utlösa en regression, så lämplig testning av din applikation är en bra idé.
Parallellism
Så låt oss se hur mycket frågeparallellism förändrar resultaten. Återigen kommer vi bara att titta på resultat från utgåvor sedan 9.6 har märkt resultat med "(p)" där parallell sökning är aktiverad.
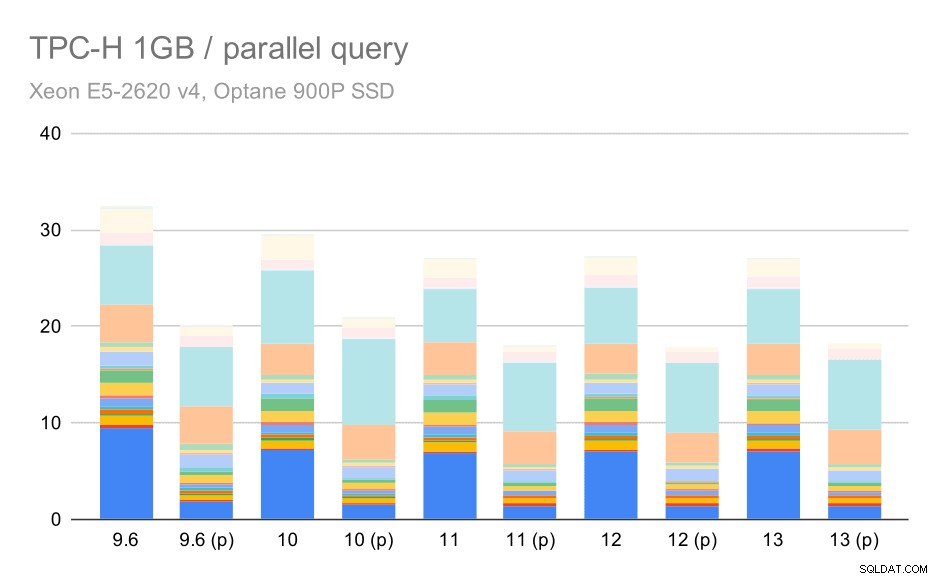
TPC-H-frågor på liten datamängd (1 GB) – parallellism aktiverad
Uppenbarligen hjälper parallellism en hel del – den rakar bort cirka 30 % även på denna lilla datamängd. På den medium datamängden är det inte mycket skillnad mellan vanliga och parallella körningar:
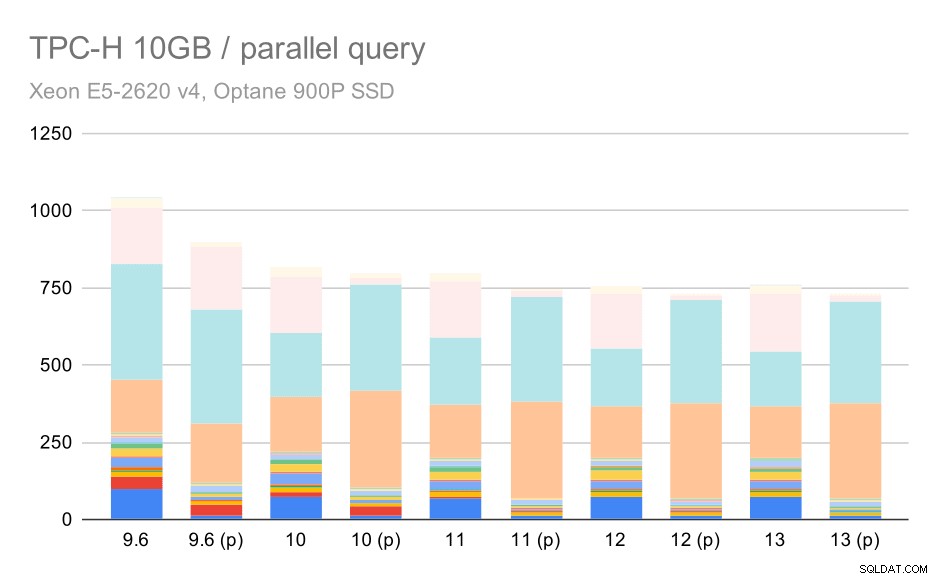
TPC-H-frågor på medium datamängd (10 GB) – parallellism aktiverad
Detta är ännu en demonstration av den redan diskuterade frågan – att möjliggöra parallellitet gör det möjligt att överväga ytterligare frågeplaner, och uppenbarligen stämmer inte uppskattningarna eller kostnaden överens med verkligheten, vilket resulterar i dåliga planval.
