Som vi nyligen meddelade har ClusterControl 1.7.4 en ny funktion som heter Cluster-to-Cluster Replication. Det låter dig ha en replikering som körs mellan två autonoma kluster. För mer detaljerad information, se ovan nämnda meddelande.
Vi kommer att ta en titt på hur man använder den här nya funktionen för ett befintligt PostgreSQL-kluster. För den här uppgiften antar vi att du har ClusterControl installerat och att Master Cluster har distribuerats med det.
Krav för Master Cluster
Det finns några krav för att Master Cluster ska få det att fungera:
- PostgreSQL 9.6 eller senare.
- Det måste finnas en PostgreSQL-server med ClusterControl-rollen 'Master'.
- När du konfigurerar slavklustret måste administratörsuppgifterna vara identiska med masterklustret.
Förbereder masterklustret
Masterklustret måste uppfylla kraven ovan.
Angående det första kravet, se till att du använder rätt PostgreSQL-version i Master Cluster och valde samma för Slav Cluster.
$ psql
postgres=# select version();
PostgreSQL 11.5 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bitOm du behöver tilldela huvudrollen till en specifik nod kan du göra det från ClusterControl UI. Gå till ClusterControl -> Välj Master Cluster -> Noder -> Välj Node -> Nod Actions -> Promote Slave.
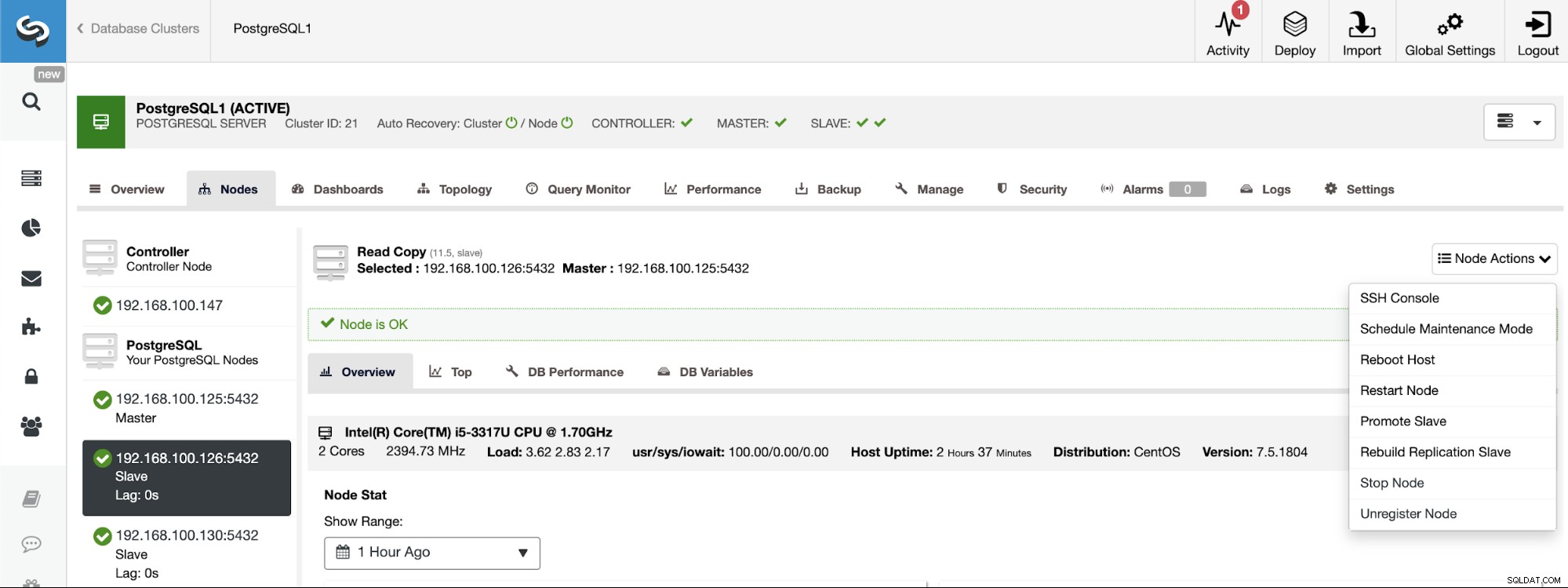
Och slutligen, under skapandet av slavklustret, måste du använda samma admin autentiseringsuppgifter som du för närvarande använder i huvudklustret. Du kommer att se var du kan lägga till det i följande avsnitt.
