Moderna appar som mikrotjänster kräver vanligtvis många databasanslutningar, de använder och släpper också dessa anslutningar mycket snabbt. När PostgreSQL utvecklades för nästan 25 år sedan beslutade dess utvecklare att inte använda trådar för nya förfrågningar, utan att skapa en ny process för varje förfrågan istället. Även om det beslutet förmodligen var vettigt då, kan många kopplingar vara ett allvarligt problem idag. En av lösningarna för detta problem är en anslutningspool. I det här blogginlägget kommer vi att diskutera PgBouncer Connection Pool och hur man använder den i ClusterControl 1.8.2.
Varför använda Connection Pool
Tja, det korta svaret på denna fråga är att det är en enkel men effektiv lösning för att förbättra prestandan för dina appar, samtidigt som den minskar belastningen på PostgreSQL-servern. Låt oss gå lite djupare på det här, eller hur?
En anslutningspool kan definieras som en cache med öppna databasanslutningar som kan återanvändas av klienterna. Med andra ord kommer det att minska belastningen på databasen genom att minska förfrågningarna på varje ny anslutning. Dessa nya anslutningar skapas i princip av postmaster-processen varje gång en anslutning upprättas, vilket vanligtvis tar cirka 2 till 3 MB minne per anslutning.
Utan en anslutningspool kommer detta att leda till problem när antalet anslutningar är för högt eftersom postmastern behöver tillhandahålla mycket minne. I PostgreSQL hanteras anslutningspoolen av PgBouncer.
Vad är PgBouncer
PgBouncer är en lätt, enkelbinär, öppen källkod och förmodligen den mest populära anslutningspoolaren för PostgreSQL. PgBouncer är ett enkelt verktyg som gör exakt en sak, det sitter mellan databasen och klienterna och pratar PostgreSQL-protokollet och kopierar en PostgreSQL-server. I skrivande stund är den senaste versionen av PgBouncer 1.15.0.
Låt oss se vilka är några av de bästa funktionerna som den erbjuder, och förmodligen anledningen till att den är så populär i PostgreSQL-världen:
-
Lättvikt - endast en enda process, alla förfrågningar från klienten och svar från servern passerar PgBouncer utan ytterligare bearbetning
-
Enkel installation – kräver inga kodändringar på klientsidan och en av de enklaste PostgreSQL-anslutningspoolarna att konfigurera P>
-
Skalbarhet och prestanda – den skalas väl till ett stort antal kunder och ökar samtidigt transaktionerna avsevärt per sekund som PostgreSQL-servern kan stödja
Steg för att ställa in PgBouncer med ClusterControl
Det finns några steg för att du ska kunna installera och konfigurera PgBouncer med ClusterControl. I det här avsnittet kommer vi att gå igenom stegen förutsatt att du redan har PostgreSQL-klustret distribuerat. Om du inte har klustret ännu kan du följa guiden i det här blogginlägget.