Och slutligen den stora datamängden, där de fullständiga resultaten ser ut så här:
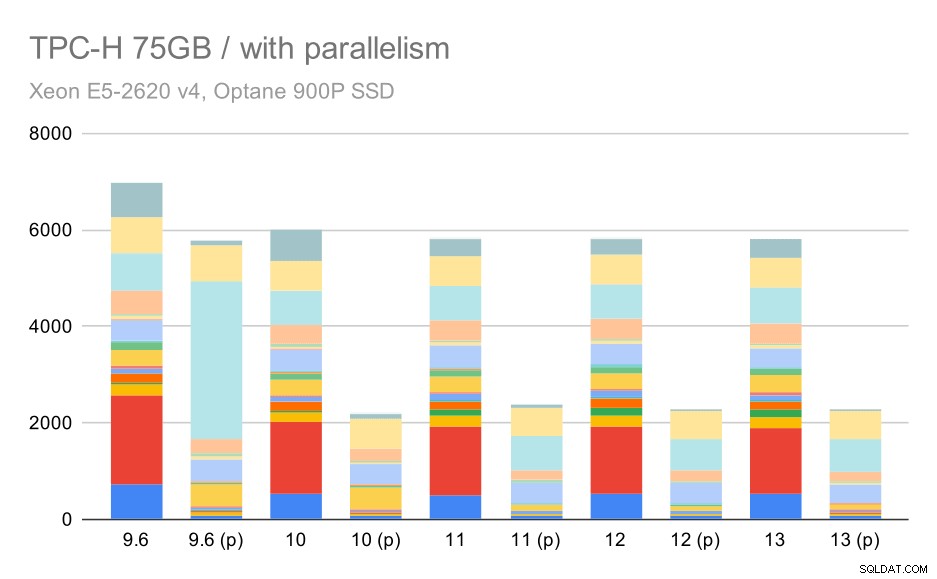
TPC-H-förfrågningar på stor datamängd (75 GB) – parallellism aktiverad
Att möjliggöra parallellismen fungerar här till vår fördel – optimeraren lyckas bygga en billigare parallellplan för Q2, och åsidosätter det dåliga planvalet som introducerades i 9.3. Men bara för fullständighetens skull, här är resultaten utan Q2.
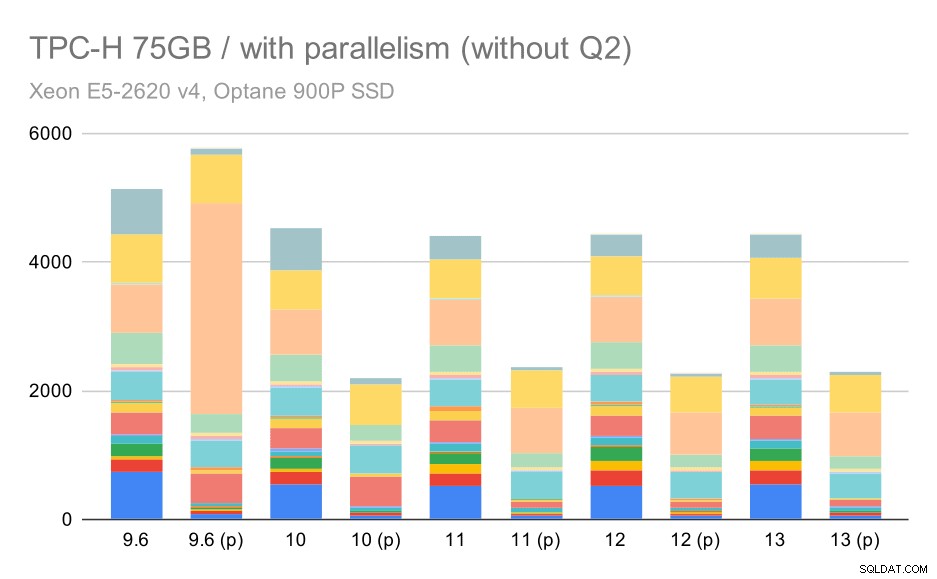
TPC-H-frågor på stor datamängd (75 GB) – parallellitet aktiverad, utan problematisk Q2
Även här kan du upptäcka några dåliga val av parallella plan – till exempel är parallellplanen för Q9 sämre fram till 11 där den blir snabbare – troligen tack vare 11 stödjande ytterligare parallella exekveringsnoder. Å andra sidan blir vissa parallella frågor (Q18, Q20) långsammare på 11, så det är inte bara regnbågar och enhörningar.
Sammanfattning och framtid
Jag tycker att dessa resultat på ett bra sätt visar optimeringsimplementeringen sedan PostgreSQL 8.3. Testerna med parallellism inaktiverad illustrerar förbättringar i effektivitet (dvs. att göra mer med samma mängd resurser) – dataladdningarna blev ~30 % snabbare och frågorna blev ~2 gånger snabbare. Det är sant att jag har stött på några problem med ineffektiva frågeplaner, men det är en inneboende risk när man gör frågeplaneraren smartare. Vi arbetar kontinuerligt med att göra resultaten mer tillförlitliga, och jag är säker på att jag skulle kunna lindra de flesta av dessa problem genom att justera konfigurationen lite.
Resultaten med parallellism aktiverad visar att vi kan utnyttja extra resurser effektivt (i synnerhet CPU-kärnor). Dataladdningarna verkar inte dra så mycket nytta av detta – åtminstone inte i det här riktmärket, men effekten på exekveringen av frågor är betydande, vilket resulterar i ~2x snabbare (även om olika frågor påverkas olika, naturligtvis).
Det finns många möjligheter att förbättra detta i framtida PostgreSQL-versioner. Till exempel finns det en patch-serie som implementerar parallellism för COPY, vilket påskyndar dataladdningen. Det finns olika patchar som förbättrar exekveringen av analytiska frågor – från små lokaliserade optimeringar till stora projekt som kolumnär lagring och exekvering, sammanlagd push-down, etc. Mycket kan vinnas genom att använda deklarativ partitionering också – en funktion som jag mest ignorerade när jag arbetade med detta benchmark, helt enkelt för att det skulle öka omfattningen alldeles för mycket. Och jag är säker på att det finns många andra möjligheter som jag inte ens kan föreställa mig, men smartare människor i PostgreSQL-communityt arbetar redan med dem.
Bilaga:PostgreSQL-konfiguration
Parallellism inaktiverad
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =0max_parallel_maintenance_workers =0# optimizerdefault_statistics_target =1000random_page_cost =60effective_cache_size =32GB
Parallellism aktiverad
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =16max_parallel_maintenance_workers =16max_worker_processes =32max_parallel_workers =32# optimizerdefault_statistics_target =1000random_page_cost =60effective_cache_size =32GB