Skapa slavklustret från ClusterControl-gränssnittet
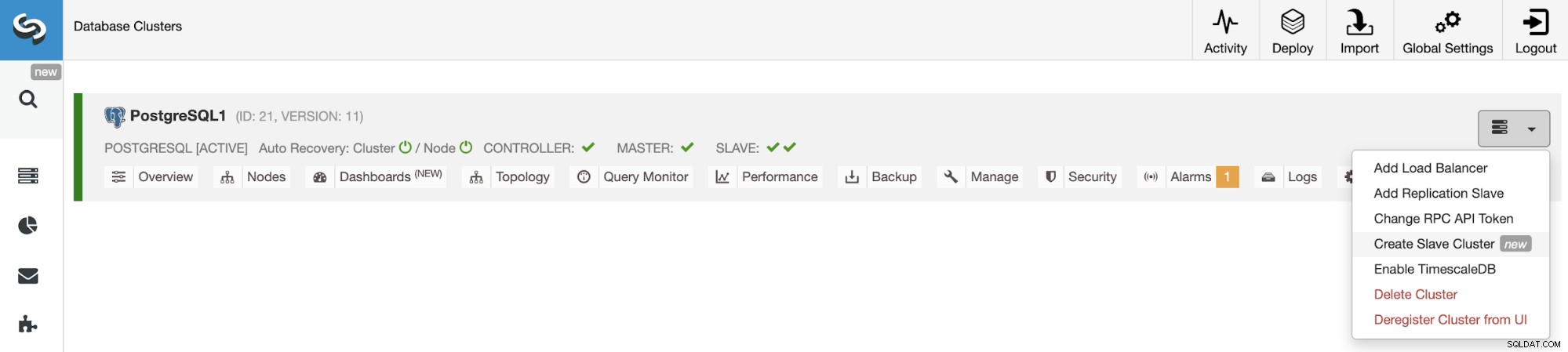
För att skapa ett nytt slavkluster, gå till ClusterControl -> Välj kluster -> Cluster Actions -> Create slavcluster.
Slavklustret kommer att skapas genom att strömma data från det aktuella huvudklustret.
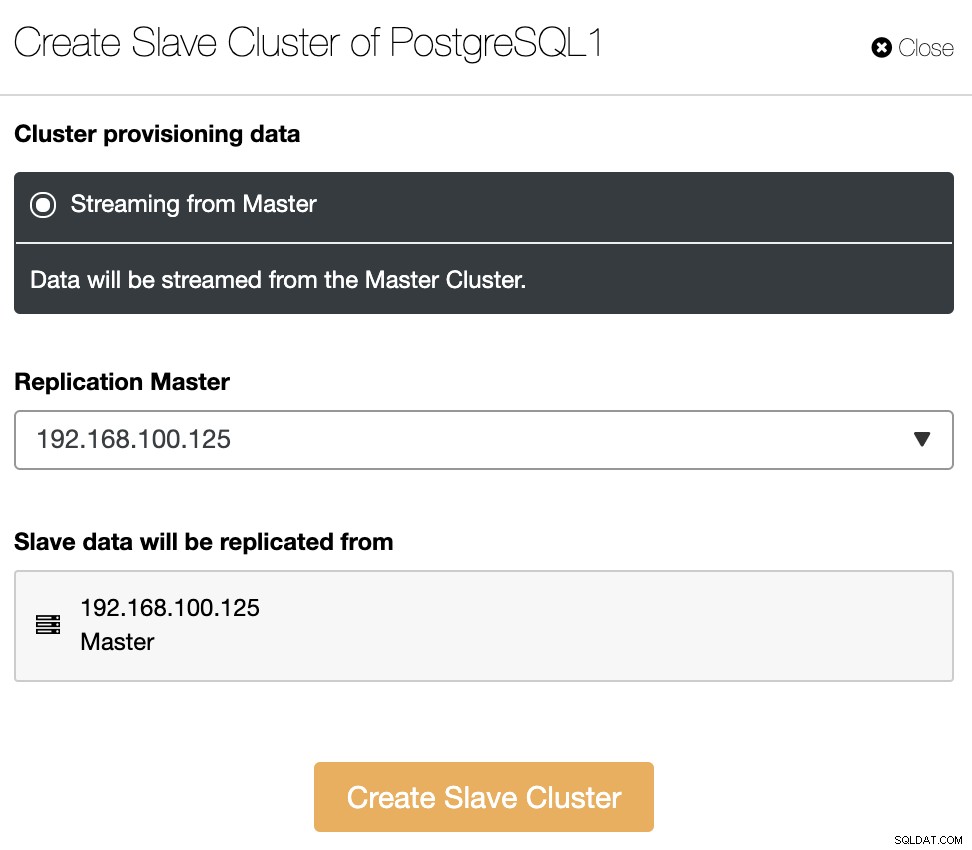
I det här avsnittet måste du också välja huvudnoden för det aktuella klustret från vilken data kommer att replikeras.
