Att använda replikering för dina PostgreSQL-databaser kan vara användbart inte bara för att ha en hög tillgänglighet och feltolerant miljö utan också för att förbättra prestandan på ditt system genom att balansera trafiken mellan standbynoderna. I den här första delen av den tvådelade bloggen kommer vi att se några koncept relaterade till PostgreSQL-replikeringen.
Replikeringsmetoder i PostgreSQL
Det finns olika metoder för att replikera data i PostgreSQL, men här kommer vi att fokusera på de två huvudmetoderna:Strömmande replikering och logisk replikering.
Streamande replikering
PostgreSQL Streaming Replication, den vanligaste PostgreSQL-replikeringen, är en fysisk replikering som replikerar ändringarna på en byte-för-byte-nivå och skapar en identisk kopia av databasen på en annan server. Den är baserad på logfraktmetoden. WAL-posterna flyttas direkt från en databasserver till en annan för att tillämpas. Vi kan säga att det är ett slags kontinuerlig PITR.
Denna WAL-överföring utförs på två olika sätt, genom att överföra WAL-poster en fil (WAL-segment) åt gången (filbaserad loggsändning) och genom att överföra WAL-poster (en WAL-fil består av WAL-poster) i farten (rekordbaserad loggsändning), mellan en primär server och en eller flera än på standby-servrar, utan att vänta på att WAL-filen ska fyllas i.
I praktiken kommer en process som kallas WAL-mottagare, som körs på standby-servern, att ansluta till den primära servern med en TCP/IP-anslutning. På den primära servern finns en annan process, som heter WAL-avsändaren, och som ansvarar för att skicka WAL-registren till standbyservern när de händer.
En grundläggande strömmande replikering kan representeras enligt följande:
