PostgreSQL, även känd som världens mest avancerade databas med öppen källkod, har en ny version sedan 24 september 2020, och nu är den mogen, vi kan kolla vad som är nytt där för att börja tänka på en migrationsplan. PostgreSQL 13 är tillgängligt med många nya funktioner och förbättringar. I den här bloggen kommer vi att nämna några av dessa nya funktioner och se hur du distribuerar eller uppgraderar din nuvarande PostgreSQL-version.
PostgreSQL 13 nya funktioner och förbättringar
Låt oss börja nämna några av de nya funktionerna och förbättringarna av denna PostgreSQL 13-version som du kan se i den officiella dokumentationen.
Partitionering
-
Tillåt beskärning av partitioner och partitionsmässiga sammanfogningar i fler fall
-
Stöd radnivå INNAN utlösare på partitionerade tabeller
-
Tillåt att partitionerade tabeller logiskt replikeras via publicering
-
Tillåt logisk replikering till partitionerade tabeller för prenumeranter
-
Tillåt helradsvariabler att användas i partitioneringsuttryck
Index
-
Lagra dubbletter mer effektivt i B-trädindex
-
Tillåt GiST- och SP-GiST-index på boxkolumner att stödja ORDER BY box <-> punktfrågor
-
Tillåt GIN-index att hanteras mer effektivt! (NOT) satser i tsquery-sökningar
-
Tillåt indexoperatorklasser att ta parametrar
Optimerare
-
Förbättra optimerarens selektivitetsuppskattning för inneslutnings-/matchningsoperatörer
-
Tillåt att ställa in statistikmålet för utökad statistik
-
Tillåt användning av flera utökade statistikobjekt i en enda fråga
-
Tillåt användning av utökade statistikobjekt för OR-satser och IN/NÅGON konstantlistor
-
Tillåt att funktioner i FROM-satser dras upp (infogas) om de evalueras till konstanter
Prestanda
-
Implementera inkrementell sortering och förbättra prestandan för sortering av inet-värden
-
Tillåt hashaggregation för att använda disklagring för stora aggregeringsresultatuppsättningar
-
Tillåt inlägg, inte bara uppdateringar och borttagningar, att utlösa dammsugning i autovakuum
-
Lägg till parametern maintenance_io_concurrency för att kontrollera I/O-samtidighet för underhållsoperationer
-
Tillåt att WAL-skrivningar hoppas över under en transaktion som skapar eller skriver om en relation, om wal_level är minimal
-
Förbättra prestandan när du spelar om DROP DATABASE-kommandon när många tabellutrymmen används
-
Gör snabbare omvandlingar av heltal till text
-
Minska minnesanvändningen för frågesträngar och tilläggsskript som innehåller många SQL-satser
Övervakning
-
Tillåt EXPLAIN, auto_explain, autovacuum och pg_stat_statements att spåra WAL-användningsstatistik
-
Tillåt att ett urval av SQL-satser, snarare än alla satser, loggas
-
Lägg till backend-typen i csvlog och eventuellt log_line_prefix-loggutdata
-
Förbättra kontrollen över förberedd satsparameterloggning
-
Lägg till leader_pid i pg_stat_activity för att rapportera en parallell arbetares ledarprocess
-
Lägg till systemvy pg_stat_progress_basebackup för att rapportera framstegen för strömmande bassäkerhetskopior
-
Lägg till systemvy pg_stat_progress_analyze för att rapportera ANALYSE framsteg
-
Lägg till systemvy pg_shmem_allocations för att visa användning av delat minne
replikering och återställning
-
Tillåt att konfigurationsinställningar för strömmande replikering ändras genom att ladda om
-
Tillåt WAL-mottagare att använda en temporär replikeringsplats när en permanent inte anges
-
Tillåt att WAL-lagring för replikeringsplatser begränsas av max_slot_wal_keep_size
-
Tillåt standby-kampanj att avbryta eventuella begärda pauser
-
Generera ett fel om återställningen inte når det angivna återställningsmålet
-
Tillåt kontroll över hur mycket minne som används genom logisk avkodning innan det spills till disk
-
Tillåt återställning att fortsätta även om ogiltiga sidor refereras av WAL
Verktygskommandon
-
Tillåt VACUUM att behandla en tabells index parallellt
-
Rapportera användning av buffert för planeringstid i EXPLAINs BUFFER-utgång
-
Få CREATE TABLE LIKE att sprida en CHECK-begränsnings NO INHERIT-egenskap till den skapade tabellen
-
Lägg till ALTER TABLE ... DROP EXPRESSION för att tillåta borttagning av egenskapen GENERATED från en kolumn
-
Lägg till ALTER VIEW-syntax för att byta namn på vykolumner
-
Lägg till alternativ för ALTER TYPE för att ändra en bastyps TOAST-egenskaper och stödfunktioner
-
Lägg till alternativet CREATE DATABASE LOCALE
-
Tillåt DROP DATABASE att koppla bort sessioner med hjälp av måldatabasen, så att släppningen lyckas
Och många fler ändringar. Vi nämnde bara några av dem för att undvika ett större blogginlägg. Nu ska vi se hur du distribuerar den här nya versionen.