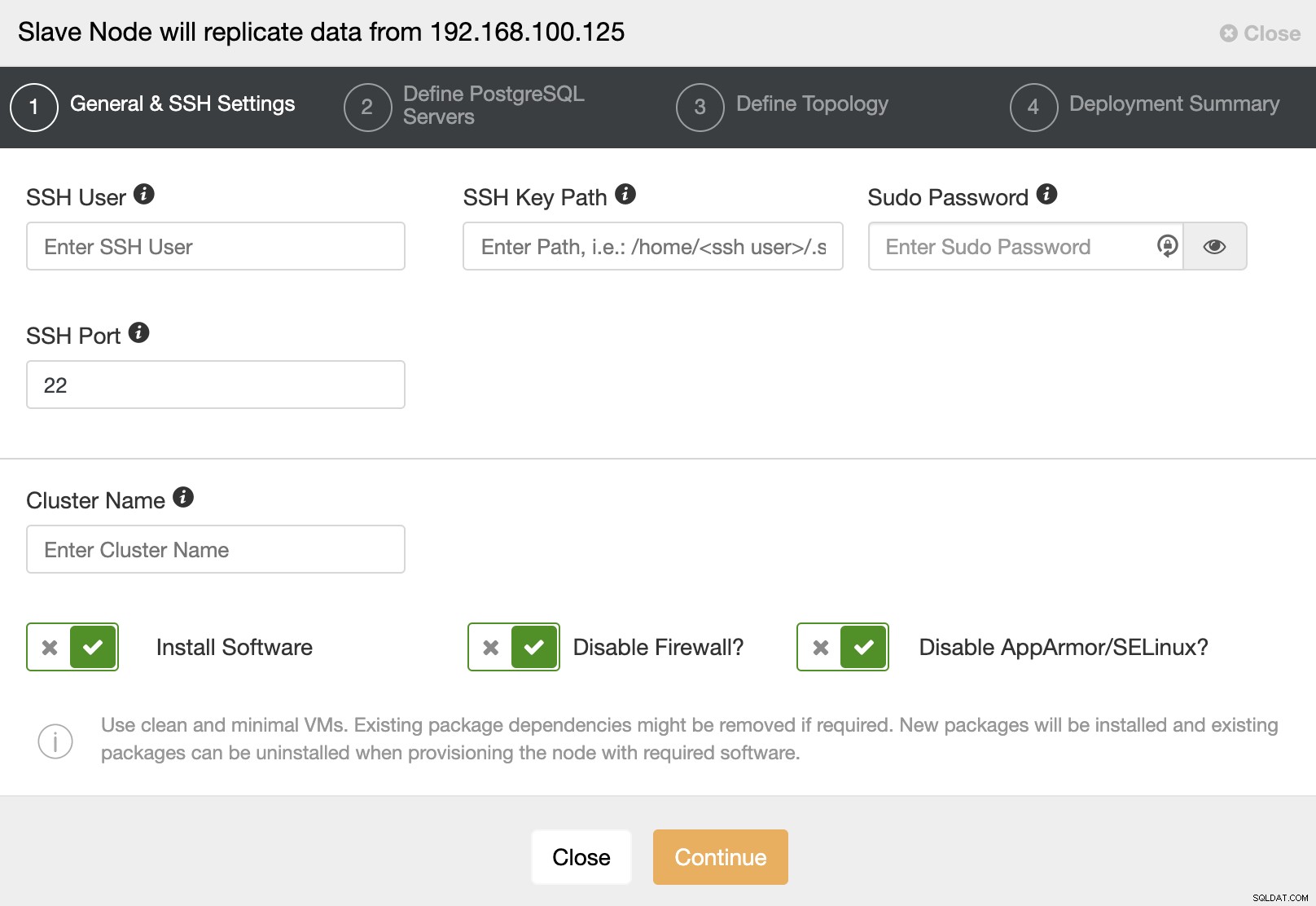
När du går till nästa steg måste du ange Användare, Nyckel eller Lösenord och port för att ansluta med SSH till dina servrar. Du behöver också ett namn för ditt slavkluster och om du vill att ClusterControl ska installera motsvarande programvara och konfigurationer åt dig.