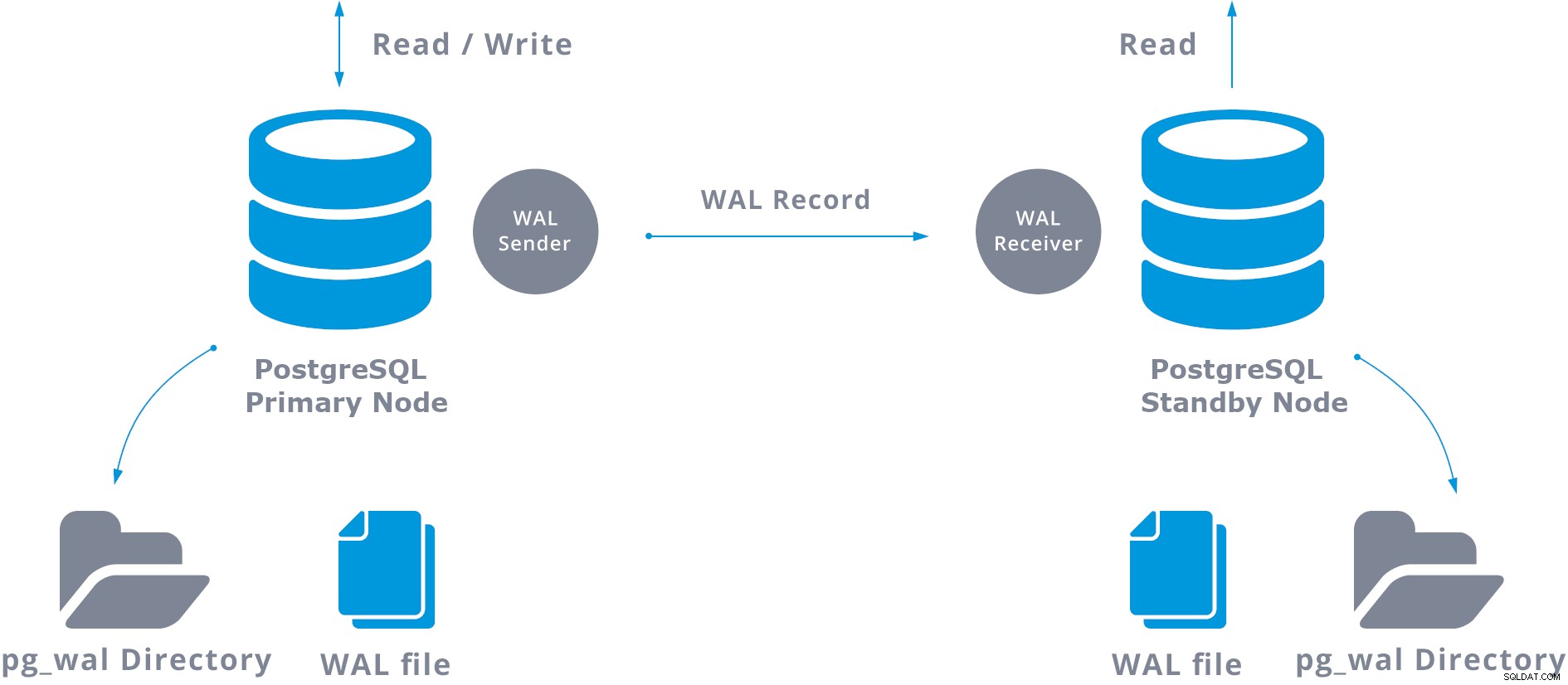
När du konfigurerar strömmande replikering har du möjlighet att aktivera WAL-arkivering. Detta är inte obligatoriskt, men är extremt viktigt för robust replikeringsinställning, eftersom det är nödvändigt att undvika att huvudservern återvinner gamla WAL-filer som ännu inte har applicerats på standbyservern. Om detta inträffar måste du återskapa repliken från början.
Logisk replikering
PostgreSQL logisk replikering är en metod för att replikera dataobjekt och deras ändringar, baserat på deras replikeringsidentitet (vanligtvis en primärnyckel). Den är baserad på ett publicerings- och prenumerationsläge, där en eller flera prenumeranter prenumererar på en eller flera publikationer på en förlagsnod.
En publikation är en uppsättning ändringar som genereras från en tabell eller en grupp av tabeller. Noden där en publikation definieras kallas utgivare. Ett abonnemang är nedströmssidan av logisk replikering. Noden där en prenumeration definieras kallas abonnenten, och den definierar kopplingen till en annan databas och uppsättning publikationer (en eller flera) som den vill prenumerera på. Prenumeranter hämtar data från de publikationer de prenumererar på.
Logisk replikering är byggd med en arkitektur som liknar fysisk strömmande replikering. Det implementeras av "walsender" och "apply" processer. Walsender-processen startar logisk avkodning av WAL och laddar standardinsticksprogrammet för logisk avkodning. Insticksprogrammet omvandlar ändringarna som läses från WAL till det logiska replikeringsprotokollet och filtrerar data enligt publikationsspecifikationen. Data överförs sedan kontinuerligt med hjälp av strömmande replikeringsprotokoll till appliceringsarbetaren, som mappar data till lokala tabeller och tillämpar de individuella ändringarna allt eftersom de tas emot, i en korrekt transaktionsordning.