Från ditt webbgränssnitt> Välj PostgreSQL-kluster> Hantera> Load Balancer> fliken Välj PgBouncer och följande skärmdump visas. Här kan du välja om du vill distribuera eller importera PgBouncer, i det här exemplet väljer vi Deploy.:
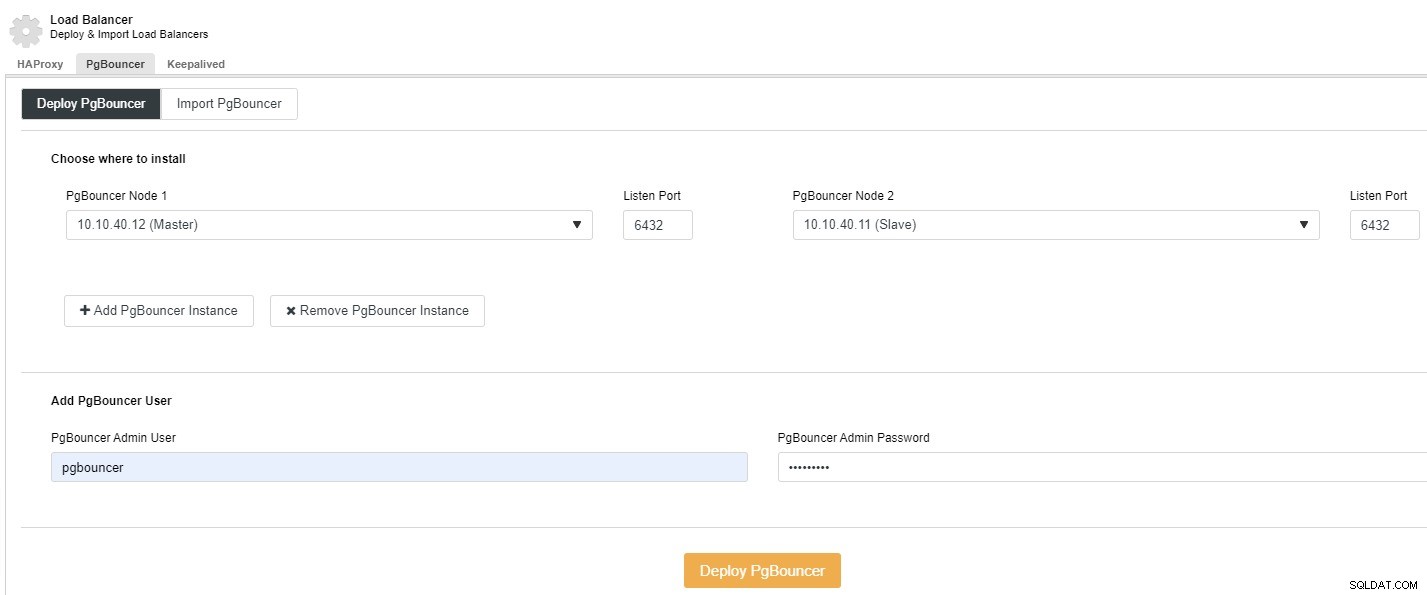
Du kan välja noden från rullgardinsmenyn, ange porten, lägga till ' PgBouncer Admin User' samt lösenordet och klicka på 'Deploy PgBouncer'. Jobbet kommer att börja köras och statusen börjar visas på den här skärmen, du kan också övervaka det på fliken "Aktivitet".
När PgBouncer-noden har distribuerats framgångsrikt är nästa steg att skapa anslutningspoolen. Från ditt kluster> Noder> Välj PgBouncer-nod och följande skärmdump visas:
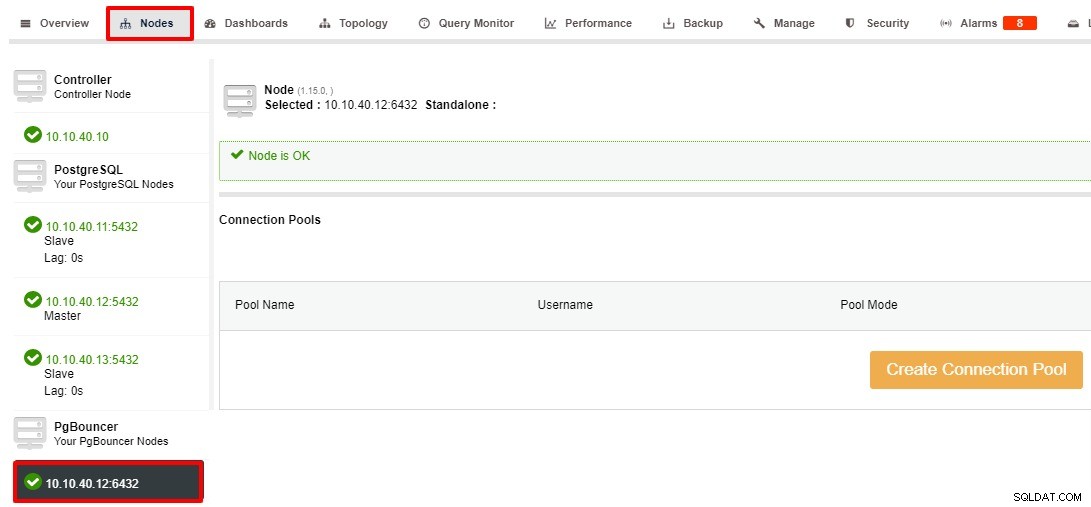
Anslutningsskärmen visas när du klickar på "Skapa anslutningspool" knapp. Du kan fylla i all information och uppdatera värdet beroende på din inställning, för det här exemplet kommer vi att använda standardvärdet för "Pool Mode", "Pool Size" och "Max Databas Connection":
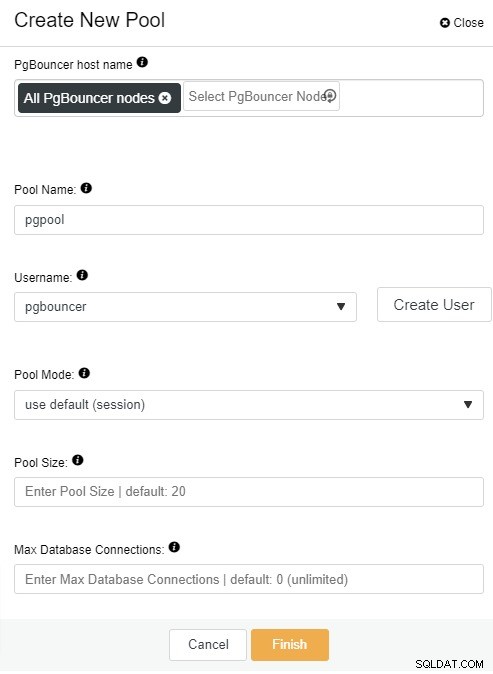
Här måste du lägga till följande information:
-
PgBouncer-värdnamn:Välj nodvärdarna för att skapa anslutningspoolen.
-
Poolnamn:Pool- och databasnamn måste vara desamma.
-
Användarnamn: Välj en användare från PostgreSQL-masternoden eller skapa en ny.