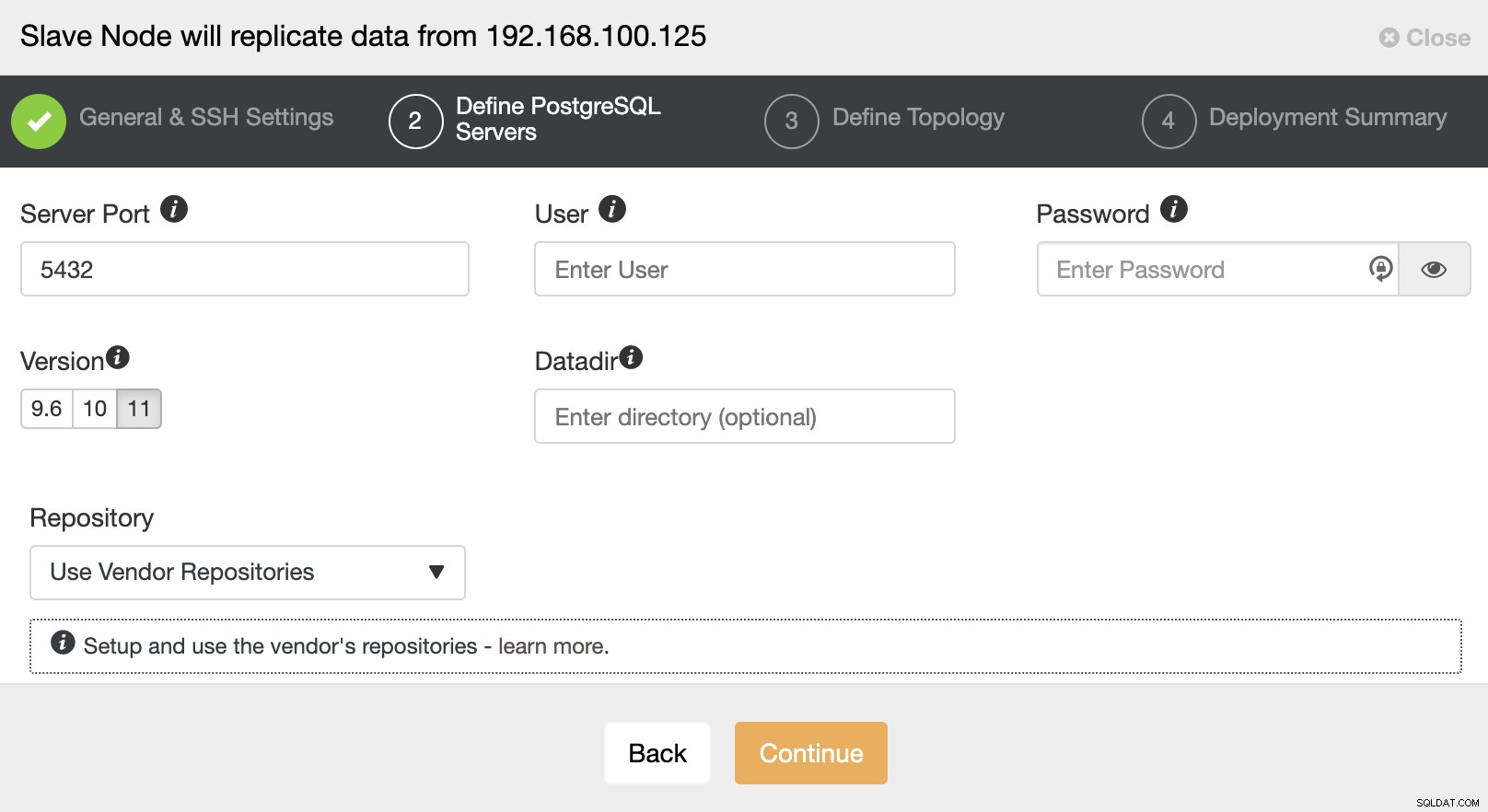
När du har ställt in SSH-åtkomstinformationen måste du definiera databasversionen, datadir, port och administratörsuppgifter. Eftersom det kommer att använda strömmande replikering, se till att du använder samma databasversion, och som vi nämnde tidigare måste referenserna vara desamma som används av Master Cluster. Du kan också ange vilket arkiv som ska användas.