Hur man distribuerar PostgreSQL 13
För detta antar vi att du har ClusterControl installerat, annars kan du följa motsvarande dokumentation för att installera det.
För att utföra en distribution från ClusterControl, välj helt enkelt alternativet Deploy och följ instruktionerna som visas.
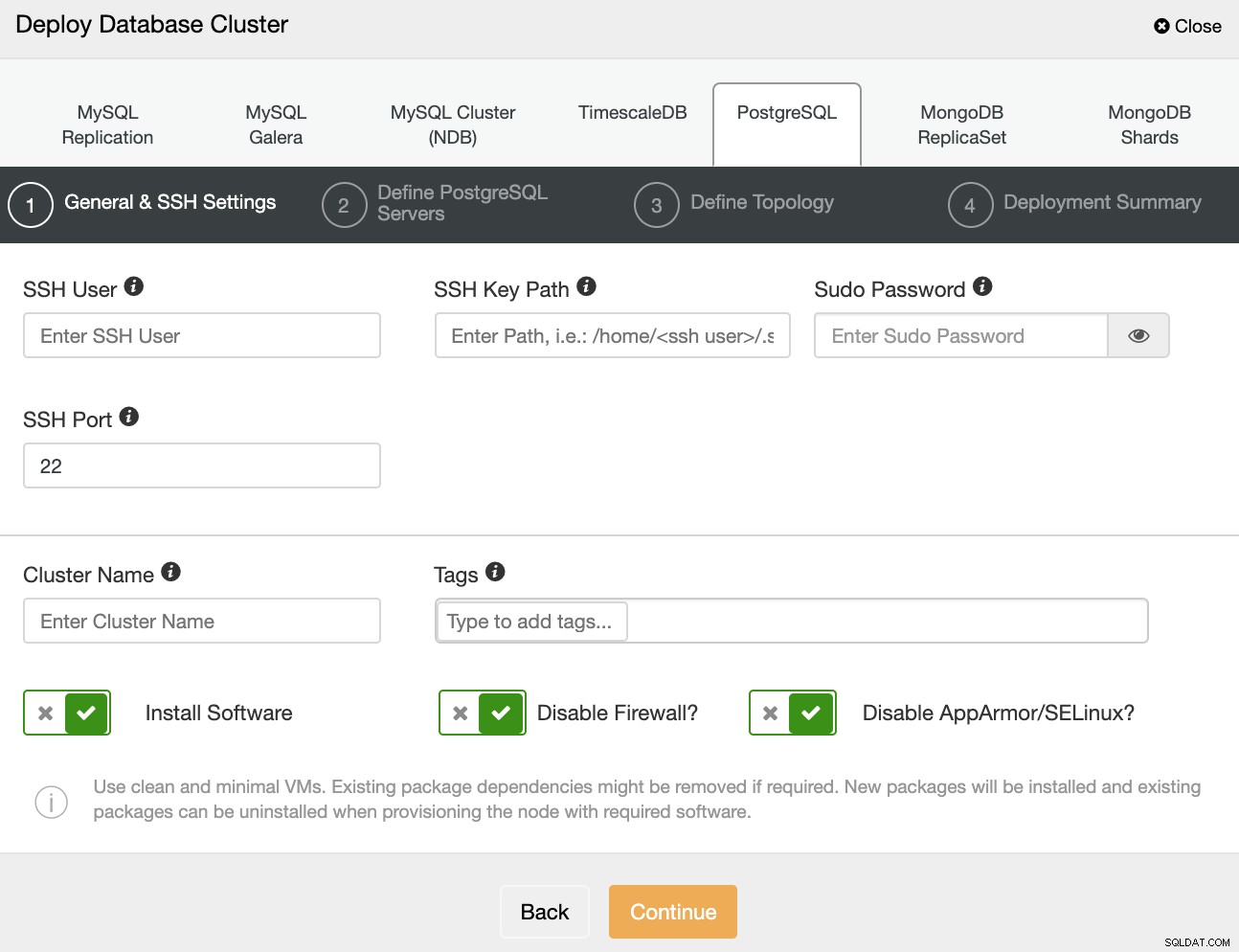
När du väljer PostgreSQL måste du ange Användare, Nyckel eller Lösenord och Port för att ansluta med SSH till dina servrar. Du kan också lägga till ett namn för ditt nya kluster och om du vill att ClusterControl ska installera motsvarande programvara och konfigurationer åt dig.