-
Poolläge:session (standard), transaktions- eller utdragspoolning.
-
session (standard):Servern släpps tillbaka till poolen efter att klienten kopplat från
-
transaktion:Servern släpps tillbaka till poolen efter att transaktionen är klar
-
påstående:Servern släpps tillbaka till poolen efter att frågan är klar. Transaktioner som spänner över flera uttalanden är inte tillåtna i det här läget
-
-
Poolstorlek:Maximal storlek på pooler för denna databas. Standardvärdet är 20.
-
Max databasanslutningar:Konfigurera ett databasomfattande maximum. Standardvärdet är 0, vilket betyder obegränsat.
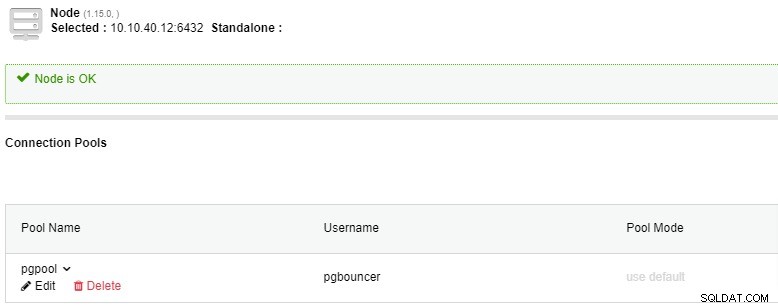
Anslutningspoolen kommer att visas efter att du klickat på "Slutför"-knappen enligt skärmdumpen nedan och både PgBouncer och anslutningspoolen är nu klara:
Slutsats
Användning av anslutningspool och PgBouncer är några av stegen för att förbättra prestandan för din applikation när det kommer till hög tillgänglighet. Med ClusterControl kan du distribuera PgBouncer samt skapa en anslutningspool enkelt och snabbt.
För att göra det ännu bättre föreslår vi också att du distribuerar HAProxy utöver PgBouncer. HAProxy-funktionen är tillgänglig i ClusterControl och i skrivande stund är versionen som vi använder 1.8.23.