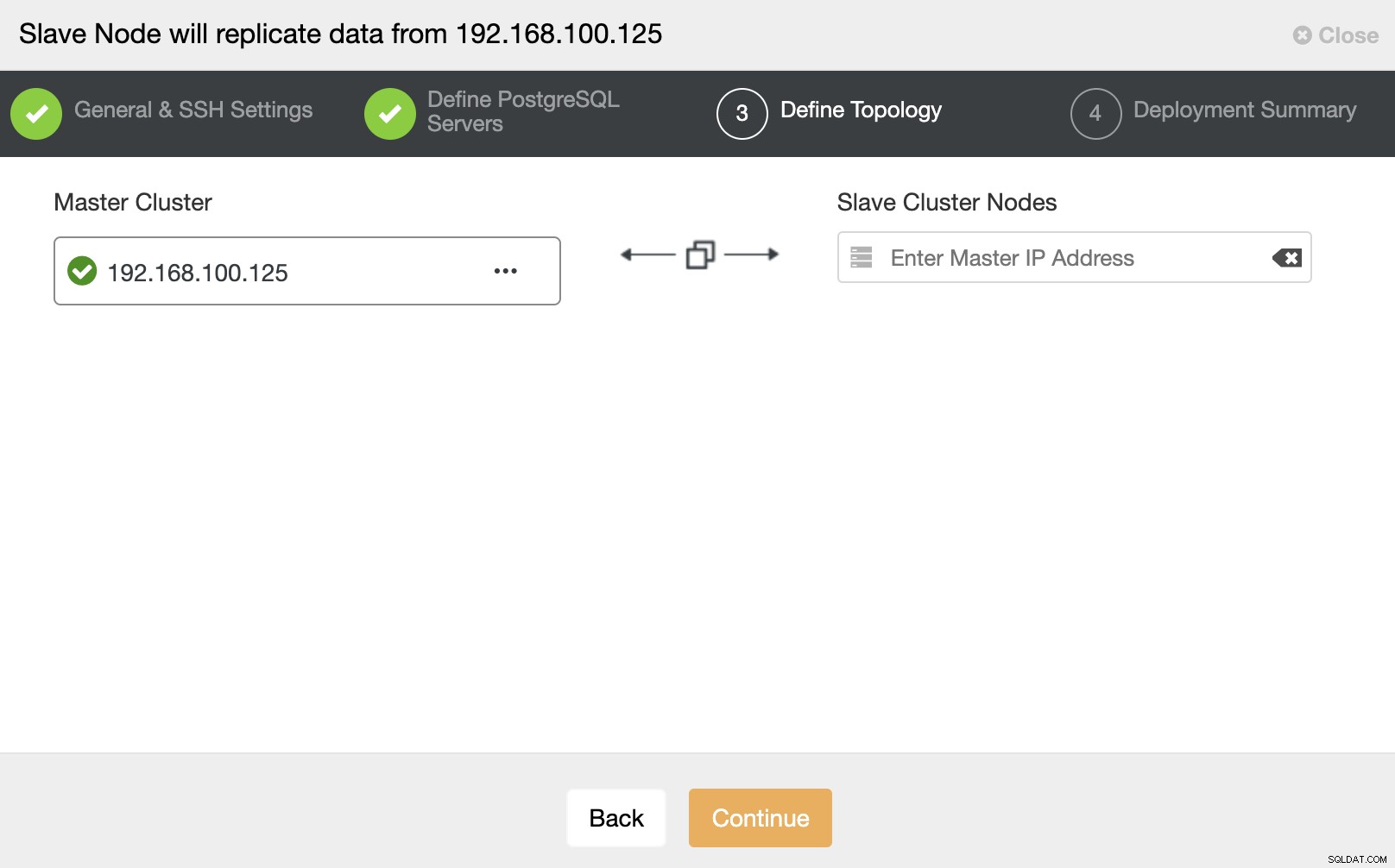
I det här steget måste du lägga till servern i det nya slavklustret . För den här uppgiften kan du ange både IP-adress eller värdnamn för databasnoden.
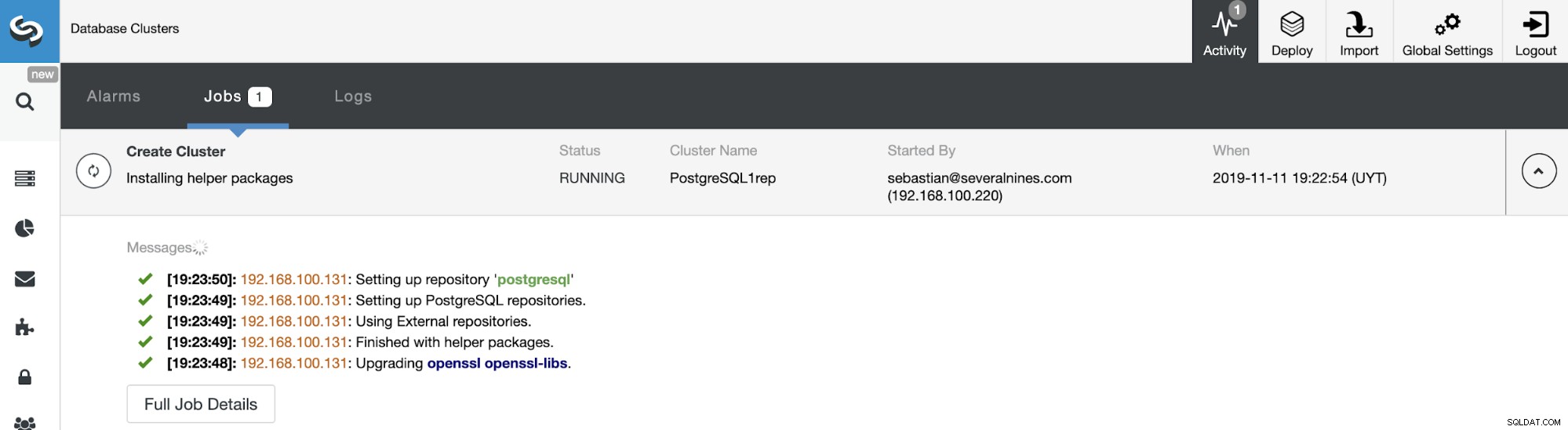
Du kan övervaka statusen för skapandet av ditt nya slavkluster från ClusterControl aktivitetsmonitor. När uppgiften är klar kan du se klustret på huvudskärmen för ClusterControl.