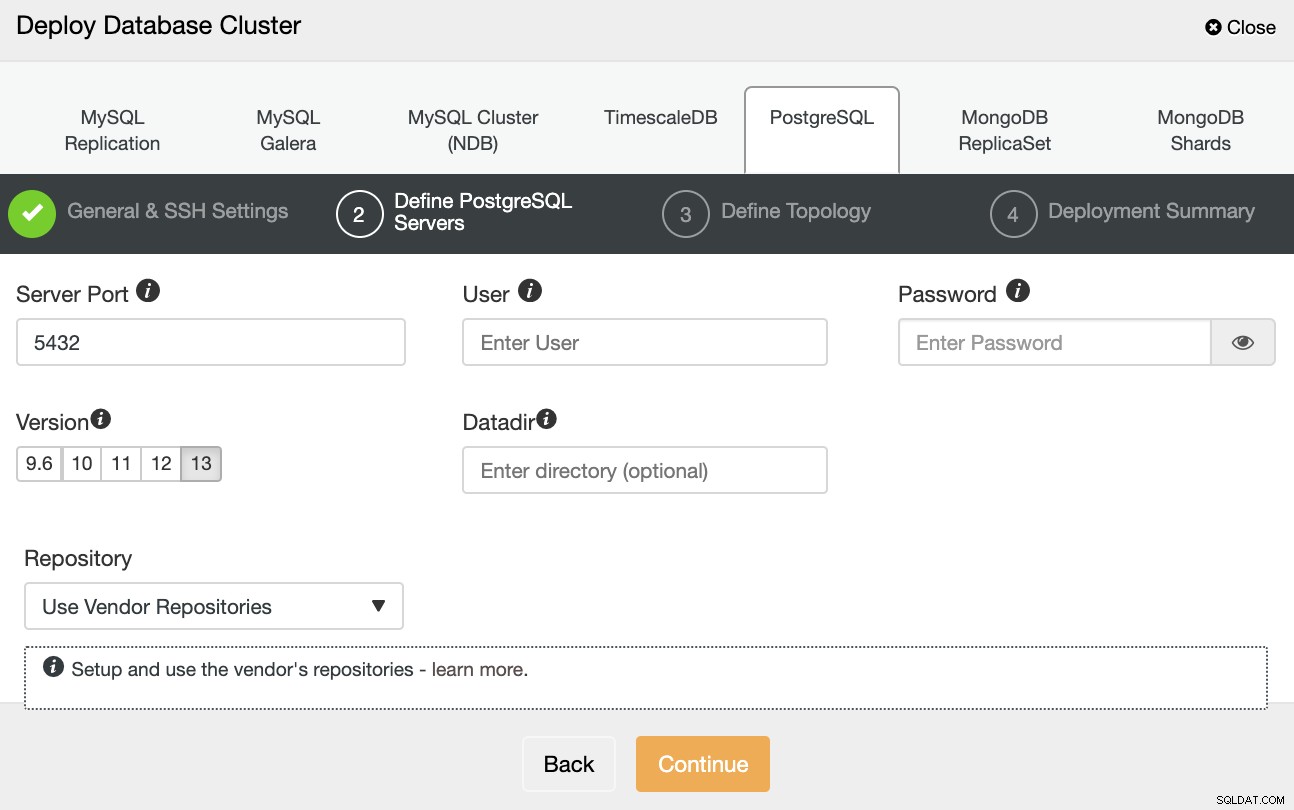
När du har ställt in SSH-åtkomstinformationen måste du definiera databasuppgifterna , version och datadir (valfritt). Du kan också ange vilket arkiv som ska användas.