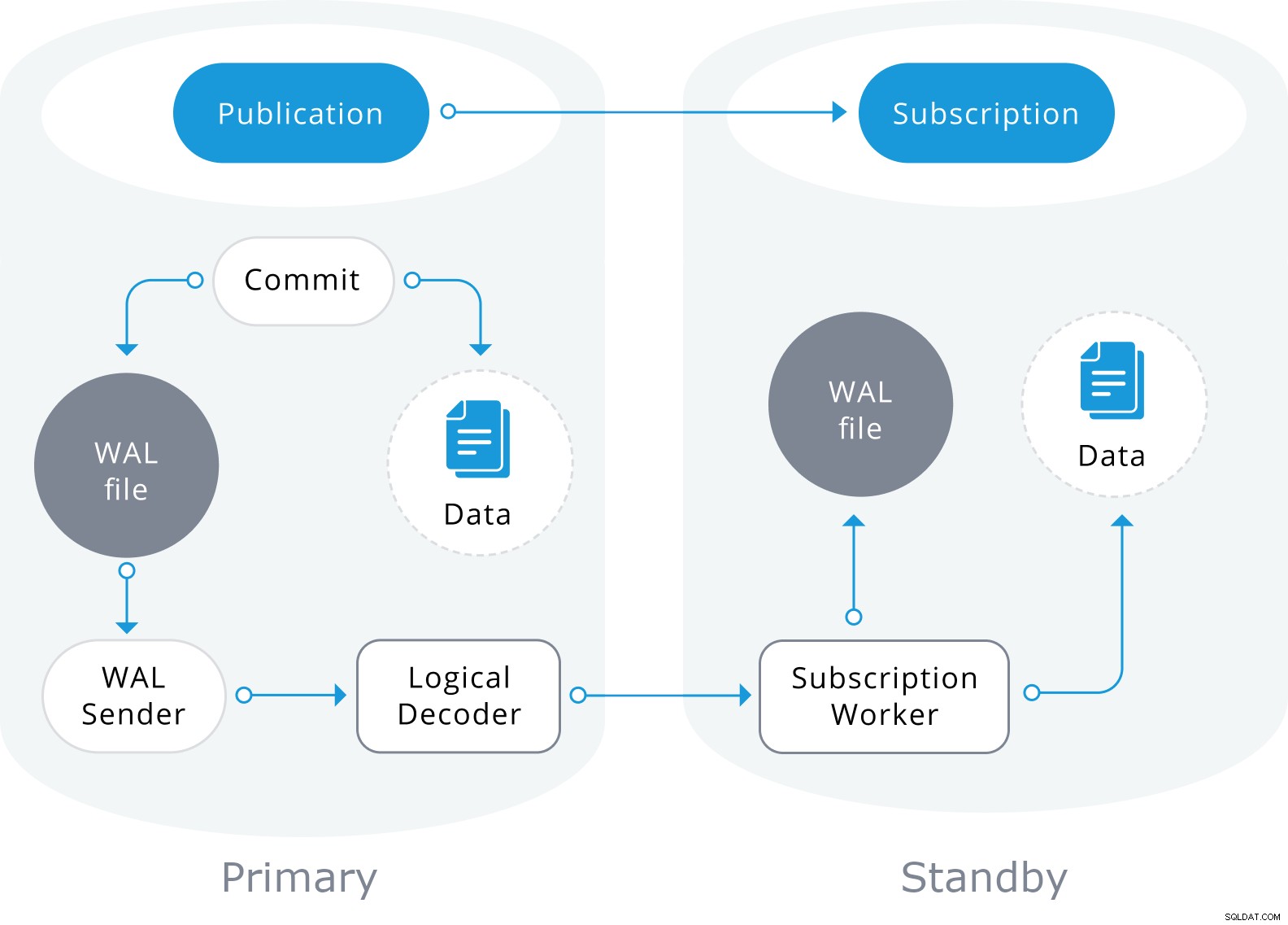
Logisk replikering startar med att ta en ögonblicksbild av data i utgivardatabasen och kopiera det till abonnenten. De initiala uppgifterna i de befintliga prenumererade tabellerna är ögonblicksbilder och kopieras i en parallell instans av en speciell typ av appliceringsprocess. Denna process kommer att skapa sin egen temporära replikeringsplats och kopiera befintliga data. När befintlig data har kopierats går arbetaren in i synkroniseringsläge, vilket säkerställer att tabellen förs upp till ett synkroniserat tillstånd med den huvudsakliga appliceringsprocessen genom att strömma alla ändringar som hände under den första datakopieringen med hjälp av standard logisk replikering. När synkroniseringen är gjord, återförs kontrollen av replikeringen av tabellen till huvudappliceringsprocessen där replikeringen fortsätter som vanligt. Ändringarna på utgivaren skickas till prenumeranten när de sker i realtid.
replikeringslägen i PostgreSQL
Replikeringen i PostgreSQL kan vara synkron eller asynkron.
Asynkron replikering
Det är standardläget. Här är det möjligt att ha några transaktioner begångna i den primära noden som ännu inte har replikerats till standby-servern. Detta innebär att det finns risk för viss potentiell dataförlust. Denna fördröjning i commit-processen är tänkt att vara mycket liten om standby-servern är tillräckligt kraftfull för att hålla jämna steg med belastningen. Om denna lilla risk för dataförlust inte är acceptabel i företaget kan du använda synkron replikering istället.