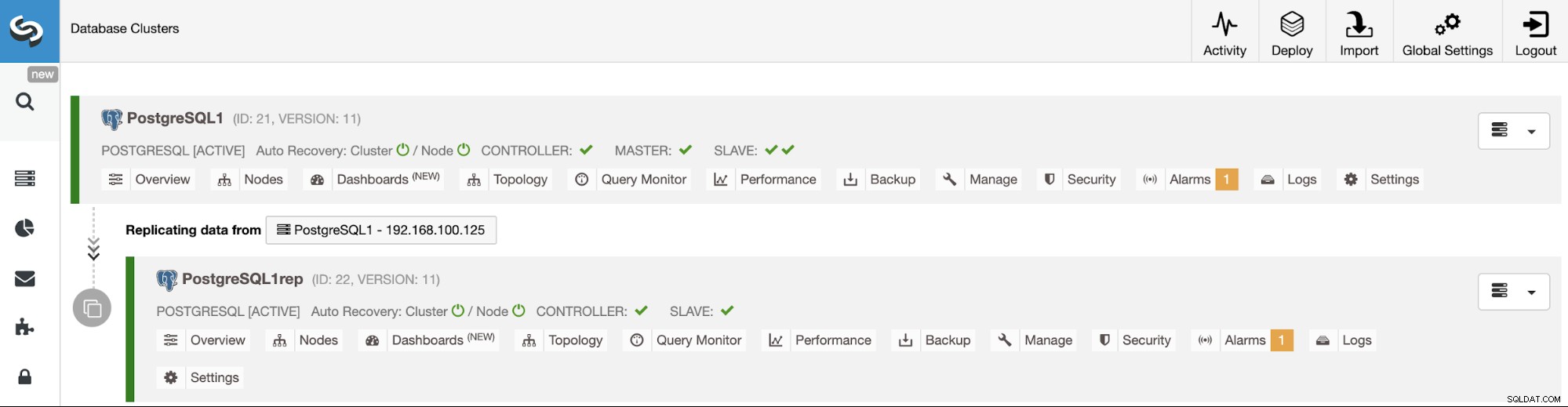
Hantera kluster-till-kluster-replikering med ClusterControl-gränssnittet
Nu har du din Cluster-to-Cluster-replikering igång, det finns olika åtgärder att utföra på denna topologi med ClusterControl.
Återbygga ett slavkluster
För att bygga om ett slavkluster, gå till ClusterControl -> Välj slavkluster -> Noder -> Välj den nod som är ansluten till masterklustret -> Nodåtgärder -> Bygg om replikeringsslav.
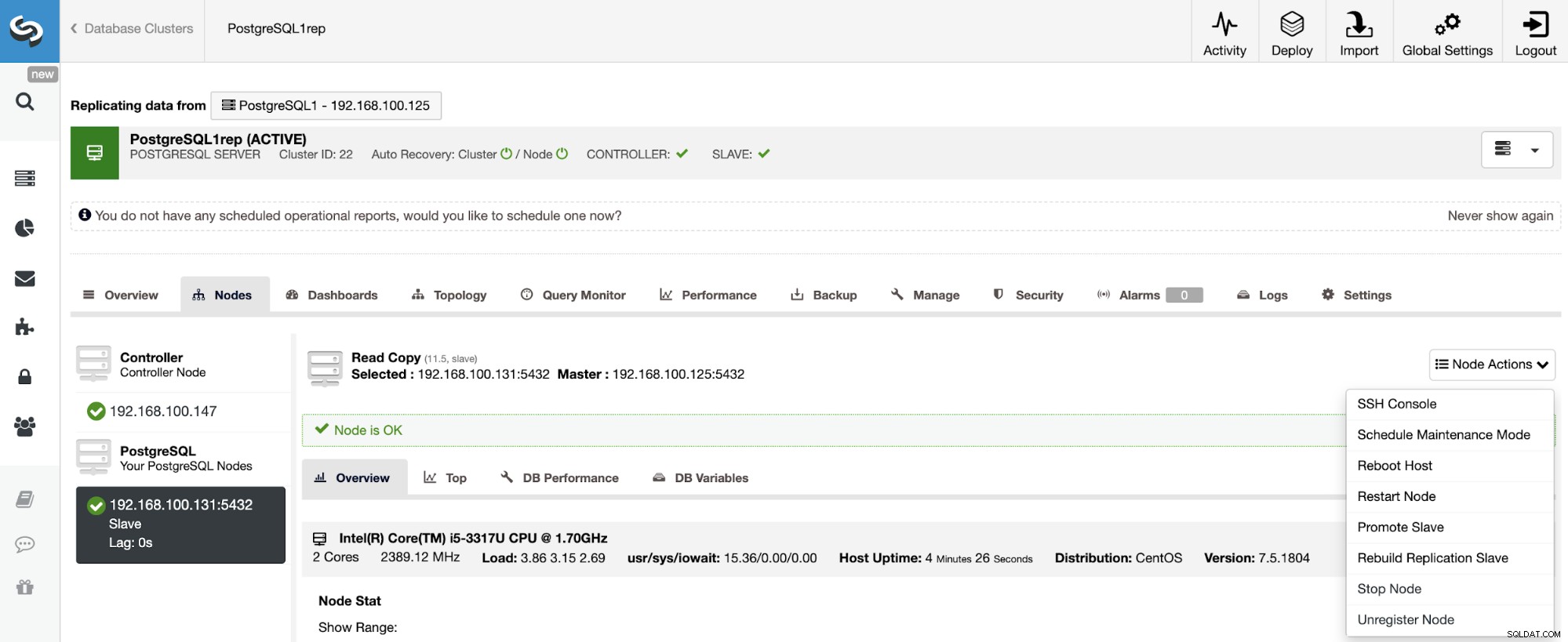
ClusterControl kommer att utföra följande steg:
- Stoppa PostgreSQL Server
- Ta bort innehåll från dess datakatalog
- Strömma en säkerhetskopia från mastern till slaven med pg_basebackup
- Starta slaven
Stoppa/starta replikeringsslav
Stoppa och starta replikeringen i PostgreSQL betyder pausa och återuppta den, men vi använder dessa termer för att överensstämma med andra databastekniker som vi stöder.
Denna funktion kommer snart att vara tillgänglig att använda från ClusterControl UI. Denna åtgärd kommer att använda funktionerna pg_wal_replay_pause och pg_wal_replay_resume PostgreSQL för att utföra denna uppgift.
Under tiden kan du använda en lösning för att stoppa och starta replikeringsslaven genom att stoppa och starta databasnoden på ett enkelt sätt med ClusterControl.
Gå till ClusterControl -> Välj slavkluster -> Noder -> Välj Nod -> Nodåtgärder -> Stoppa nod/startnod. Denna åtgärd kommer att stoppa/starta databastjänsten direkt.
Hantera kluster-till-kluster-replikering med ClusterControl CLI
I föregående avsnitt kunde du se hur du hanterar en kluster-till-kluster-replikering med ClusterControl-gränssnittet. Låt oss nu se hur man gör det genom att använda kommandoraden.