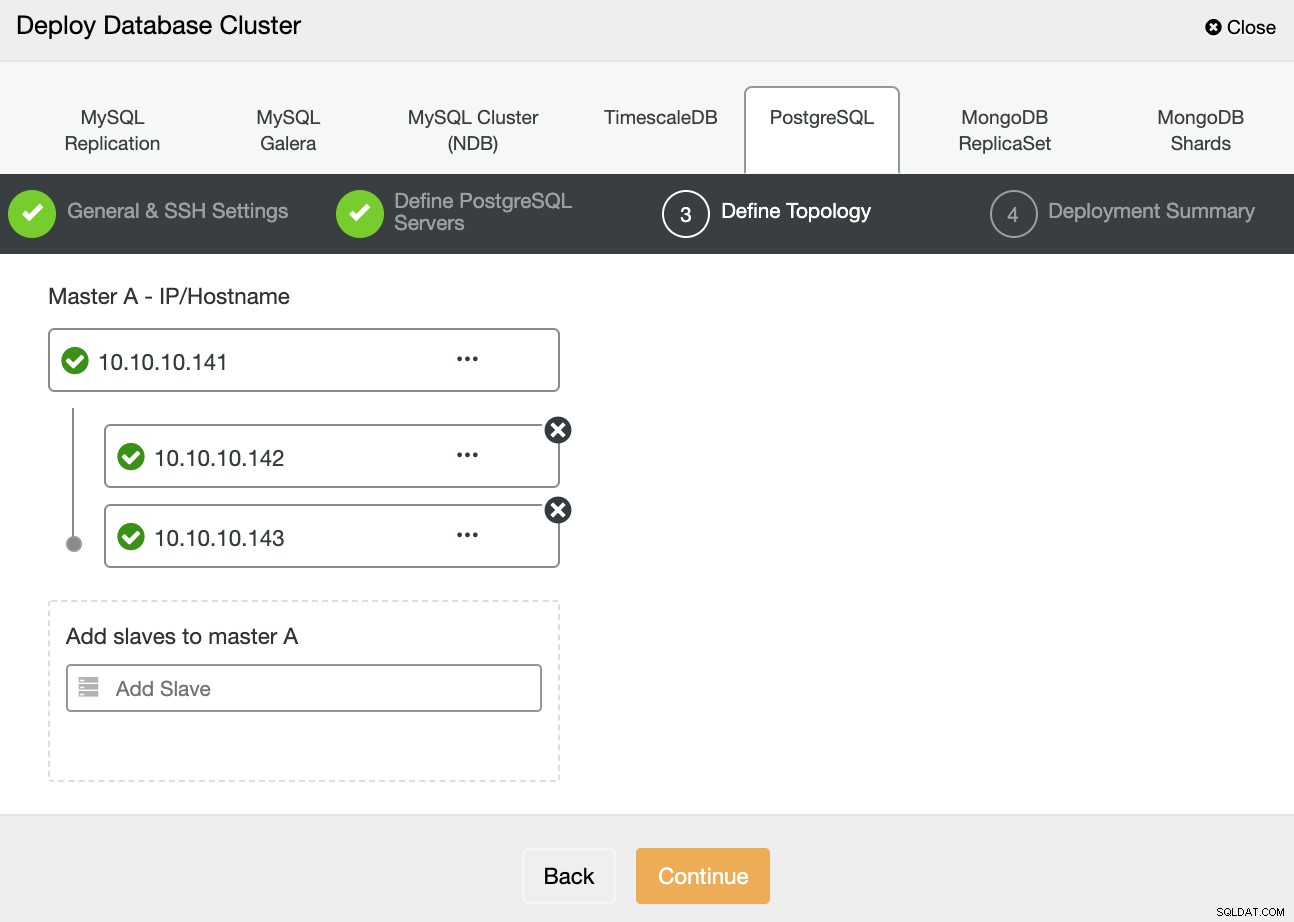
I nästa steg måste du lägga till dina servrar i klustret som du ska skapa med IP-adressen eller värdnamnet.