Synkron replikering
Varje commit av en skrivtransaktion kommer att vänta tills bekräftelsen att commit har skrivits till skriv-förut-loggningsdisken på både den primära och standby-servern. Denna metod minimerar risken för dataförlust. För att dataförlust ska uppstå måste både den primära och vänteläget misslyckas samtidigt.
Nackdelen med den här metoden är densamma för alla synkrona metoder som med denna metod ökar svarstiden för varje skrivtransaktion. Detta beror på behovet av att vänta tills alla bekräftelser på att transaktionen genomfördes. Lyckligtvis kommer skrivskyddade transaktioner inte att påverkas av detta men; endast skrivtransaktionerna.
Hög tillgänglighet för PostgreSQL-replikering
Hög tillgänglighet är ett krav för många system, oavsett vilken teknik vi använder, och det finns olika tillvägagångssätt för att uppnå detta med olika verktyg.
Lastbalansering
Lastbalanserare är verktyg som kan användas för att hantera trafiken från din applikation för att få ut det mesta av din databasarkitektur. Det är inte bara användbart för att balansera belastningen på våra databaser, det hjälper också applikationer att omdirigeras till tillgängliga/friska noder och till och med specificera portar med olika roller.
HAProxy är en lastbalanserare som distribuerar trafik från ett ursprung till en eller flera destinationer och kan definiera specifika regler och/eller protokoll för denna uppgift. Om någon av destinationerna slutar svara markeras den som offline och trafiken skickas till resten av de tillgängliga destinationerna. Om du bara har en Load Balancer-nod genereras en Single Point of Failure, så för att undvika detta bör du distribuera minst två HAProxy-noder och konfigurera Keepalved mellan dem.
Keelived är en tjänst som låter oss konfigurera en virtuell IP inom en aktiv/passiv grupp av servrar. Denna virtuella IP tilldelas en aktiv server. Om denna server misslyckas migreras IP:n automatiskt till den "sekundära" passiva servern, vilket gör att den kan fortsätta arbeta med samma IP på ett transparent sätt för systemen.
Förbättra prestanda på PostgreSQL-replikering
Prestandan är alltid viktig i alla system. Du kommer att behöva använda de tillgängliga resurserna väl för att säkerställa bästa möjliga svarstid och det finns olika sätt att göra detta. Varje anslutning till en databas förbrukar resurser så ett av sätten att förbättra prestandan på din PostgreSQL-databas är att ha en bra anslutningspooler mellan din applikation och databasservrarna.
Connection Poolers
En anslutningspoolning är en metod för att skapa en pool av anslutningar och återanvända dem, för att undvika att öppna nya anslutningar till databasen hela tiden, vilket kommer att öka prestandan för dina applikationer avsevärt. PgBouncer är en populär anslutningspoolare designad för PostgreSQL.
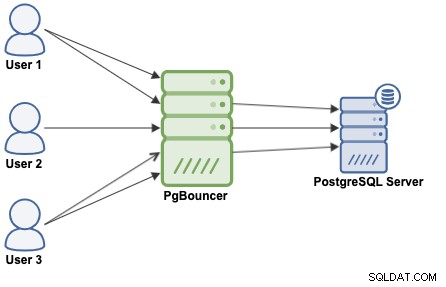
PgBouncer fungerar som en PostgreSQL-server, så du behöver bara komma åt din databas genom att använda PgBouncer-informationen (IP-adress/värdnamn och port), så skapar PgBouncer en anslutning till PostgreSQL-servern, eller så kommer den att återanvända en om den finns.
När PgBouncer tar emot en anslutning utför den autentiseringen, vilket beror på metoden som anges i konfigurationsfilen. PgBouncer stöder alla autentiseringsmekanismer som PostgreSQL-servern stöder. Efter detta söker PgBouncer efter en cachad anslutning, med samma användarnamn+databaskombination. Om en cachad anslutning hittas returnerar den anslutningen till klienten, om inte skapar den en ny anslutning. Beroende på PgBouncer-konfigurationen och antalet aktiva anslutningar kan det vara möjligt att den nya anslutningen står i kö tills den kan skapas eller till och med avbrytas.
Med alla dessa nämnda koncept, i den andra delen av denna blogg, kommer vi att se hur du kan kombinera dem för att få en bra replikeringsmiljö i PostgreSQL.