Obs:Som vi nämnde i början av den här bloggen, antar vi att du har ClusterControl installerat och att Master Cluster har distribuerats med det.
Skapa slavklustret
Låt oss först se ett exempel på kommando för att skapa ett slavkluster genom att använda ClusterControl CLI:
$ s9s cluster --create --cluster-name=PostgreSQL1rep --cluster-type=postgresql --provider-version=11 --nodes="192.168.100.133" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=admin --db-admin-passwd=********* --vendor=postgres --remote-cluster-id=21 --logNu har du din skapa-slavprocess igång, låt oss se varje använd parameter:
- Kluster:För att lista och manipulera kluster.
- Skapa:Skapa och installera ett nytt kluster.
- Klusternamn:Namnet på det nya slavklustret.
- Klustertyp:Typen av kluster som ska installeras.
- Provider-version:Programvaruversionen.
- Noder:Lista över de nya noderna i slavklustret.
- Os-user:Användarnamnet för SSH-kommandon.
- Os-key-file:Nyckelfilen som ska användas för SSH-anslutning.
- Db-admin:Databasadministratörens användarnamn.
- Db-admin-passwd:Lösenordet för databasadministratören.
- Remote-cluster-id:Master Cluster ID för kluster-till-kluster-replikeringen.
- Logg:Vänta och övervaka jobbmeddelanden.
Med flaggan --log kommer du att kunna se loggarna i realtid:
Verifying job parameters.
192.168.100.133: Checking ssh/sudo.
192.168.100.133: Checking if host already exists in another cluster.
Checking job arguments.
Found top level master node: 192.168.100.133
Verifying nodes.
Checking nodes that those aren't in another cluster.