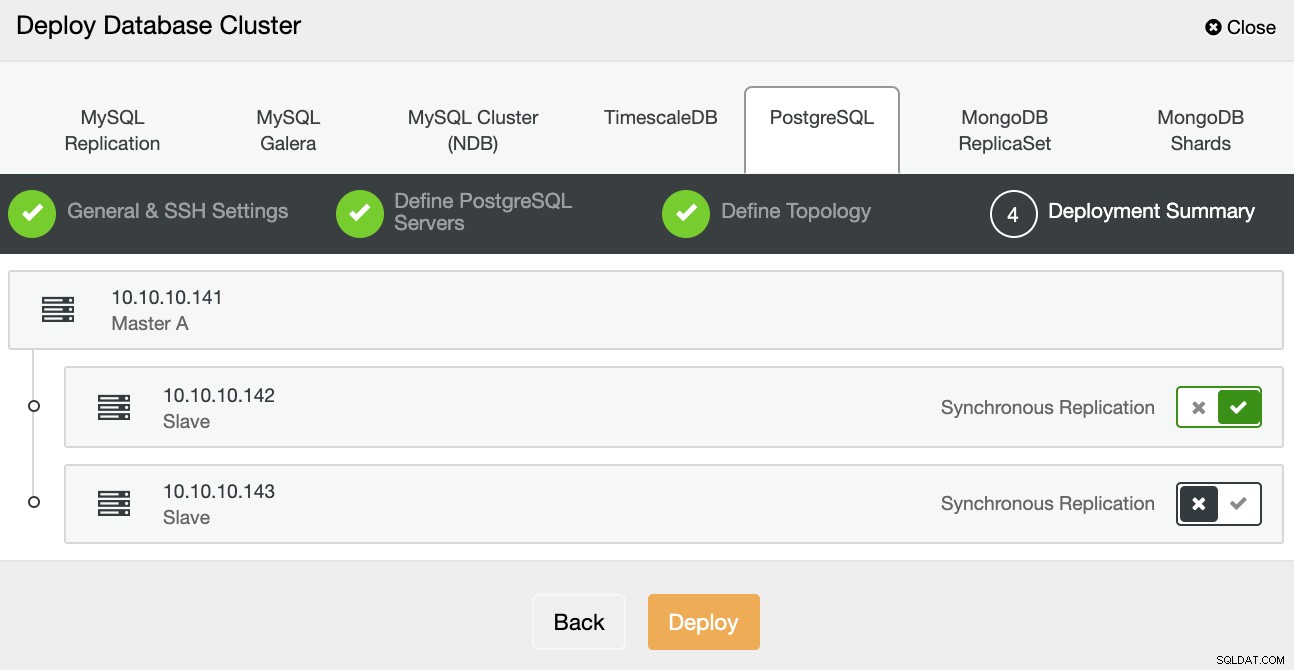
I det sista steget kan du välja om din replikering ska vara Synkron eller Asynkron, och tryck sedan bara på Deploy.
När uppgiften är klar kan du se ditt nya PostgreSQL-kluster i huvudskärmen för ClusterControl.

Nu har du skapat ditt kluster, du kan utföra flera uppgifter på det, som att lägga till lastbalanserare (HAProxy), anslutningspoolare (PgBouncer) eller nya replikeringsslavar från samma ClusterControl-gränssnitt.
Uppgraderar till PostgreSQL 13
Om du vill uppgradera din nuvarande PostgreSQL-version till denna nya, har du tre huvudalternativ som kommer att utföra denna uppgift.
-
Pg_dump:Det är ett logiskt säkerhetskopieringsverktyg som låter dig dumpa dina data och återställa dem i nya PostgreSQL version. Här kommer du att ha en stilleståndsperiod som kommer att variera beroende på din datastorlek. Du måste stoppa systemet eller undvika ny data i den primära noden, köra pg_dump, flytta den genererade dumpen till den nya databasnoden och återställa den. Under denna tid kan du inte skriva in i din primära PostgreSQL-databas för att undvika datainkonsekvens.
-
Pg_upgrade:Det är ett PostgreSQL-verktyg för att uppgradera din PostgreSQL-version på plats. Det kan vara farligt i en produktionsmiljö och vi rekommenderar inte den här metoden i så fall. Om du använder den här metoden kommer du också ha driftstopp, men förmodligen kommer det att vara betydligt mindre än med den tidigare pg_dump-metoden.
-
Logisk replikering:Sedan PostgreSQL 10 kan du använda denna replikeringsmetod som låter dig utföra större versionsuppgraderingar med noll (eller nästan noll) stilleståndstid. På så sätt kan du lägga till en standby-nod i den senaste PostgreSQL-versionen, och när replikeringen är uppdaterad kan du utföra en failover-process för att främja den nya PostgreSQL-noden.
För mer detaljerad information om de nya PostgreSQL 13-funktionerna kan du se den officiella dokumentationen.