Checking SSH connectivity and sudo.
192.168.100.133: Checking ssh/sudo.
Checking OS system tools.
Installing software.
Detected centos (core 7.5.1804).
Data directory was not specified. Using directory '/var/lib/pgsql/11/data'.
192.168.100.133:5432: Configuring host and installing packages if neccessary.
...
Cluster 26 is running.
Generated & set RPC authentication token.Återbygga ett slavkluster
Du kan bygga om ett slavkluster med följande kommando:
$ s9s replication --stage --master="192.168.100.125" --slave="192.168.100.133" --cluster-id=26 --remote-cluster-id=21 --logPametrarna är:
- Replikering:För att övervaka och kontrollera datareplikering.
- Stage:Stage/bygga om en replikeringsslav.
- Master:Replikeringsmastern i masterklustret.
- Slav:Replikeringsslaven i slavklustret.
- Kluster-id:Slavkluster-ID.
- Remote-cluster-id:Master Cluster ID.
- Logg:Vänta och övervaka jobbmeddelanden.
Jobbloggen bör vara liknande den här:
Rebuild replication slave 192.168.100.133:5432 from master 192.168.100.125:5432.
Remote cluster id = 21
192.168.100.125: Checking size of '/var/lib/pgsql/11/data'.
192.168.100.125: /var/lib/pgsql/11/data size is 201.13 MiB.
192.168.100.133: Checking free space in '/var/lib/pgsql/11/data'.
192.168.100.133: /var/lib/pgsql/11/data has 28.78 GiB free space.
192.168.100.125:5432(master): Verifying PostgreSQL version.
192.168.100.125: Verifying the timescaledb-postgresql-11 installation.
192.168.100.125: Package timescaledb-postgresql-11 is not installed.
Setting up replication 192.168.100.125:5432->192.168.100.133:5432
Collecting server variables.
192.168.100.125:5432: Using the pg_hba.conf contents for the slave.
192.168.100.125:5432: Will copy the postmaster.opts to the slave.
192.168.100.133:5432: Updating slave configuration.
Writing file '192.168.100.133:/var/lib/pgsql/11/data/postgresql.conf'.
192.168.100.133:5432: GRANT new node on members to do pg_basebackup.
192.168.100.125:5432: granting 192.168.100.133:5432.
192.168.100.133:5432: Stopping slave.
192.168.100.133:5432: Stopping PostgreSQL node.
192.168.100.133: waiting for server to shut down.... done
server stopped
…
192.168.100.133: waiting for server to start....2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv4 address "0.0.0.0", port 5432
2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv6 address "::", port 5432
2019-11-12 15:51:11.769 UTC [8005] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2019-11-12 15:51:11.774 UTC [8005] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2019-11-12 15:51:11.798 UTC [8005] LOG: redirecting log output to logging collector process
2019-11-12 15:51:11.798 UTC [8005] HINT: Future log output will appear in directory "log".
done
server started
192.168.100.133:5432: Grant cluster members on the new node (for failover).
Grant connect access for new host in cluster.
Adding grant on 192.168.100.125:5432.
192.168.100.133:5432: Waiting until the service is started.
Replication slave job finished.Stoppa/starta replikeringsslav
Som vi nämnde i UI-avsnittet betyder stopp och start-replikering i PostgreSQL pausa och återuppta den, men vi använder dessa termer för att behålla parallelliteten med andra teknologier.
Du kan sluta replikera data från Master Cluster på detta sätt:
$ s9s replication --stop --slave="192.168.100.133" --cluster-id=26 --logDu kommer att se detta:
192.168.100.133:5432: Pausing recovery of the slave.
192.168.100.133:5432: Successfully paused recovery on the slave using select pg_wal_replay_pause().Och nu kan du starta det igen:
$ s9s replication --start --slave="192.168.100.133" --cluster-id=26 --logDu kommer alltså att se:
192.168.100.133:5432: Resuming recovery on the slave.
192.168.100.133:5432: Collecting replication statistics.
192.168.100.133:5432: Slave resumed recovery successfully using select pg_wal_replay_resume().Låt oss nu kontrollera de använda parametrarna.
- Replikering:För att övervaka och kontrollera datareplikering.
- Stopp/Start:För att få slaven att sluta/börja replikera.
- Slav:Replikeringsslavnoden.
- Kluster-id:ID för klustret där slavnoden finns.
- Logg:Vänta och övervaka jobbmeddelanden.
Slutsats
Denna nya ClusterControl-funktion gör att du snabbt kan ställa in replikering mellan olika PostgreSQL-kluster och hantera installationen på ett enkelt och vänligt sätt. Severalnines utvecklarteam arbetar med att förbättra den här funktionen, så alla idéer eller förslag skulle vara mycket välkomna.